
Какво е линейна регресия в R?
Линейната регресия е най-популярният и широко използван алгоритъм в областта на статистиката и машинното обучение. Линейната регресия е техника за моделиране за разбиране на връзката между входните и изходните променливи. Тук променливите трябва да са цифрови. Линейната регресия идва от факта, че изходната променлива е линейна комбинация от входни променливи. Изходът обикновено се представя с „y“, докато входът е представен с „x“.
Линейната регресия в R може да бъде категоризирана по два начина
-
Si mple линейна регресия
Това е регресията, при която изходната променлива е функция на една входна променлива. Представяне на проста линейна регресия:
y = c0 + c1 * x1
-
Множествена линейна регресия
Това е регресията, при която изходната променлива е функция на променлива с няколко входа.
y = c0 + c1 * x1 + c2 * x2
И в двата случая по-горе c0, c1, c2 са коефициентът, който представлява регресионни тегла.
Линейна регресия в R
R е много мощен статистически инструмент. Така че нека да видим как може да се извърши линейна регресия в R и как могат да се интерпретират нейните изходни стойности.
Нека подготвим набор от данни, за да изпълним и разберем линейна регресия в дълбочина сега.
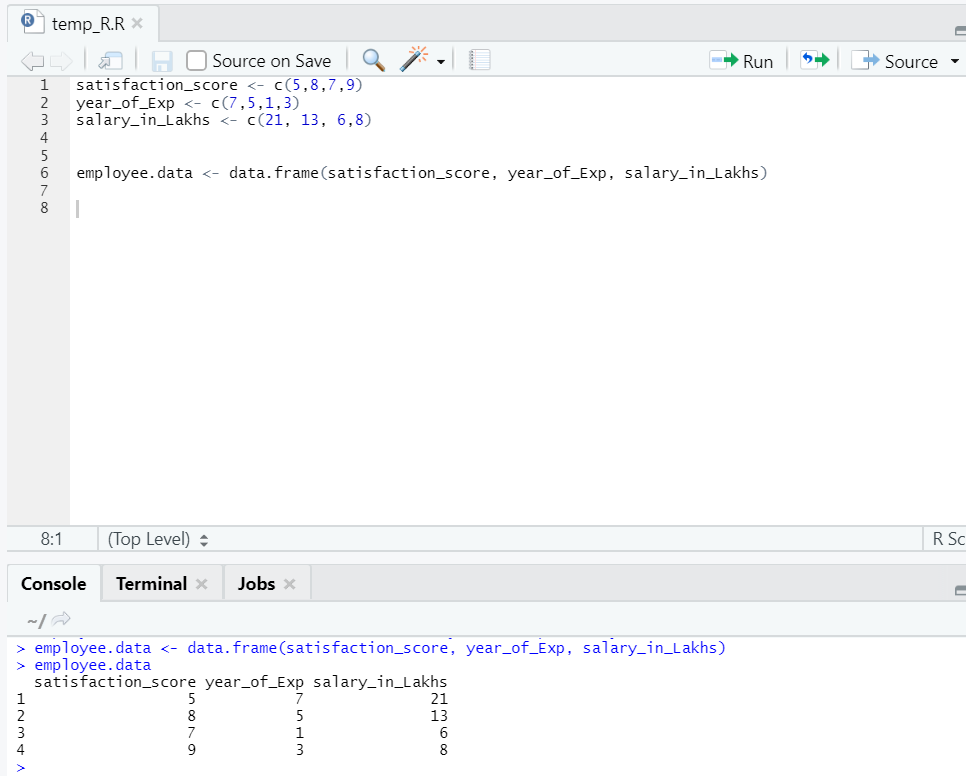
Сега имаме набор от данни, където „satis_score“ и „year_of_Exp“ са независимата променлива. „Зарплатата_в_лахи“ е променливата на изхода.
Позовавайки се на горния набор от данни, проблемът, който искаме да разрешим тук чрез линейна регресия, е:
Оценка на заплатата на служителя въз основа на годината му опит и оценка на удовлетвореността в неговата компания.
R код на линейна регресия:
model <- lm(salary_in_Lakhs ~ satisfaction_score + year_of_Exp, data = employee.data)
summary(model)
Изходът от горния код ще бъде:
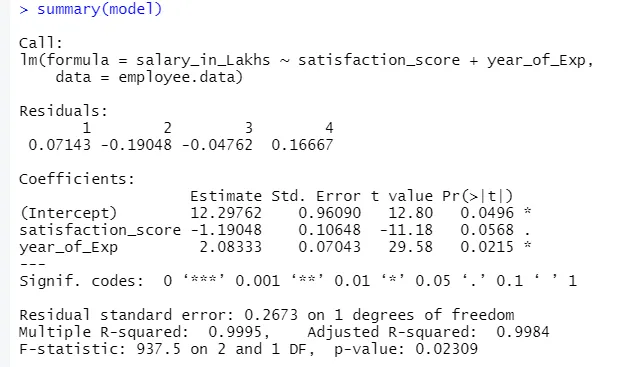
Формулата на Регресия става
Y = 12, 29-1, 19 * удовлетворение_скорец + 2, 08 × 2 * година_ от_Експ
В случай, че човек има няколко входа към модела.
Тогава R код може да бъде:
модел <- lm (plate_in_Lakhs ~., data = служител.данни)
Ако обаче някой иска да избере променлива от множествена входна променлива, съществуват множество техники като „Елиминиране назад“, „Избор напред“ и т.н., които също могат да направят това.
Интерпретация на линейна регресия в R
По-долу са дадени някои интерпретации на линейна регресия в r, които са както следва:
1.Residuals
Това се отнася до разликата между действителния отговор и прогнозирания отговор на модела. Така че за всяка точка ще има един реален отговор и един прогнозиран отговор. Следователно остатъците ще бъдат толкова, колкото и наблюденията. В нашия случай имаме четири наблюдения, следователно четири остатъка.

2.Coefficients
Отивайки по-нататък, ще намерим секцията за коефициентите, която изобразява прихващането и наклона. Ако човек иска да прогнозира заплатата на служителя въз основа на своя опит и удовлетвореност, трябва да разработи моделна формула, основана на наклона и прихващането. Тази формула ще ви помогне при прогнозиране на заплатата. Прехващането и наклона помагат на анализатора да излезе с най-добрия модел, който подходящо отговаря на точките с данни.
Наклон: изобразява стръмността на линията.
Прихващане: Мястото, където линията пресича оста.
Нека да разберем как се прави формирането на формули въз основа на наклон и прихващане.
Кажете, че прихващането е 3, а наклонът е 5.
И така, формулата е y = 3 + 5x . Това означава, ако x се увеличи с единица, y се увеличава с 5.
a.ефективност - оценка
При това прихващането означава средната стойност на изходната променлива, когато целият вход стане нула. Така че в нашия случай заплатата в lakhs ще бъде 12, 29Lakhs като средна предвид оценката на удовлетвореността и опитът е нулев. Тук наклонът представлява промяната на изходната променлива с единична промяна във входната променлива.
b.Кефициент - стандартна грешка
Стандартната грешка е оценката на грешката, която можем да получим при изчисляване на разликата между действителната и прогнозираната стойност на променливата ни за отговор. От своя страна това говори за доверието за свързване на променливи за вход и изход.
в. Коефициент - t стойност
Тази стойност дава увереността да отхвърли нулевата хипотеза. Колкото по-голяма е стойността извън нулата, толкова по-голяма е увереността да се отхвърли нулевата хипотеза и да се установи връзката между изходната и входната променлива. В нашия случай стойността също е от нула.
d.Coefficient - Pr (> t)
Този акроним основно изобразява p-стойността. Колкото по-близо е до нула, толкова по-лесно можем да отхвърлим нулевата хипотеза. Линията, която виждаме в нашия случай, тази стойност е близо до нула, можем да кажем, че съществува връзка между пакета за заплати, оценката на удовлетвореността и годината на опит.

Остатъчна стандартна грешка
Това изобразява грешката в прогнозирането на променливата на отговора. Колкото по-ниска е тя, толкова по-висока е точността на модела.
Множество R-квадрат, Регулиран R-квадрат
R-квадратът е много важна статистическа мярка за разбиране доколко близо данните са се вписали в модела. Следователно в нашия случай доколко нашият модел, който е линейна регресия, представя набора от данни.
Стойността на R-квадрат винаги е между 0 и 1. Формулата е:

Колкото по-близо е стойността до 1, толкова по-добре моделът описва наборите от данни и нейната дисперсия.
Въпреки това, когато повече от една входна променлива влиза в картината, коригираната стойност на R квадрат е предпочитана.
F-Статистика
Това е силна мярка за определяне на връзката между променлива вход и отговор. Колкото по-голяма е стойността от 1, толкова по-висока е увереността във връзката между входната и изходната променлива.
В нашия случай неговата „937.5“, което е сравнително по-голямо предвид размера на данните. Следователно отхвърлянето на нулевата хипотеза става по-лесно.
Ако някой иска да види интервала на достоверност за коефициентите на модела, ето начинът да го направи: -
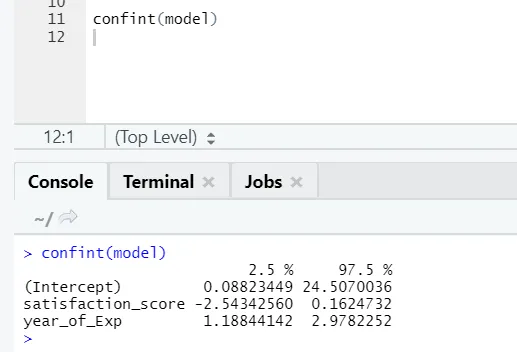
Визуализация на регресията
R код:
парцел (plate_in_Lakhs ~ удовлетвореност_score + година_of_Exp, данни = служител.данни)
abline (модел)
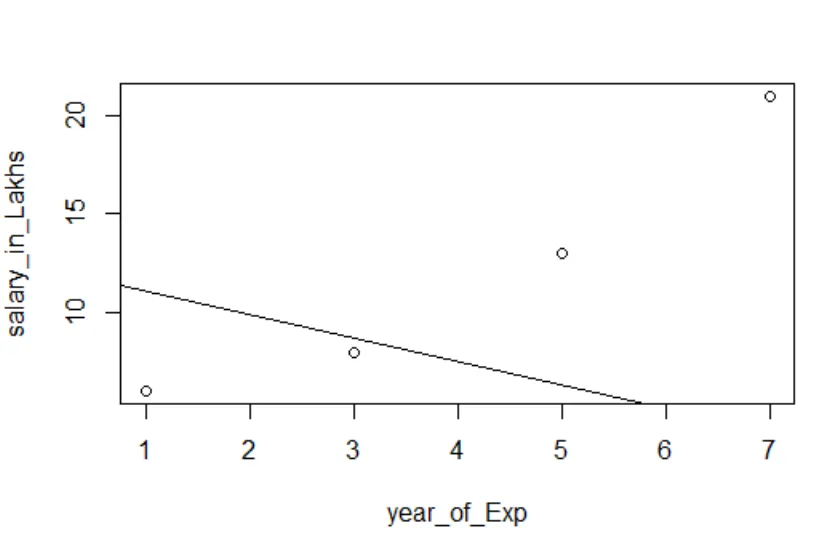
Винаги е по-добре да събирате все повече точки, преди да се монтирате на модел.
Заключение - Линейна регресия в R
Линейната регресия е проста, лесна за поставяне, лесна за разбиране, но много мощен модел. Видяхме как може да се извърши линейна регресия на R. Също така се опитахме да интерпретираме резултатите, което може да ви помогне в оптимизирането на модела. След като човек се чувства удобно с обикновена линейна регресия, трябва да опитате множествена линейна регресия. Заедно с това, тъй като линейната регресия е чувствителна към външните хора, човек трябва да погледне в нея, преди да скочи директно в приспособлението към линейна регресия.
Препоръчителни статии
Това е ръководство за линейна регресия в R. Тук сме обсъдили какво е линейна регресия в R? категоризация, визуализация и интерпретация на R. Можете също да прегледате и другите ни предложени статии, за да научите повече -
- Предсказуемо моделиране
- Логистична регресия в R
- Дърво на решения в R
- R Въпроси за интервю
- Основни разлики между регресия и класификация
- Ръководство за дървото на решенията в машинното обучение
- Линейна регресия срещу логистична регресия | Топ разлики