

Какво е Big Data и Hadoop?
Данните нарастват експоненциално всеки ден и с такива нарастващи данни идва необходимостта от използването на тези данни. Както в по-старите дни, ние използвахме флопи дискове за съхранение на данни и преносът на данни също беше бавен, но в наши дни те са недостатъчни и се използва облачно съхранение, тъй като имаме терабайти от данни. В днешния свят имаме социални медии, които допринасят най-много за растежа на данните. Състои се от поведение, мислене на хората и няколко други аспекта. Говори се, че във всяка минута 300 часа видео се качва в YouTube, над 20 милиона снимки се качват във Facebook и много други. Освен това няма подходяща структура на качваните данни, което е най-голямото предизвикателство за обработката на тези данни.
Тъй като се генерират огромни данни с висока скорост, традиционните RDBMS системи не успяха да се справят с такъв бърз растеж. Освен това те също не са в състояние да обработват неструктурирани данни. Стана много трудно да се борави с толкова голямо количество разнородни данни, които растат бързо, и да се обработват тези данни с висока скорост на обработка. Така възникна необходимост от такава система, която да е в състояние да борави с голям набор от данни. Следователно, за решаване на сценария Hadoop възникна. HDFS е компонентът на Hadoop, който се занимава с проблема със съхранението на големия набор от данни, като използва разпределено съхранение, докато YARN е компонентът, който се справи с проблема с обработката, като намали драстично времето за обработка.
Hadoop е софтуерна рамка с отворен код за съхранение и обработка на големи масиви данни, използвайки разпределен голям клъстер от хардуер. Той е разработен от Doug Cutting и Michael J. Cafarella и лицензиран под Apache. Той е написан с помощта на Java и е разработен въз основа на хартията, написана от Google в системата MapReduce и прилага концепции за функционално програмиране. Той е надежден, икономичен гъвкав и мащабируем.
Основните компоненти на Hadoop
Основните компоненти на Hadoop са както следва
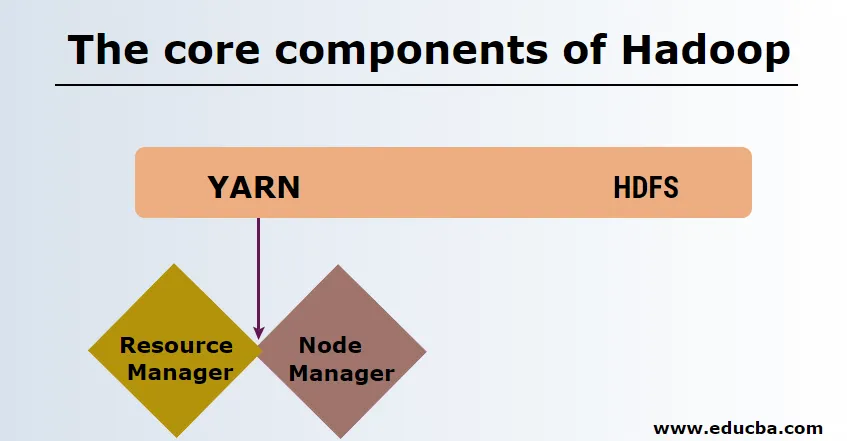
-
HDFS
HDFS или разпределената файлова система Hadoop имат Namenode и възел за данни. Namenode е основният възел, управляващ главния демон и управлява възлите на данни и следи всички операции. Датанодите са роби, в които действително се съхраняват данните.
-
прежди
Преждата се състои от два основни компонента:
1. ResourceManager: Той работи на главния възел и управлява всички ресурси и планира всички приложения. Той има Scheduler & ApplicationManager.
2. NodeManager: Той работи на всеки подчинен възел и е отговорен за управлението на контейнерите и мониторинга на използването на ресурсите.
Няколко компонента на Hadoop
Има няколко компонента на Hadoop като прасето, кошера, скуоп, флоума, махут, oozie, zookeeper, HBase и др.
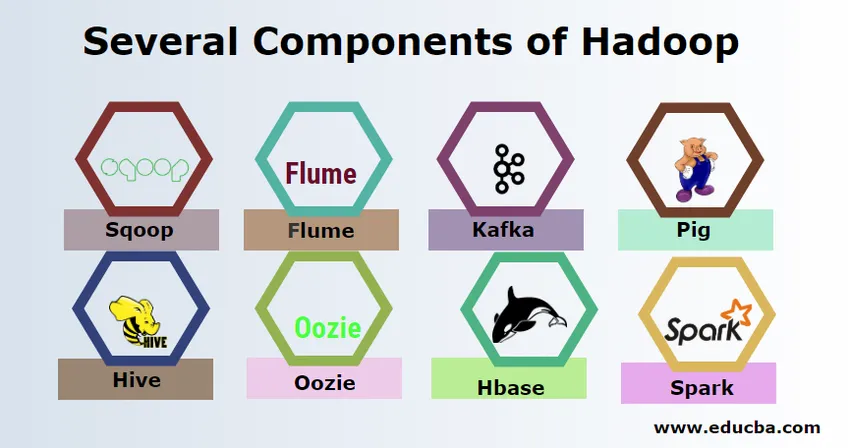
- Sqoop - Използва се за импортиране и експортиране на данни от RDBMS в Hadoop и обратно.
- Flume - Използва се за изтегляне на данни в реално време в Hadoop.
- Kafka - Това е система за съобщения, използвана за маршрутизиране на данни в реално време в Hadoop.
- Прасе - Използва се като скриптов език за обработка на данни.
- Hive - Това е рамка за съхранение на данни, изградена на HDFS, така че потребителите, запознати със SQL, могат да изпълняват заявки за получаване на данните. Тези заявки се наричат HiveQL.
- Oozie - Използва се за планиране на работния процес на задачите, които да се изпълняват на определени събития или време.
- Hbase - Това е не SQL база данни, предоставена като част от Apache Hadoop.
- Искра - Използва се за извършване на обработка в паметта, която е много по-бърза, отколкото намалява картата на Hadoop.
Hadoop доставчици
Има много компании, предлагащи дистрибуции на Hadoop. По-долу са няколко най-добрите доставчици за Hadoop:
- Cloudera
- Hortonworks
- MapR
Има малко предпоставки за изучаване на Hadoop. Необходим е предишен опит в Java и скриптов език. Въпреки че Hadoop вече има собствени езици за програмиране на високо ниво като прасе и кошер, който генерира резервния код за по-нататъшна обработка, все пак е възможно да се създаде собствена програма за намаляване на картата на всеки език за програмиране като Ruby, Python, Perl и дори C програмиране.
Bigdata и Hadoop са с голямо търсене на днешния пазар. Това ще нарасне повече в следващите дни. Много организации вече са се преместили в Hadoop, а тези, които не са се преместили скоро. Съществува актуален доклад, в който се посочва, че големите корпорации са започнали да инвестират в анализи на големи данни. Прогнозата за маркетинг на големи данни винаги е във възходяща тенденция и изобщо не е краткотрайно състояние. Освен всички тези работни места в Hadoop и големите данни винаги предлагат високо заплащане в сравнение с други технологии.
Най-големите компании за данни и Hadoop
По-долу са няколко топ компании, които използват най-много ресурси на Hadoop.
- Yahoo
- Амазонка
- Кралска банка на Шотландия
- British Airways
- Expedia
- Walmart
Има много компании, които използват приложения за големи данни. Това са:
-
Nokia
Той използва компоненти на Cloudera и Hadoop като HDFS, HBase, Sqoop, Scribe. Използва ефективно данните на потребителите, за да разбере и подобри практическата работа на потребителя. Използва обработка на данни и сложни анализи за изграждане на картата с предсказуем трафик и слоести модели на кота.
-
SAS
Той си сътрудничи с Hadoop, за да помогне на учените за данни да получат по-добра представа, като предоставя среда, която дава визуално и интерактивно преживяване, като по този начин помага да се изследват новите тенденции. Аналитичните програми извличат смислена информация от данни, а технологията в паметта помага за по-бърз достъп до данни.
Има и много други компании, които използват големи платформи за данни за различни анализи. Това са анализ на данните за полетите на черната кутия в авиационната индустрия, различният анализ на пазара на акции и др.
Предимства на Haddop
По-долу са някои от предимствата на Hadoop
- Мащабируемост - За разлика от традиционните RDBMS, това е много мащабируема платформа, тъй като може да съхранява големи набори от данни в разпределени клъстери върху хардуер, работещ паралелно.
- Ефективна цена - Цената е била твърде висока, за да може RDBMS да съхранява данни, които са облекчени в Hadoop.
- Бърз и гъвкав - Той предлага бърз достъп до данни през разпределената му файлова система. Той също така предлага да се извлекат бизнес информация от полуструктурирани и неструктурирани данни.
- Толерантни към грешки - Всеки път, когато дадени данни се изпращат на възел, същите данни се реплицират в други възли, до които може да се направи достъп в случай на повреда на първия възел.
Извод - какво е Big Data и Hadoop
Данните непрекъснато нарастват и следователно винаги ще има нужда от големи данни и Hadoop да извлече смисъл от тези данни. Поради тази причина професионалистите с умения на Hadoop винаги ще намерят широки възможности през следващите дни и могат да бъдат жизненоважно предимство за организация, стимулираща бизнеса и кариерата им.
Препоръчителни статии
Това е ръководство за това какво е Big Data и Hadoop. Тук сме обсъдили основните понятия и компоненти на големите данни и Hadoop. Можете също да разгледате следната статия, за да научите повече -
- Примери за големи анализи на данни
- Използване на Hadoop
- Ръководство за визуализация на данни
- Какво представлява анализа на големи данни?