
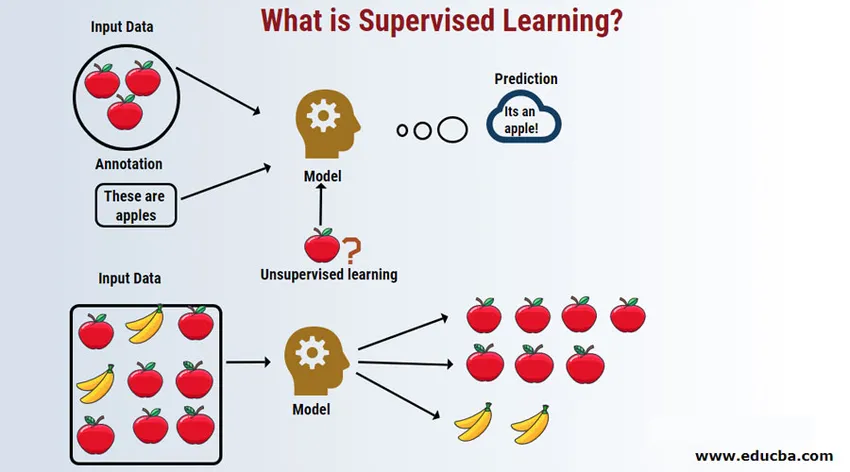
Въведение в контролираното обучение
Надзорното обучение е област на машинното обучение, в която работим за прогнозиране на стойностите, използвайки обозначени набори от данни. Маркираните входни набори от данни се наричат независима променлива, докато прогнозираните резултати се наричат зависима променлива, тъй като те зависят от независимата променлива за техните резултати. Например, всички имаме папка със спам в нашия имейл (например Gmail) акаунт, който автоматично открива повечето от спам / измама имейли за вас с точност над 95%. Тя работи на базата на контролиран модел на обучение, където имаме набор от обучения с етикетирани данни, който в случая е, обозначен със спам имейл, маркиран от потребителите. Тези учебни набори се използват за обучение, което по-късно ще се използва за категоризиране на новите имейли като спам, ако отговаря на категорията.
Работа по контролирано машинно обучение
Нека разберем контролираното машинно обучение с помощта на пример. Да речем, че имаме кошница с плодове, която е пълна с различни видове плодове. Нашата работа е да категоризираме плодовете въз основа на тяхната категория.
В нашия случай сме разгледали четири вида плодове и това са ябълка, банан, грозде и портокали.
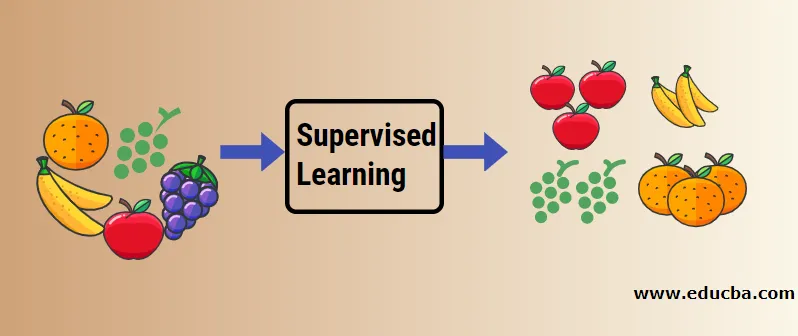
Сега ще се опитаме да споменем някои от уникалните характеристики на тези плодове, които ги правят уникални.
|
S No. | размер | цвят | форма |
Първо име |
|
1 | малък | зелен | Кръгла до овална, Букетна форма Цилиндрична |
Гроздов |
|
2 | голям | червен | Заоблена форма с депресия в горната част |
ябълка |
|
3 | голям | жълт | Дълъг извиващ се цилиндър |
банан |
| 4 | голям | оранжев | Заоблена форма |
оранжев |
Нека сега да кажем, че сте взели плод от кошницата с плодове, разгледали сте неговите характеристики, например неговата форма, размер и цвят, например, и след това заключите, че цветът на този плод е червен, големината, ако е голяма, формата е заоблена форма с депресия в горната част, следователно е ябълка.
- По същия начин правите същото и за всички останали плодове.
- Най-дясната колона („Име на плода“) е известна като променлива на отговора.
- Ето как формулираме модел за обучение, който се контролира, сега ще бъде доста лесно за всеки нов (да кажем, робот или извънземен) с зададени свойства лесно да групира един и същ вид плодове заедно.
Видове алгоритъм за контролирано машинно обучение
Нека видим различни видове алгоритми за машинно обучение:
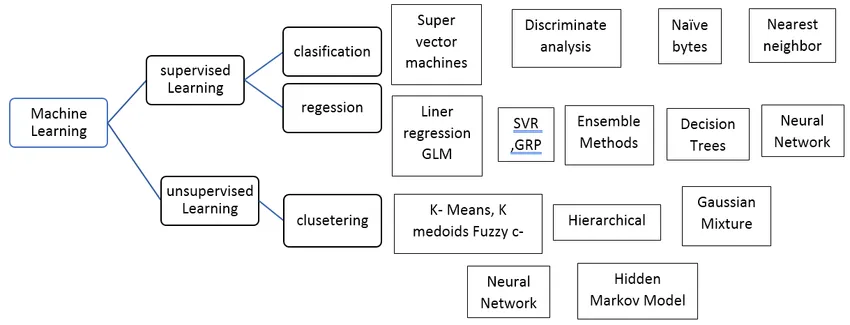
Регресия:
Регресията се използва за прогнозиране на единична стойност на изхода с помощта на набор от данни за обучение. Изходната стойност винаги се нарича като зависима променлива, докато входовете са известни като независима променлива. Имаме различни видове регресия в контролираното обучение, например,
- Линейна регресия - тук имаме само една независима променлива, която се използва за прогнозиране на изхода, т.е. зависима променлива.
- Множествена регресия - тук имаме повече от една независима променлива, която се използва за прогнозиране на изхода, т.е. зависимата променлива.
- Полиномна регресия - тук графиката между зависимите и независимите променливи следва полиномиална функция. Например, например, в началото паметта се увеличава с възрастта, след това достига праг на определена възраст, а след това започва да намалява с напредване на възрастта.
Класификация:
Класификацията на контролираните алгоритми за обучение се използва за групиране на подобни обекти в уникални класове.
- Бинарна класификация - Ако алгоритъмът се опитва да групира 2 отделни групи от класове, тогава той се нарича бинарна класификация.
- Класификация с много класове - Ако алгоритъмът се опитва да групира обекти в повече от 2 групи, тогава той се нарича мултикласова класификация.
- Сила - Алгоритмите за класификация обикновено се представят много добре.
- Недостатъци - Склонни са към свръхфитнес и може да са неограничени. Например - имейл класификатор за спам
- Логистична регресия / класификация - Когато променливата Y е двоична категорична (т.е. 0 или 1), използваме логистична регресия за прогнозиране. Например - Предсказване дали дадена транзакция с кредитна карта е измама или не.
- Naive Bayes Classifiers - Класификаторът Naive Bayes се основава на Байесовата теорема. Този алгоритъм обикновено е най-подходящ, когато размерът на входовете е голям. Състои се от ациклични графики, които имат един родител и много детски възли. Детските възли са независими един от друг.
- Дървета на решенията - дърво на решения е структура на дърво като структура, която се състои от вътрешен възел (тест за атрибут), клон, който обозначава резултата от теста и листните възли, който представлява разпределението на класовете. Коренният възел е най-горният възел. Това е много широко използвана техника, която се използва за класификация.
- Машина за поддръжка на вектора - Поддържаща машина е или SVM върши работата по класифицирането, като намира хиперплана, който трябва да увеличи максимално полето между 2 класа. Тези SVM машини са свързани към функциите на ядрото. Полетата, където SVMs се използват широко, са биометрия, разпознаване на образи и т.н.
Предимства
По-долу са някои от предимствата на контролираните модели за машинно обучение:
- Производителността на моделите може да бъде оптимизирана от потребителските преживявания.
- Контролираното обучение дава резултати, използвайки предишен опит, а също така ви позволява да събирате данни.
- Надзорните алгоритми за машинно обучение могат да се използват за прилагане на редица проблеми в реалния свят.
Недостатъци
Недостатъците на контролираното обучение са следните:
- Усилията за обучение на контролирани модели за машинно обучение могат да отнемат много време, ако наборът от данни е по-голям.
- Класификацията на големите данни понякога представлява по-голямо предизвикателство.
- Човек може да се наложи да се справи с проблемите на преоборудването.
- Имаме нужда от много добри примери, ако искаме моделът да се представи добре, докато тренираме класификатора.
Добри практики при изграждане на учебни модели
Добра практика е да се създават модели за контролирани учебни машини: -
- Преди да изградите добър модел на машинно обучение, трябва да се извърши процесът на предварителна обработка на данни.
- Човек трябва да реши алгоритъма, който трябва да е най-подходящ за даден проблем.
- Трябва да решим какъв тип данни ще се използват за обучителния набор.
- Необходимо е да се вземе решение относно структурата на алгоритъма и функцията.
заключение
В нашата статия научихме какво е контролирано обучение и видяхме, че тук тренираме модела, използвайки етикетирани данни. След това влязохме в работата на моделите и техните различни видове. Най-накрая видяхме предимствата и недостатъците на тези контролирани алгоритми за машинно обучение.
Препоръчителни статии
Това е ръководство за това какво е контролирано обучение ?. Тук обсъждаме концепциите, как работи, видове, предимства и недостатъци на контролираното обучение. Можете да разгледате и другите ни предложени статии, за да научите повече -
- Какво е дълбокото обучение
- Контролирано обучение срещу задълбочено обучение
- Какво е синхронизация в Java?
- Какво е уеб хостинг?
- Начини за създаване на дърво за решения с предимства
- Полиномна регресия | Употреби и функции