

Въведение в алгоритма на AdaBoost
Алгоритъмът AdaBoost може да се използва за повишаване на производителността на всеки алгоритъм за машинно обучение. Машинното обучение се превърна в мощен инструмент, който може да прави прогнози въз основа на голямо количество данни. Тя стана толкова популярна в последно време, че приложението на машинното обучение може да се намери в ежедневните ни дейности. Често срещан пример за това е получаване на предложения за продукти, докато пазарувате онлайн въз основа на предишните артикули, закупени от клиента. Машинното обучение, често наричано прогнозен анализ или прогнозиращо моделиране, може да бъде определено като способността на компютрите да учат, без да се програмират изрично. Той използва програмирани алгоритми за анализ на входните данни за прогнозиране на изхода в приемлив диапазон.
Какво е алгоритъм на AdaBoost?
При машинното обучение стимулирането възниква от въпроса дали набор от слаби класификатори може да бъде преобразуван в силен класификатор. Слабият ученик или класификатор е обучаем, който е по-добър от случайно познаване и това ще бъде стабилно в прекаленото напасване, както в голям набор от слаби класификатори, като всеки слаб класификатор е по-добър от случаен. Като слаб класификатор обикновено се използва обикновен праг за една характеристика. Ако характеристиката е над прага от предвиденото, тя принадлежи към положителна, в противен случай принадлежи на отрицателна.
AdaBoost означава „Адаптивно усилване“, което превръща слабите учащи се или прогнозите в силни прогнози, за да разреши проблемите с класификацията.
За класификация, крайното уравнение може да бъде поставено по-долу: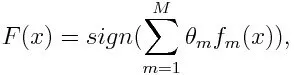
Тук f m обозначава m th слаб класификатор и m представлява съответното му тегло.
Как работи алгоритъмът AdaBoost?
AdaBoost може да се използва за подобряване на производителността на алгоритмите за машинно обучение. Използва се най-добре със слаби учащи се и тези модели постигат висока точност над случаен шанс при проблем с класификацията. Общите алгоритми с използваните AdaBoost са дървета на решения с първо ниво. Слабият ученик е класификатор или предиктор, който се представя сравнително слабо по отношение на точността. Също така може да се подразбира, че слабите учащи се изчисляват лесно и много случаи на алгоритми се комбинират, за да се създаде силен класификатор чрез усилване.
Ако вземем набор от данни, съдържащ n брой точки, и разгледайте по-долу
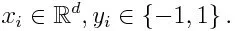
-1 представлява отрицателен клас, а 1 означават положителен. Инициализира се, както е посочено по-долу, теглото за всяка точка от данни като:
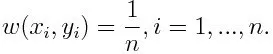
Ако разгледаме итерация от 1 до M за m, ще получим следния израз:
Първо, трябва да изберем слабия класификатор с най-ниската претеглена класификационна грешка, като монтираме слабите класификатори към набора от данни.
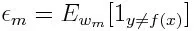
След това се изчислява теглото на м -тия слаб класификатор, както е посочено по-долу:
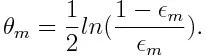
Теглото е положително за всеки класификатор с точност по-висока от 50%. Теглото става по-голямо, ако класификаторът е по-точен и става отрицателен, ако класификаторът има точност по-малка от 50%. Прогнозата може да се комбинира чрез обръщане на знака. Чрез обръщане на знака на прогнозата, класификатор с 40% точност може да бъде преобразуван в 60% точност. Така класификаторът допринася за крайното прогнозиране, въпреки че се представя по-лошо от случайното гадаене. Обаче окончателното прогнозиране няма да има никакъв принос или да получи информация от класификатора с точно 50% точност. Експоненциалният термин в числителя винаги е по-голям от 1 за неправилно класифициран случай от класификатора с положително претеглено значение. След итерация грешно класифицираните случаи се актуализират с по-големи тегла. Отрицателните претеглени класификатори се държат по същия начин. Но има разлика, че след като знакът е обърнат; правилните класификации първоначално биха се превърнали в неправилна класификация. Крайното прогнозиране може да се изчисли, като се вземе предвид всеки класификатор и след това се извърши сумата от тяхното претеглено прогнозиране.
Актуализиране на теглото за всяка точка от данни, както е посочено по-долу:
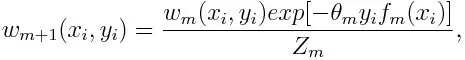
Z m е тук коефициентът на нормализиране. Той гарантира, че общата сума на всички тегла на инстанциите става равна на 1.
За какво се използва алгоритъмът AdaBoost?
AdaBoost може да се използва за разпознаване на лица, тъй като изглежда е стандартният алгоритъм за разпознаване на лица в изображения. Той използва каскада за отхвърляне, състояща се от много слоеве класификатори. Когато прозорецът за откриване не се разпознае на всеки слой като лице, той се отхвърля. Първият класификатор в прозореца изхвърля отрицателния прозорец, като свежда изчислителните разходи до минимум. Въпреки че AdaBoost комбинира слабите класификатори, принципите на AdaBoost се използват и за намиране на най-добрите функции, които да се използват във всеки слой от каскадата.
Плюсовете и минусите на алгоритма на AdaBoost
Едно от многото предимства на алгоритма на AdaBoost е, че е бързо, лесно и лесно да се програмира. Също така, той има гъвкавостта да се комбинира с всеки алгоритъм за машинно обучение и няма нужда от настройка на параметрите, с изключение на T. Той е разширен до проблеми с обучението извън двоичната класификация и е универсален, тъй като може да се използва с текст или цифров данни.
AdaBoost също има малко недостатъци, като е от емпирични доказателства и особено уязвим от равномерен шум. Слабите класификатори, които са твърде слаби, могат да доведат до ниски маржове и преоборудване.
Пример за алгоритъм на AdaBoost
Можем да разгледаме пример за приемане на студенти в университет, където или те ще бъдат приети или отказани. Тук количествените и качествените данни могат да бъдат намерени от различни аспекти. Например, резултатът от приема, който може да бъде да / не, може да бъде количествен, докато всяка друга област като умения или хобита на студентите може да бъде качествена. Можем да измислим лесно правилната класификация на данните за обучение при по-добра от възможността за условия, като например, ако студентът е добър в определен предмет, тогава той / той е приет. Но е трудно да се намери високо точна прогноза и тогава слабите учащи се появяват в картината.
заключение
AdaBoost помага при избора на набор за обучение за всеки нов класификатор, който се обучава въз основа на резултатите от предишния класификатор. Също така като комбинирате резултатите; той определя колко тегло трябва да се даде на предложения отговор на всеки класификатор. Той комбинира слабите учащи се, за да създаде силна за коригиране на грешки в класификацията, което е и първият успешен засилващ алгоритъм за проблеми с бинарна класификация.
Препоръчителни статии
Това е ръководство за алгоритма на AdaBoost. Тук обсъдихме с примера концепцията, употребите, работата, плюсовете и минусите. Можете да разгледате и другите ни предложени статии, за да научите повече -
- Наивен алгоритъм на Байес
- Въпроси за интервю за маркетинг на социални медии
- Стратегии за изграждане на връзки
- Платформа за маркетинг на социални медии