

Преглед на приложенията на Kafka
Едно от тенденциите в областта на ИТ индустрията е Big Data, където компанията се занимава с голямо количество клиентски данни и извлича полезна информация, която помага на бизнеса им и предоставя на клиентите по-добро обслужване. Едно от предизвикателствата е да обработвате и прехвърляте тези големи обеми от данни от един край до друг за анализ или обработка, това е мястото, където Kafka (надеждна система за съобщения) влиза в играта, което помага за събирането и транспортирането на огромен обем данни в реално време. Kafka е проектиран за разпределени системи с висока пропускателна способност и е подходящ за широкомащабни приложения за обработка на съобщения. Kafka поддържа много от най-добрите търговски и индустриални приложения днес. Има търсене на професионалисти от Kafka, които имат силни умения и практически знания.
В тази статия ще научим за Kafka, нейните функции, случаи на използване и ще разберем някои забележителни приложения, където се използва.
Какво е Кафка?
Apache Kafka е разработен в LinkedIn и по-късно става проект с отворен код Apache. Apache Kafka е бърза, отказоустойчива, мащабируема и разпределена система за съобщения, която позволява комуникация между две субекти, т.е. между производители (генератор на съобщението) и потребители (получател на съобщението), използвайки теми, базирани на съобщения, и предоставя платформа за управление на всички данните в реално време.
Характеристиките, които правят Apache Kafka по-добър от другите системи за съобщения и приложими към системите в реално време, са неговата висока наличност, незабавно, автоматично възстановяване от повреди на възлите и поддържащо предаване на съобщения с ниска латентност. Тези функции на Apache Kafka помагат за интегрирането му с широкомащабни системи за данни и го правят идеален компонент за комуникация. 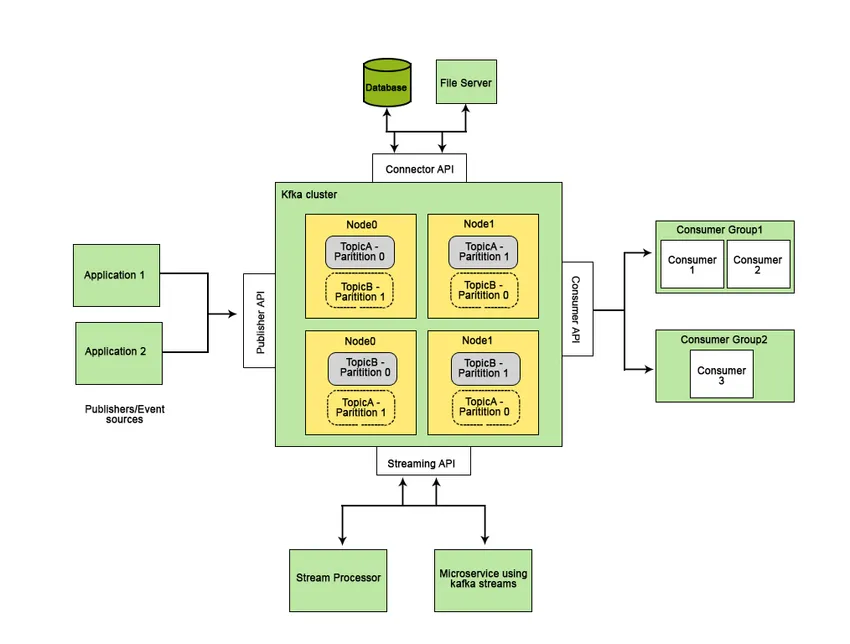
Най-добрите приложения на Kafka
В този раздел на статията ще видим някои популярни и широко прилагани случаи на употреба и ще видим някои реализации на Kafka в реалния живот.
Приложения в реалния живот
1. Twitter: Дейност по обработка на потока
Twitter е платформа за социални мрежи, която използва Storm-Kafka (инструмент за обработка на поток с отворен код) като част от тяхната инфраструктура за обработка на потоци, където входните данни (туитове) се консумират за събиране, преобразуване и обогатяване за по-нататъшно потребление или последващи действия дейности по обработка.
2. LinkedIn: обработка на потоци и показатели
LinkedIn използва Kafka за поточно предаване на данни и за оперативна метрика. LinkedIn използва Kafka за своите допълнителни функции като Newsfeed за консумация на съобщения и извършване на анализ на получените данни.
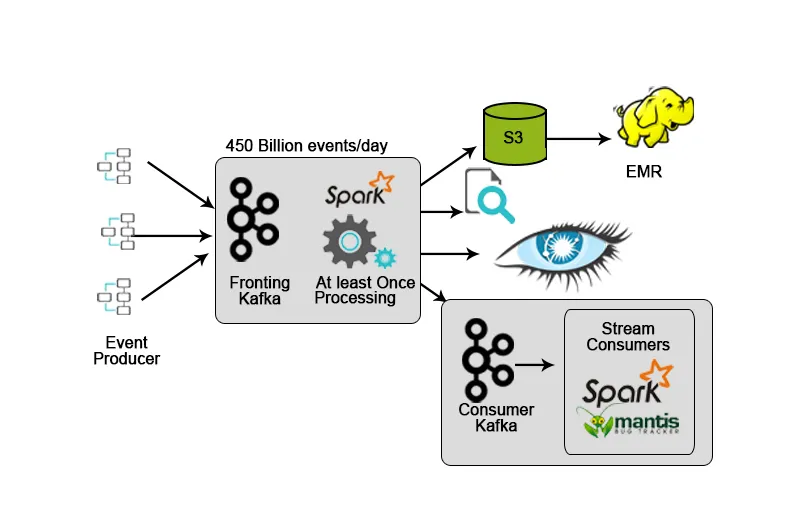
3. Netflix: Мониторинг в реално време и обработка на потоци
Netflix има своя собствена рамка за поглъщане, която изхвърля входните данни в AWS S3 и използва Hadoop за стартиране на анализи на видео потоци, UI дейности, събития за подобряване на потребителското изживяване и Kafka за поглъщане на данни в реално време чрез API.
4. Hotstar: Обработка на потоци
Hotstar представи своя собствена платформа за управление на данни - Bifrost, където Kafka се използва за поточно предаване, наблюдение и проследяване на целите. Поради своята мащабируемост, наличност и възможности за ниска латентност, Kafka беше идеален избор за обработка на данните, които платформата на hotstar генерира ежедневно или по някакъв специален повод (поточно предаване на концерти или всякакви спортни срещи на живо и т.н.), където обемът на данните се увеличава значително.
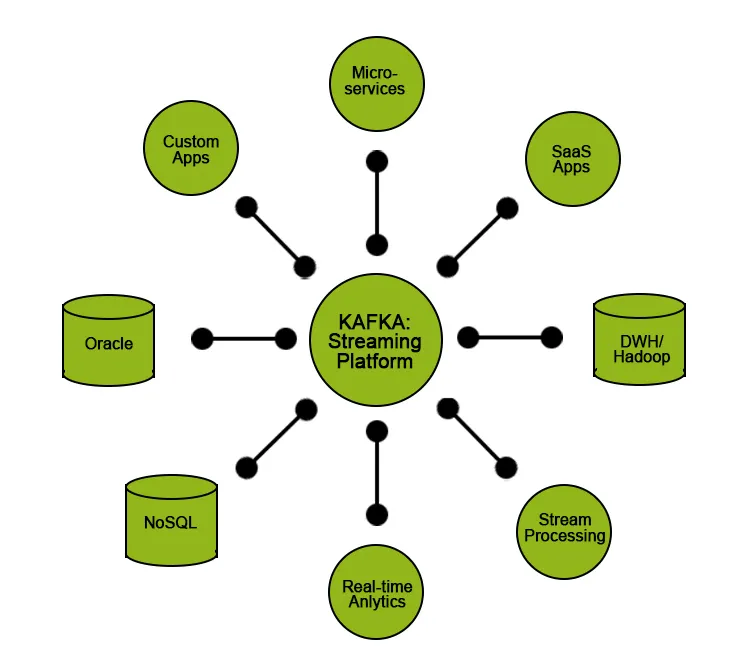
Apache Kafka през повечето време се използва като градивен елемент за разработване на архитектура на поточни данни. Този вид архитектура се използва в приложения като събиране на дневници на продукти / сървъри, анализ на клик поток и извличане на информация от машинно генерирани данни.
Но заедно с Kafka, трябва да използваме допълнителни ресурси или инструменти, за да преобразуваме получения поток от данни в смислени данни, които помагат за получаване на прозрения, които могат да бъдат използвани при решения, управлявани от данни. Например, може да се наложи да генерираме представа от необработените данни, получени от IoT устройства или данни, получени от платформи за социални медии в реално време, и да извършим някакъв анализ или обработка и да я покажем на бизнеса, за да вземе по-добри решения или да им помогне да подобрят изпълнението на техните услуги.
За тези видове случаи на използване бихме искали да предаваме нашите входни данни / необработени данни в езеро с данни, където можем да съхраняваме нашите данни и да гарантираме качеството на данните, без да затрудняваме тяхната ефективност.
Друга ситуация, която може да четем данни директно от Kafka, е, когато се нуждаем от изключително ниска латентност, като подаване на данни в приложения в реално време.
Kafka предоставя определени функции на своите потребители:
- Публикувайте и се абонирайте за данни.
- Съхранявайте данни в реда, в който са генерирани ефективно.
- Обработка на данни в реално време / в движение.
Кафка през повечето време се използва за:
- Внедряване на поточни тръбопроводи за поточно предаване на данни, които надеждно получават данни между две единици в системата.
- Внедряване на поточни приложения в движение, които трансформират или манипулират или обработват потоците от данни.
Случаи на употреба
По-долу са описани някои широко използвани приложения на приложението Kafka:
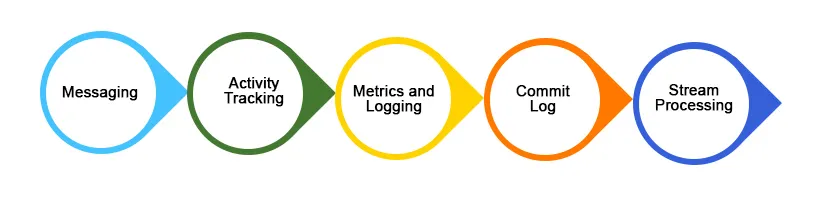
1. Съобщения
Kafka работи по-добре от други традиционни системи за съобщения като ActiveMQ, RabbitMQ и др. За сравнение, Kafka предлага по-добра пропускателна способност, вградено устройство за дялове, репликация и отказоустойчивост, което го прави по-добра система за съобщения за широкомащабни приложения за обработка,
2. Проследяване на активността на уебсайта
Потребителските дейности (изгледи на страници, търсения или извършени действия) могат да се проследяват и подават за наблюдение или анализ в реално време чрез Kafka или да използват Kafka за съхранение на тези видове данни в Hadoop или склад за данни за по-късна обработка или манипулация. Проследяването на активността генерира огромно количество данни, които трябва да бъдат прехвърлени на желаното място без никакъв вид загуба на данни.
3. Обобщение на лога
Обобщаването на дневника е процес на събиране / обединяване на физически файлове на журнали от различни сървъри на приложение в едно хранилище (файлов сървър или HDFS) за обработка. Kafka предлага добра производителност, по-ниска латентност в края в сравнение с Flume.

заключение
Kafka се използва силно в пространството с големи данни като начин за поглъщане и преместване на големи количества данни много бързо поради своите характеристики и характеристики, които помагат за постигане на мащабируемост, надеждност и устойчивост. В тази статия обсъдихме Apache Kafka неговите функции, случаи на използване и приложение и какво го прави по-добър инструмент за поточно предаване на данни.
Препоръчителни статии
Това е ръководство за приложенията на Kafka. Тук обсъждаме какво е Kafka заедно с топ приложенията на Kafka, които включват широко внедрени случаи на употреба и някои реализации в реалния живот. Можете също да разгледате следните статии, за да научите повече-
- Какво е Кафка?
- Как да инсталирате Kafka?
- Въпроси за интервю с Kafka
- Apache Kafka срещу Flume
- Топ 8 устройства на IoT, които трябва да знаете
- Кафка срещу Кинезис | Разлики с Инфографика
- Различни видове инструменти Kafka с компоненти
- Научете най-добрите разлики на ActiveMQ срещу Kafka