

Преглед на видовете клъстеризация
Преди да научим типове клъстеринг, нека разберем какво е клъстериране и защо е толкова важно в индустрията на машинно обучение в момента.
Какво е клъстеринг? Клъстерирането е процес, при който алгоритъмът разделя точките от данни в набор от групи въз основа на принципа, че подобни точки от данни остават близо една до друга и те попадат в една и съща група.
Защо сега е толкова важно? Нека разберем, че виждайки пример например, има онлайн магазин за облекла и те искат да разберат по-добре клиентите си, за да могат да направят стратегията си за рекламиране по-ефективна. Не е възможно те да имат уникален вид стратегия за всеки клиент, вместо това това, което могат да направят, е да разделят клиентите на определен брой групи (въз основа на техните предишни покупки) и да имат отделна стратегия на отделни групи. Това прави бизнеса по-ефективен, това е причината, поради която клъстерингът вече е важен в индустрията.
Видове клъстериране
Най-общо методите за клъстерни техники се класифицират в два вида, те са твърди методи и меки методи. При метода Hard clustering всяка точка от данни или наблюдение принадлежи само на един клъстер. При метода на меко клъстериране всяка точка от данни няма да принадлежи изцяло на един клъстер, вместо това може да бъде член на повече от един клъстер, той има набор от коефициенти на членство, съответстващи на вероятността да бъде в даден клъстер.
Понастоящем има различни видове методи за клъстериране, които се използват, тук в тази статия нека да видим някои от важните такива като йерархично клъстериране, дялово групиране, размито клъстериране, клъстериране на базата на плътност и клъстериране на базата на модел на разпространение. Сега нека обсъдим всеки един от тях с пример:
1. Клъстериране на дялове
Клъстерирането на дялове е вид клъстерна техника, която разделя набора от данни на определен брой групи. (Например стойността на K в KNN и ще бъде решено преди да обучим модела). Може да се нарече и като метод, базиран на центроид. При този подход клъстерният център (центроид) се формира така, че разстоянието на точките от данни в този клъстер е минимално, когато се изчислява с други клетъчни центроиди. Най-популярен пример за този алгоритъм е алгоритъмът KNN. Ето как изглежда алгоритъмът за клъстериране на дялове
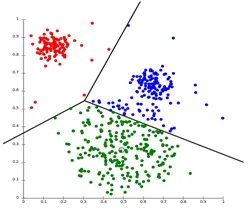
2. Йерархична клъстеризация
Йерархичното клъстериране е вид клъстерна техника, която разделя тези данни на няколко клъстера, където потребителят не посочва броя на клъстерите, които трябва да бъдат генерирани преди обучение на модела. Този тип клъстерна техника е известна още като методи, базирани на свързаност. При този метод простото разделяне на набора от данни няма да бъде направено, докато той ни осигурява йерархията на клъстерите, които се сливат помежду си след известно разстояние. След като йерархичното клъстериране се извърши върху набора от данни, резултатът ще бъде дърво базирано представяне на точки от данни (Dendogram), които са разделени на клъстери. Ето как изглежда йерархично клъстеризиране след приключване на обучението
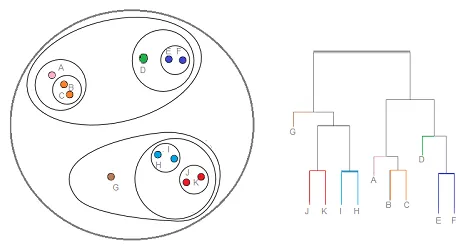
Връзка към източника: Йерархична клъстеризация
В клъстерирането на дялове и йерархичното клъстериране една основна разлика, която можем да забележим, е в клъстерирането на дялове, ние предварително ще уточним стойността на колко клъстери, на които искаме да бъде разделен наборът от данни, и не предварително уточняваме тази стойност в йерархичното клъстериране,
3. Клъстериране на базата на плътност
В това клъстеризиране, техническите клъстери ще се формират чрез сегрегация на различни области на плътност на базата на различни плътности в графиката на данните. Пространствено клъстериране и приложение с шум (DBSCAN) на базата на плътност е най-използваният алгоритъм в този тип техника. Основната идея зад този алгоритъм е, че трябва да има минимален брой точки, които съдържат в съседство на даден радиус за всяка точка в клъстера. Дотук в гореописаните техники за клъстериране, ако внимателно наблюдавате, можем да забележим едно общо нещо във всички техники, които са във формата на образувани клъстери, са сферични или овални или вдлъбнати. DBSCAN може да формира клъстери под различни форми, този тип алгоритъм е най-подходящ, когато наборът от данни съдържа шум или външни източници. Ето как изглежда алгоритъмът за пространствено клъстериране на базата на плътност след приключване на обучението.
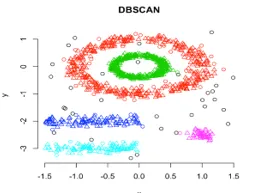
Връзка към източника: Клъстериране на базата на плътност
4. Клъстериране, основано на модела на разпространение
При този тип клъстеризиране, техническите клъстери се формират чрез идентифициране чрез вероятността всички точки от данни в клъстера да идват от едно и също разпределение (нормално, гаусско). Най-популярният алгоритъм в този тип техника е клъстериране на очаквания-максимизация (ЕМ), използвайки Gaussian Mixture Models (GMM).
Нормалните техники за клъстеризиране като йерархично клъстериране и клъстериране на дялове не се основават на официални модели, KNN при групиране на дялове дава различни резултати с различни K-стойности. Тъй като KNN и KMN считат средната стойност за центъра на клъстера, тя не е най-подходяща в някои случаи с Гаусови смесителни модели, ние предполагаме, че точките от данни са разпределени по Гаус, по този начин имаме два параметъра, за да опишем формата на средните клъстери и стандартното отклонение. По този начин за всеки клъстер се присвоява едно разпределение на Гаус, за да се получат оптималните стойности на тези параметри (средно и стандартно отклонение), се използва алгоритъм за оптимизация, наречен Maximization Expectation Maximization. Ето как изглежда EM - GMM след тренировка.
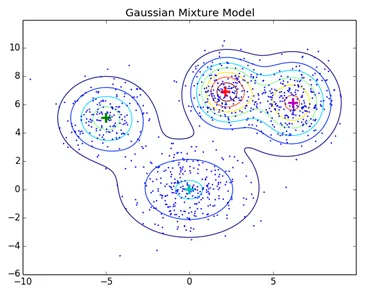
Източник Линк: Клъстериране, основано на модела на разпространение
5. Неясна клъстеризация
Принадлежи към клон от техники за клъстериране на меки методи, докато всички гореспоменати техники за клъстериране принадлежат към техники за клъстериране на твърди методи. При този тип клъстерни техники точки близо до центъра, може би част от другия клъстер в по-висока степен от точките в края на същия клъстер. Вероятността точка да принадлежи на даден клъстер е стойност, която лежи между 0 до 1. Най-популярният алгоритъм в този тип техника е FCM (Fuzzy C - алгоритъм на означава) Тук, центърът на клъстера се изчислява като средна стойност от всички точки, претеглени от вероятността им да принадлежат към клъстера.
Заключение - Видове клъстеризация
Това са някои от различните техники за клъстериране, които в момента се използват и в тази статия, ние покрихме по един популярен алгоритъм във всяка техника на клъстериране. Трябва да изберем вида технология, която използваме, въз основа на нашия набор от данни и изисквания, които трябва да изпълним.
Препоръчителни статии
Това е ръководство за Видовете клъстеринг. Тук обсъждаме различни видове клъстеринг с техните примери. Може да разгледате и следните статии, за да научите повече -
- Йерархичен алгоритъм на клъстериране
- Клъстеризиране в машинно обучение
- Видове алгоритми за машинно обучение
- Видове техники за анализ на данни
- Как да използвате и премахнете йерархията в Tableau?
- Пълно ръководство за видовете анализ на данните