

Въведение в DataFrame на Python Pandas
Множество разширения за Python Library, Pandas, могат да бъдат намерени онлайн. Една такава е данните на панела (тигана) (das). Тази дума * Панел * тънко намеква за двуизмерна структура на данни, присъстваща в тази библиотека, безкрайно овластяваща своите потребители. Тази сама структура се нарича DataFrame.
Това е по същество матрица от редове и колони, съдържаща целия ви набор от данни, с много сложни опции за индексиране на същото. DataFrame (DF), може да се представи изобразително много подобно на лист на excel. Но това, което го прави мощен, е лекотата, с която могат да се извършват аналитични и трансформационни операции върху данните, съхранявани в DataFrame.
Какво точно представлява DataFrame на Python Pandas?
Страницата на Pydata може да бъде отнесена за нещо с официална дефиниция.
Ако се разбере правилно, той споменава DataFrame като колонна структура, способна да съхранява всеки python обект (включително самия DataFrame) като една стойност на клетката. (Клетката се индексира с помощта на уникална комбинация от ред и колони)
DataFrames се състои от три основни компонента: данни, редове и колони.
- Данни: Отнася се за действителните обекти / образувания, съхранявани в клетка в DataFrame и стойностите, представени от тези единици. Обектът е от всеки валиден тип данни на python, независимо дали е вграден или дефиниран от потребителя.
- Редове: Позоваванията, използвани за идентифициране (или индексиране) на определен набор от наблюдения от пълните данни, съхранявани в DataFrame, се наричат редове. Само за да стане ясно, той представлява използваните индекси, а не само данните в конкретно наблюдение.
- Колони: Референции, използвани за идентифициране (или индексиране) на набор от атрибути за всички наблюдения в DataFrame. Както в редовете, те се отнасят до индекса на колоните (или заглавките на колоните), а не само до данните в колоната.
Така че, без допълнително обожание, нека изпробваме някои начини за създаване на тези страхотно мощни структури.
Стъпки за създаване на Python Pandas DataFrames
Може да се създаде Python Pandas DataFrame с помощта на следното внедряване на код,
1. Импортиране на панди
За да създадете DataFrames, библиотеката на пандите трябва да бъде импортирана (тук няма изненада). Ще го импортираме с псевдоним pd, за да препращаме удобно обекти под модула.
Код:
import pandas as pd
2. Създаване на първия обект DataFrame
След като библиотеката се импортира, всички методи, функции и конструктори са достъпни във вашето работно пространство. Така че, нека опитаме да създадем ванилна DataFrame.
Код:
import pandas as pd
df = pd.DataFrame()
print(df)
изход:
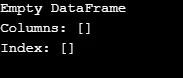
Както е показано в изхода, конструкторът връща празен DataFrame.
Нека сега се съсредоточим върху създаването на DataFrames от данни, съхранявани в някои от вероятните представи.
- DataFrame от речник: Да речем, че имаме речник, съхраняващ списък на компаниите в Software Domain и броя на годините, в които те са били активни.
Код:
import pandas as pd
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Infosys', 'Directi'),
'Age':('21', '23', '38', '22') ))
print (df)
Нека видим представянето на върнатия обект DataFrame, като го отпечатваме на конзолата.
изход:

Както се вижда, всеки ключ от речника се третира като колона в DataFrame и индексите на редовете се генерират автоматично, започвайки от 0. Доста лесно!
Нека сега да кажем, че сте искали да му дадете персонализиран индекс вместо 0, 1, .. 4. Просто трябва да предадете желания списък като параметър на конструктора и пандите ще направят необходимото.
Код:
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Yahoo', 'Infosys', 'Directi'),
'Age':('21', '23', '24', '38', '22') ),
index=('Alpha', 'Beta', 'Gamma', 'Delta'))
print(df)
изход:
Фирмена епоха
Alpha Google 21
Бета Амазонка 23
Gamma Infosys 38
Delta Directi 22
Сега можете да зададете индекси на редове до всяка желана стойност.
- DataFrame от CSV файл: Нека създадем CSV файл, съдържащ същите данни, както в случая на нашия речник. Нека се обадим на файла CompanyAge.csv
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
Файлът може да бъде зареден в рамка от данни (ако приемем, че присъства в текущата работна директория), както следва.
Код:
csv_df = pd.read_csv(
'CompanyAge.csv', names=('Company', 'Age'), header=None)
print(csv_df)
изход:
Фирмена епоха
0 Google 21
1 Амазонка 23
2 Infosys 38
3 Directi 22
Задаването на имената на параметрите , заобикаляйки списък със стойности, ги присвоява като заглавки на колони в същия ред, в който присъстват в списъка. По същия начин, индексите на редовете могат да бъдат зададени чрез предаване на списък на параметъра индекс, както е показано в предишния раздел. Заглавката = Няма посочва липсващи заглавки на колони във файла с данни.
Сега да кажем, че имената на колоните са били част от файла с данни. Тогава настройката header = False ще свърши необходимата работа.
3. CompanyAgeWithHeader.csv
Компания, възраст
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
Кодексът ще се промени на
csv_df = pd.read_csv(
'CompanyAgeWithHeader.csv', header=False)
print(csv_df)
изход:
Фирмена епоха
0 Google 21
1 Амазонка 23
2 Infosys 38
3 Directi 22
- DataFrame от файл в Excel: Често данните се споделят във excel файлове, тъй като остават най-популярният инструмент, използван от обикновените хора за проследяване на Adhoc. Затова не бива да се пренебрегва нашата дискусия.
Да приемем, че данните, същите като в CompanyAgeWithHeader.csv сега се съхраняват в CompanyAgeWithHeader.xlsx, в лист с името Company Age. Същият DataFrame както по-горе ще бъде създаден от следния код.
Код:
excel_df= pd.read_excel('CompanyAgeWithHeader.xlsx', sheet_name='CompanyAge')
print(excel_df)
изход:
Фирмена епоха
0 Google 21
1 Амазонка 23
2 Infosys 38
3 Directi 22
Както можете да видите, същият DataFrame може да бъде създаден чрез предаване на името на файла и името на листа.
По-нататъшно четене и следващи стъпки
Показаните методи представляват много малък подмножество в сравнение с всички различни начини, по които могат да бъдат създадени DataFrames. Те са създадени с намерение да започнат. Определено трябва да проучите изброените препратки и да опитате да проучите други начини, включително да се свържете с база данни, за да четете данни директно в DataFrame.
заключение
Pandas DataFrame се оказа, че е смяна на игри в света на Science Science и Data Analytics, както и е удобен за ad-hoc краткосрочни проекти. Той се предлага с армия от инструменти, способни да прерязват и изписват набора от данни с изключително лекота. Да се надяваме, че това ще послужи като стъпка в пътуването ви напред.
Препоръчителни статии
Това е ръководство за Python-Pandas DataFrame. Тук обсъждаме стъпките за създаване на python-pandas рамка от данни заедно с нейната реализация на код. Можете също да разгледате следните статии, за да научите повече -
- Топ 15 функции на Python
- Различни видове комплекти Python
- Топ 4 вида променливи в Python
- Топ 6 редактори на Python
- Масиви в структурата на данните