

Въведение в линеен регресионен анализ
Често е объркващо да научим някаква концепция, която дори е част от ежедневния ни живот. Но това не е проблем, ние можем да си помогнем и да се развием, за да се учим от ежедневните си дейности само като анализираме нещата и не се страхуваме да задаваме въпроси. Защо цената влияе върху търсенето на стоките, защо промяната на лихвата влияе върху предлагането на пари. На всичко това може да се отговори с прост подход, известен като линейна регресия. Единствената сложност, която човек изпитва, докато се занимава с линеен регресионен анализ, е идентифицирането на зависими и независими променливи.
Трябва да намерим какво влияе върху това и половината от проблема е решена. Трябва да видим дали цената или търсенето влияят на поведението един на друг. След като разбрахме коя е независимата променлива и зависима променлива, е добре да направим нашия анализ. Налични са множество видове регресионен анализ. Този анализ зависи от променливите, с които разполагаме.
3 вида регресионен анализ
Тези три регресионни анализа имат максимална употреба в реалния свят, в противен случай има повече от 15 вида регресионен анализ. Видовете регресионен анализ, които ще обсъдим, са:
- Линеен регресионен анализ
- Множествен линеен регресионен анализ
- Логистична регресия
В тази статия ще се съсредоточим върху простия линеен регресионен анализ. Този анализ ни помага да установим връзката между независимия фактор и зависимия фактор. С по-прости думи, регресионният модел ни помага да открием, че как промените в независимия фактор влияят на зависимия фактор. Този модел ни помага по няколко начина като:
- Това е прост и мощен статистически модел
- Той ще ни помогне да направим прогнози и прогнози
- Това ще ни помогне да вземем по-добро бизнес решение
- Това ще ни помогне да анализираме резултатите и да коригираме грешките
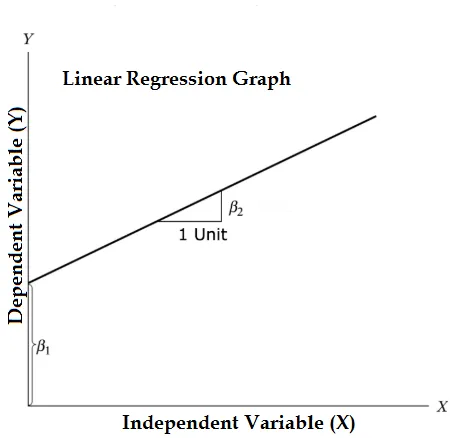
Уравнението на линейна регресия и се разделя на съответните части
Y = β1 + β2X + ϵ
- Където β1 в математическата терминология, известна като прихващане и β2 в математическата терминология, известна като наклон. Те са известни и като коефициенти на регресия. ϵ е терминът за грешка, той е част от Y, регресионният модел не е в състояние да обясни.
- Y е зависима променлива (други термини, които взаимозаменяемо се използват за зависими променливи, са променлива реакция, регресия и измерена променлива, наблюдавана променлива, отговаряща променлива, обяснена променлива, променлива резултат, експериментална променлива и / или изходна променлива).
- X е независима променлива (регресори, контролирана променлива, манипулирана променлива, обяснителна променлива, променлива експозиция и / или входна променлива).
Проблем: За да разберем какво е линеен регресионен анализ, ние вземаме набора от данни „Cars“, който по подразбиране идва в R директории. В този набор от данни има 50 наблюдения (основно редове) и 2 променливи (колони). Имената на колоните са „Dist“ и „Speed“. Тук трябва да видим въздействието върху променливите на разстоянието поради промяна на променливите на скоростта. За да видим структурата на данните, можем да пуснем код Str (набор от данни). Този код ни помага да разберем структурата на набора от данни. Тези функционалности ни помагат да вземаме по-добри решения, защото имаме по-добра представа за структурата на базата данни. Този код ни помага да идентифицираме типа набори от данни.
Код:

По подобен начин за проверка на статистическите контролни точки на набора от данни можем да използваме код Summary (автомобили). Този код предоставя среден, среден, диапазон на набора от данни в движение, който изследователят може да използва, докато се справя с проблема.
изход:
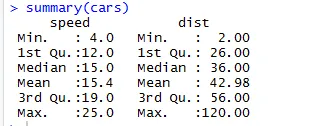
Тук можем да видим статистическата продукция на всяка променлива, която имаме в нашия набор от данни.
Графичното представяне на набори от данни
Видове графично представяне, които ще бъдат обхванати тук са и защо:
- Разпръскващ сюжет: С помощта на графиката можем да видим в каква посока върви нашия модел на линейна регресия, дали има някакви силни доказателства, които да доказват нашия модел или не.
- Сюжет на кутията: Помага ни да намерим външни хора.
- График на плътност: Помогнете ни да разберем разпределението на независимата променлива, в нашия случай независимата променлива е „Скорост“.
Предимства на графичното представяне
Тук са следните предимствата:
- Лесно за разбиране
- Помага ни да вземем бързо решение
- Сравнителен анализ
- По-малко усилия и време
1. Scatter Plot: Ще помогне за визуализиране на всякакви връзки между независимата променлива и зависимата променлива.
Код:

изход:
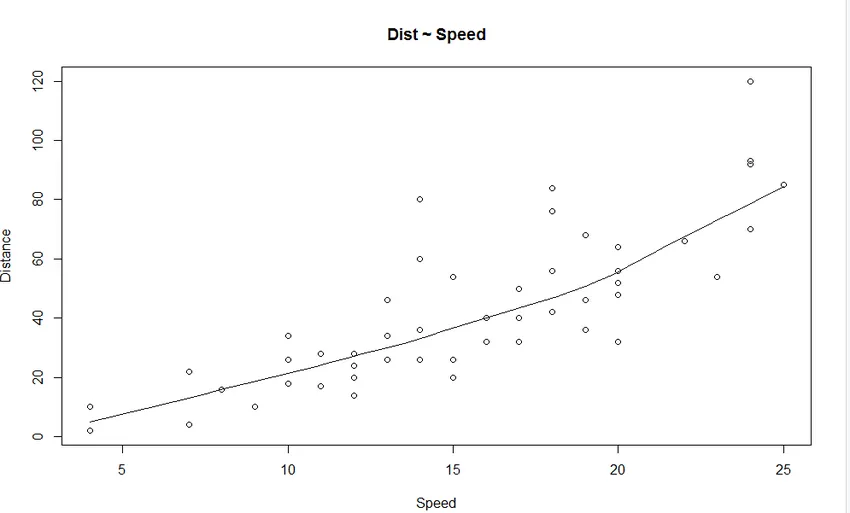
От графиката можем да видим линейно нарастваща връзка между зависимата променлива (Разстояние) и независимата променлива (Скорост).
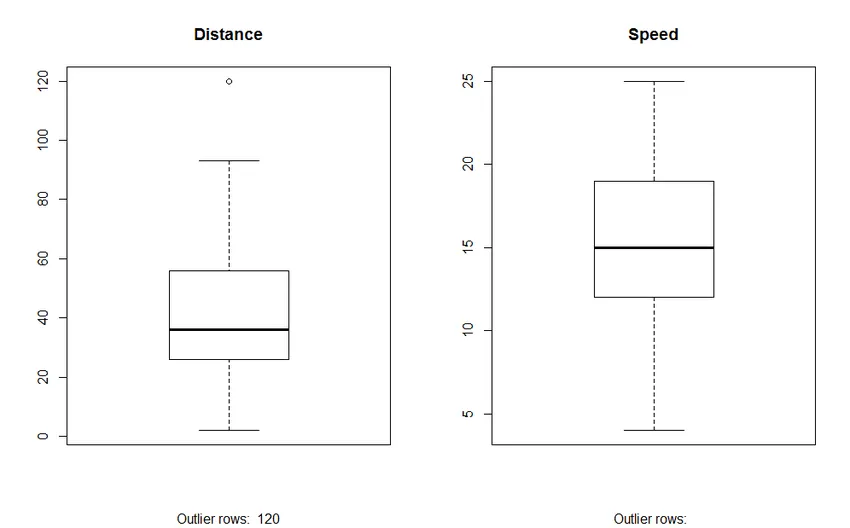
2. График на полето: Графиката на полето ни помага да идентифицираме екслигерите в наборите от данни. Предимства на използването на кутия сюжет са:
- Графично показване на местоположението и разпространението на променливите.
- Помага ни да разберем косостта и симетрията на данните.
Код:

изход:
3. График на плътност (за проверка на нормалността на разпределението)
Код:
 изход:
изход:
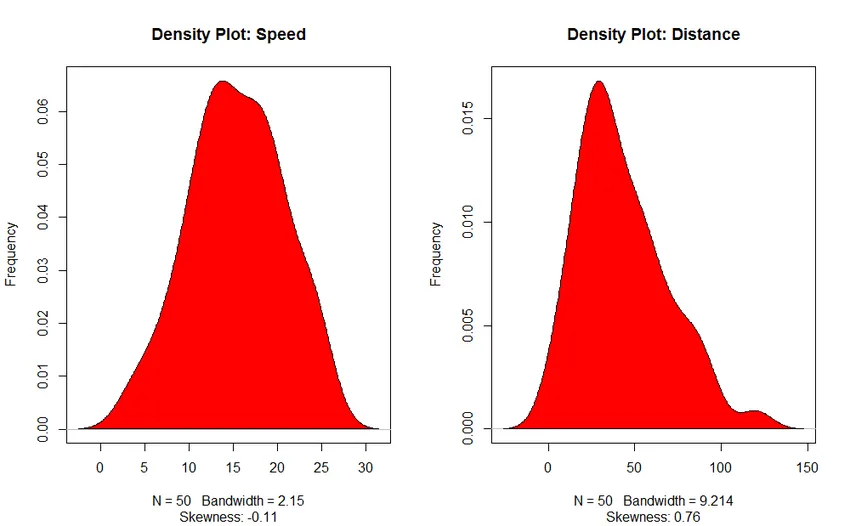
Корелационен анализ
Този анализ ни помага да намерим връзката между променливите. Съществуват главно шест вида корелационен анализ.
- Положителна корелация (0, 01 до 0, 99)
- Отрицателна корелация (-0, 99 до -0, 01)
- Няма корелация
- Перфектна корелация
- Силна корелация (стойност по-близка до ± 0, 99)
- Слаба корелация (стойност по-близка до 0)
Графикът на Scatter ни помага да идентифицираме кои видове набори от данни за корелация има сред тях и кодът за намиране на корелацията

изход:
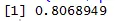
Тук имаме силна положителна връзка между скорост и разстояние, което означава, че те имат пряка връзка помежду им.
Линеен регресионен модел
Това е основният компонент на анализа, по-рано ние просто опитвахме и тествахме нещата дали наборът от данни е достатъчно логичен, за да стартираме такъв анализ или не. Функцията, която планираме да използваме, е lm (). Тази функция съдържа два елемента, които са формула и данни. Преди да присвоим, че коя променлива е зависима или независима, трябва да сме много сигурни в това, защото цялата ни формула зависи от това.
Формулата изглежда така,
Линейна регресия <- lm (зависима променлива ~ независима променлива, данни = дата. Рамка)
Код:

изход:
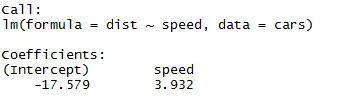
Както можем да си спомним от горния сегмент на статията, уравнението на линейна регресия е:
Y = β1 + β2X + ϵ
Сега ще се поберем в информацията, която получихме от горния код в това уравнение.
dist = −17.579 + 3.932 ∗ скорост
Само намирането на уравнението на линейна регресия не е достатъчно, трябва да проверим и неговата статистическа значимост. За това трябва да предадем код „Обобщение“ на нашия модел на линейна регресия.
Код:

изход:

Има няколко начина за проверка на статистическата значимост на модела, тук използваме метода P-стойност. Можем да считаме модел статистически подходящ, когато P-стойността е по-ниска от предварително определеното статистически значимо ниво, което в идеалния случай е 0, 05. Можем да видим в нашата обобщена таблица (linear_regression), че P-стойността е под 0, 05 ниво, така че можем да заключим, че нашият модел е статистически значим. След като сме сигурни в нашия модел, можем да използваме нашия набор от данни, за да прогнозираме нещата.
Препоръчителни статии
Това е ръководство за линеен регресионен анализ. Тук обсъждаме трите типа линеен регресионен анализ, графичното представяне на набори от данни с предимства и модели на линейна регресия. Можете също да разгледате и другите ни свързани статии, за да научите повече-
- Регресия формула
- Регресионно тестване
- Линейна регресия в R
- Видове техники за анализ на данни
- Какво е регресионен анализ?
- Основни разлики между регресия и класификация
- Топ 6 разлики между линейна регресия и логистична регресия