

Въведение в извличането на данни
Това е метод за извличане на данни, използван за поставяне на елементи от данни в техните подобни групи. Клъстерът е процедурата за разделяне на обекти на данни в подкласове. Качеството на клъстеризацията зависи от метода, който сме използвали. Клъстерирането се нарича също сегментиране на данни, тъй като големите групи данни са разделени по своята прилика.
Какво представлява групирането в извличането на данни?
Клъстерирането е групиране на конкретни обекти въз основа на техните характеристики и приликите им. Що се отнася до извличането на данни, тази методология разделя данните, които са най-подходящи за желания анализ, като се използва специален алгоритъм за присъединяване. Този анализ позволява на обект да не е част или строго част от клъстер, което се нарича твърд дял от този тип. Гладките дялове обаче предполагат, че всеки обект в една и съща степен принадлежи към клъстер. По-конкретни разделения могат да бъдат създадени като обекти от множество клъстери, един клъстер може да бъде принуден да участва или дори да се изграждат йерархични дървета в групови отношения. Тази файлова система може да бъде поставена по различни начини въз основа на различни модели. Тези Различни алгоритми се прилагат за всеки модел, като разграничават техните свойства, както и техните резултати. Един добър алгоритъм за клъстериране е в състояние да идентифицира клъстера, независимо от формата на клъстера. Има 3 основни етапа на алгоритъм за групиране, които са показани по-долу
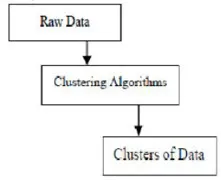
Клъстериране на алгоритми в обработката на данни
В зависимост от наскоро описаните модели на клъстери, много клъстери могат да се използват за разделяне на информация в набор от данни. Трябва да се каже, че всеки метод има своите предимства и недостатъци. Изборът на алгоритъм зависи от свойствата и естеството на набора от данни.
Методите за клъстеризиране на извличане на данни могат да бъдат показани по-долу
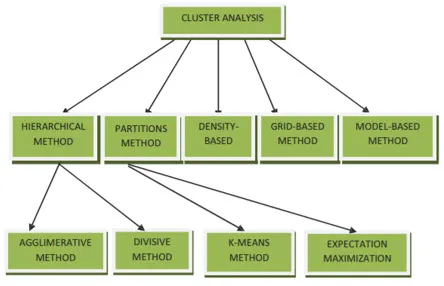
- Метод, базиран на разделяне
- Метод на базата на плътност
- Метод, базиран на центроиди
- Йерархичен метод
- Метод на основата на решетката
- Метод, основан на модела
1. Метод, базиран на разделяне
Алгоритъмът на дяла разделя данните на много подмножества.
Да приемем, че алгоритъмът на дяловете изгражда дял на данни, тъй като k и n е, че обектите присъстват в базата данни. Следователно всеки дял ще бъде представен като k ≤ n.
Това дава представа, че класификацията на данните е в k групи, което може да бъде показано по-долу
Фигура 1 показва оригиналните точки в групирането

Фигура 2 показва групиране на дялове след прилагане на алгоритъм
Това показва, че всяка група има поне един обект, както и всеки обект, трябва да принадлежи на точно една група.
2. Метод, основан на плътността
Тези алгоритми произвеждат клъстери на определено място въз основа на високата плътност на участниците в набора от данни. Той обобщава някакво понятие за обхвата на членовете на групата в клъстери до стандартно ниво на плътност. Такива процеси могат да се представят по-малко при откриване на повърхностните зони на групата.
3. Метод на базата на центроиди
Почти всеки клъстер е рефериран от вектор от стойности в този тип ос техника за групиране. В сравнение с други клъстери всеки обект е част от клъстера с минимална разлика в стойността. Броят на клъстерите трябва да бъде предварително дефиниран и това е най-големият проблем с алгоритъм от този тип. Тази методология е най-близка до предмета на идентификация и се използва широко за проблеми с оптимизацията.
4. Йерархичен метод
Методът ще създаде йерархично разлагане на даден набор от обекти на данни. Въз основа на това как се формира йерархичното разлагане, можем да класифицираме йерархични методи. Този метод е даден по следния начин
- Агломеративен подход
- Разделен подход
Агломеративният подход е известен още като подход с бутони. Тук започваме с всеки обект, който представлява отделна група. Той продължава да обединява обекти или групи, които са близо един до друг
Разделителният подход е известен още като подходът отгоре-надолу. Започваме с всички обекти в един и същ клъстер. Този метод е твърд, т.е. никога не може да бъде отменен, след като е завършен синтез или разделяне
5. Метод на основата на решетката
Grid-базирани методи работят в пространството на обекта, вместо да разделят данните в мрежа. Мрежата е разделена въз основа на характеристиките на данните. С помощта на този метод нечислените данни са лесни за управление. Редът на данни не засяга разделянето на мрежата. Важно предимство на мрежово базиран модел той осигурява по-голяма скорост на изпълнение.
Предимствата на йерархичното клъстериране са следните
- Той е приложим за всеки тип атрибут.
- Той осигурява гъвкавост, свързана с нивото на гранулиране.
6. Метод, основан на модела
Този метод използва хипотезиран модел, базиран на разпределението на вероятностите. Чрез обединяване на функцията за плътност, този метод локализира клъстерите. Той отразява пространственото разпределение на точките от данни.
Приложение на клъстеринга в Data Mining
Клъстеризирането може да помогне в много области като биология, растения и животни, класифицирани по техните свойства, както и в маркетинга. Клъстерирането ще помогне да се идентифицират клиентите на определен клиент с подобно поведение. В много приложения, като проучване на пазара, разпознаване на образи, обработка на данни и изображения, анализът на клъстеринг се използва в голям брой. Клъстерирането може също да помогне на рекламодателите в клиентската им база да намерят различни групи. И техните групи от клиенти могат да бъдат определени чрез закупуване на модели. В биологията се използва за определяне на растителни и животински таксономии, за категоризиране на гени с подобна функционалност и за вникване в присъщите на популацията структури. В базата данни за наблюдение на земята клъстерирането също така улеснява намирането на райони с подобно използване в земята. Той помага да се идентифицират групи от къщи и апартаменти по вид, стойност и местоназначение на къщите. Групирането на документи в интернет също е полезно за откриването на информация. Анализът на клъстерите е инструмент за придобиване на представа за разпределението на данни, за да се наблюдават характеристиките на всеки клъстер като функция за извличане на данни.
заключение
Клъстерирането е важно при извличането на данни и неговия анализ. В тази статия видяхме как клъстерирането може да се извърши чрез прилагане на различни алгоритми за клъстериране, както и приложението му в реалния живот.
Препоръчителен член
Това е ръководство за това какво е клъстеризиране в Data Mining. Тук обсъдихме концепциите, дефиницията, характеристиките, приложението на клъстеринга в Data Mining. Можете да разгледате и другите ни предложени статии, за да научите повече -
- Какво е обработка на данни?
- Как да станем анализатор на данни?
- Какво е SQL инжектиране?
- Дефиниция какво е SQL Server?
- Преглед на архитектурата за обработка на данни
- Клъстеризиране в машинно обучение
- Йерархичен алгоритъм на клъстериране
- Йерархично клъстериране | Агломеративно и разделно клъстеризиране