
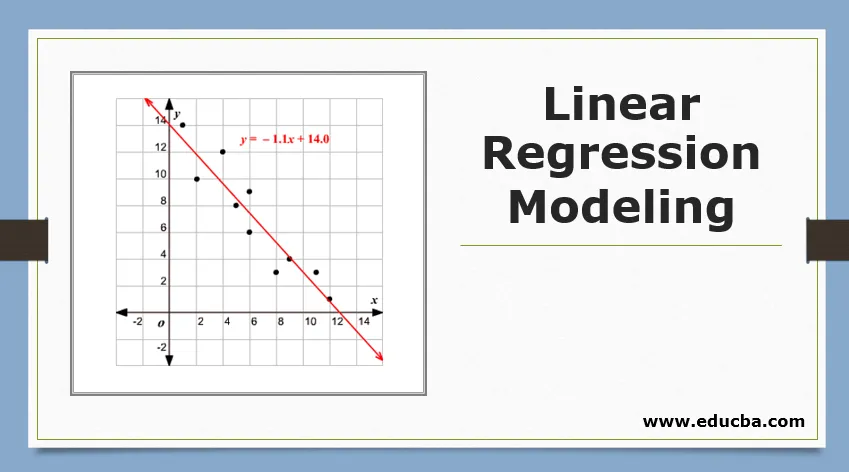
Преглед на линейно регресионно моделиране
Когато започнете да изучавате алгоритми за машинно обучение, започвате да научавате за различни начини на алгоритмите на ML, т.е. контролирано, неподдържано, полу-контролирано и усилено обучение. В тази статия ще се занимаваме с контролирано обучение и един от основните, но мощни алгоритми: Линейна регресия.

Следователно, контролираното обучение е обучението, при което обучаваме машината да разбира връзката между входните и изходните стойности, предоставени в набора от тренировъчни данни, а след това използваме същия модел за прогнозиране на изходните стойности за тествания набор от данни. Така че, по принцип, ако вече имаме предоставен изход или етикетиране в набора ни от данни за обучение и сме сигурни, че предоставеният резултат има смисъл, съответстващ на вложените данни, тогава използваме контролирано обучение. Алгоритмите за контролирано обучение се класифицират в регресия и класификация.
Регресионните алгоритми се използват, когато забележите, че изходът е непрекъсната променлива, докато алгоритмите за класификация се използват, когато изходът е разделен на секции като Pass / Fail, Good / Average / Bad и др. Имаме различни алгоритми за извършване на регресия или класификация действия с алгоритъм на линейна регресия като основен алгоритъм в регресията.
Стигайки до тази регресия, преди да вляза в алгоритъма, позволете ми да определя основата за вас. В училището се надявам да запомните концепцията за уравнение на линия. Нека да дам кратка информация за това. Бяха ви дадени две точки в равнината на XY, т.е. кажете (x1, y1) и (x2, y2), където y1 е изходът на x1, а y2 е изходът на x2, тогава уравнението на линията, което преминава през точките, е (y- y1) = m (x-x1), където m е наклонът на линията. Сега, след като намерите уравнението на линията, ако ви е дадено точка да кажете (x3, y3), тогава лесно бихте могли да предвидите дали точката лежи на линията или разстоянието на точката от линията. Това беше основната регресия, която направих в училище, без дори да осъзнавам, че това ще има толкова голямо значение в машинното обучение. Това, което обикновено правим в това, е да се опитаме да идентифицираме линията на уравнение или кривата, която би могла да пасне правилно на входа и изхода на набора от влакови данни и след това използвайте същото уравнение, за да прогнозирате изходната стойност на тестовия набор от данни. Това би довело до непрекъсната желана стойност.
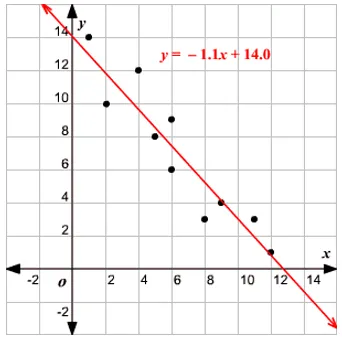
Определение на линейна регресия
Линейната регресия всъщност съществува от много дълго време (около 200 години). Това е линеен модел, т.е. предполага линейна връзка между входните променливи (x) и единична изходна променлива (y). Y тук се изчислява от линейната комбинация на входните променливи.
Имаме два вида линейна регресия
Проста линейна регресия
Когато има единична входна променлива, т.е. уравнението на линията е c
считан за y = mx + c, тогава това е проста линейна регресия.
Множествена линейна регресия
Когато има множество входни променливи, т.е. уравнението на линията се счита за y = ax 1 + bx 2 + … nx n, тогава това е множествена линейна регресия. Използват се различни техники за подготовка или трениране на уравнението на регресия от данни и най-често срещаното сред тях се нарича Обикновени най-малки квадрати. Моделът, изграден по споменатия метод, се обозначава като обикновена най-малка квадратура линейна регресия или просто най-малка квадратура. Моделът се използва, когато входните стойности и изходната стойност, която се определя, са цифрови стойности. Когато има само един вход и един изход, тогава образуваното уравнение е право уравнение, т.е.
y = B0x+B1
където коефициентите на линията се определят чрез статистически методи.
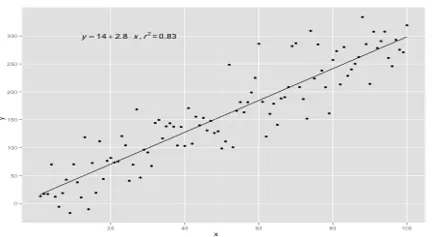
Моделите на обикновена линейна регресия са много редки при ML, защото като цяло ще имаме различни входни фактори, за да определим резултата. Когато има множество входни стойности и една изходна стойност, тогава формираното уравнение е равнина или хиперплоскост.
y = ax 1 +bx 2 +…nx n
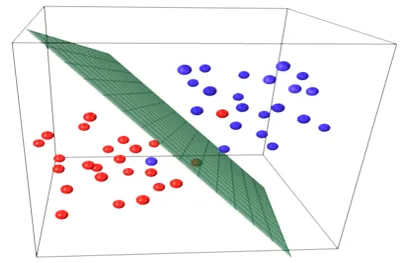
Основната идея в регресионния модел е да се получи линейно уравнение, което най-добре отговаря на данните. Най-подходящата линия е тази, при която общата грешка на прогнозиране за всички точки от данни, считани за възможно най-малки. Грешката е разстоянието между точката в равнината до регресионната линия.
пример
Нека започнем с пример за проста линейна регресия.

Връзката между ръста и теглото на човек е пряко пропорционална. Проведено е проучване върху доброволците за определяне на ръста и идеалното тегло на човека и стойностите са записани. Това ще се счита за нашия набор от данни за обучение. Използвайки данните от обучението, се изчислява уравнение на регресионната линия, което ще даде минимална грешка. Това линейно уравнение след това се използва за прогнозиране на нови данни. Тоест, ако дадем ръста на човека, тогава съответното тегло трябва да бъде предвидено от модела, разработен от нас с минимална или нулева грешка.
Y(pred) = b0 + b1*x
Стойностите b0 и b1 трябва да бъдат избрани така, че да сведат до минимум грешката. Ако сумата от квадратна грешка е взета като показател за оценка на модела, тогава целта за получаване на линия, която най-добре намалява грешката.
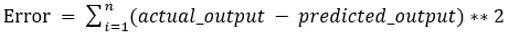
Изравняваме грешката, за да не се отменят положителните и отрицателните стойности. За модел с един предиктор:
Изчисляването на Intercept (b0) в уравнението на линията се извършва чрез:
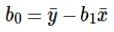
Изчисляването на коефициента за входната стойност x се извършва чрез:
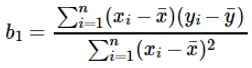
Разбиране на коефициента b 1 :
- Ако b 1 > 0, тогава x (вход) и y (изход) са пряко пропорционални. Това е увеличение на x ще се увеличи y като увеличаване на височината, увеличаване на теглото.
- Ако b 1 <0, тогава x (предиктор) и y (цел) са обратно пропорционални. Това е увеличение на x ще намалее y като скоростта на превозното средство се увеличава, времето се взима.
Разбиране на коефициента b 0 :
- B 0 заема остатъчната стойност за модела и гарантира, че прогнозата не е предубедена. Ако нямаме B 0 термин, уравнението на линията (y = B 1 x) е принудено да премине през произход, т.е. стойностите на входа и изхода, поставени в модела, водят до 0. Но това никога няма да бъде така, ако имаме 0 при въвеждане, тогава B 0 ще бъде средно на всички прогнозирани стойности, когато x = 0. Поставянето на всички стойности на прогноза на 0 в случай на х = 0 ще доведе до загуба на данни и често е невъзможно.
Освен посочените по-горе коефициенти, този модел може да се изчисли и с помощта на нормални уравнения. Ще обсъдя по-нататък използването на нормални уравнения и проектирането на прост / многолинеен регресионен модел в предстоящата ми статия.
Препоръчителни статии
Това е ръководство за линейно регресионно моделиране. Тук обсъждаме дефиницията, типовете линейна регресия, която включва проста и множествена линейна регресия, заедно с някои примери. Можете също да разгледате следните статии, за да научите повече -
- Линейна регресия в R
- Линейна регресия в Excel
- Предсказуемо моделиране
- Как да създадете GLM в R?
- Сравнение на линейна регресия с логистична регресия