

Разлика между MapReduce и Spark
Map Reduce е рамка с отворен код за записване на данни в HDFS и обработка на структурирани и неструктурирани данни, налични в HDFS. Намаляването на картата е ограничено до пакетна обработка, а при други Spark е в състояние да извършва всякакъв вид обработка. SPARK е независим процесор за обработка в реално време, който може да бъде инсталиран на всяка разпределена файлова система като Hadoop. SPARK осигурява производителност, която е 10 пъти по-бърза от намаляването на картата на диска и 100 пъти по-бърза от намаляването на картата в мрежа в паметта.
Нуждаете се от SPARK
- Iterative Analytics: Намаляването на картата не е толкова ефективно, колкото SPARK за решаване на проблеми, които изискват итеративна анализа, тъй като трябва да отиде на диск за всяка итерация.
- Интерактивна аналитика: Намаляването на картата често се използва за изпълнение на ad-hoc заявки, за които трябва да стигне до дискова памет, която отново не е толкова ефективна, колкото SPARK, тъй като последната се отнася в паметта, която е по-бърза.
- Не е подходящ за OLTP: Тъй като работи върху пакетно ориентираната рамка, той не е подходящ за голям брой кратки транзакции.
- Не е подходящ за графика: Библиотеката на Apache Graph обработва графиката, което добавя по-голяма сложност към намаляването на картата.
- Не е подходящо за тривиални операции: За операции като филтър и присъединяване може да се наложи да пренапишем заданията, което става по-сложно поради модела ключ-стойност.
Сравнение между главата на MapReduce срещу Spark (Инфографика)
По-долу е топ 15 Разлика между MapReduce и Spark

Ключови разлики между MapReduce срещу Spark
По-долу са списъците с точки, опишете ключовите разлики между MapReduce и Spark:
- Spark е подходящ за реално време, докато обработва с използване на памет, докато MapReduce е ограничен до пакетна обработка.
- Spark има RDD (Resilient Distributed Dataset), който ни дава оператори на високо ниво, но в намалението на Map трябва да кодираме всяка операция, което я прави сравнително трудна.
- Spark може да обработва графики и поддържа инструмента за машинно обучение.
- По-долу е разликата между екосистемата MapReduce срещу Spark.
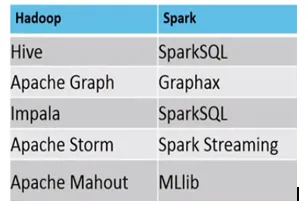
Пример, където MapReduce срещу Spark са подходящи, са както следва
Искри: Откриване на измами с кредитна карта
MapReduce: Създаване на редовни доклади, които изискват вземане на решения.
Таблица за сравнение на MapReduce срещу искри
| Основа за сравнение | MapReduce | искра |
| рамка | Рамка с отворен код за записване на данни в HDFS и обработка на структурирани и неструктурирани данни, присъстващи в HDFS. | Рамка с отворен код за по-бърза и обща обработка на данни |
| скорост | Map-Reduce обработва данните (чете и записва) от диск, така че просочването е бавно в сравнение с Spark. | Spark е поне 10X по-бърз на диска и 100X по-бърз в паметта като този на Map Reduce. |
| затруднение | Трябва да кодираме / обработваме всеки процес. | С наличието на RDD (Resilient Distributed Dataset) е лесно да се програмира. |
| Реално време | Не е подходящ за транзакция на OLTP само за пакетен режим | Той може да се справи с обработката в реално време. Използване на SPARK Streaming. |
| латентност | Рамка за изчисляване на закъснения на високо ниво | Компютърна рамка за ниско ниво на латентност. |
| Толерантност на грешки | Главните демони проверяват сърдечната дейност на демоните на робите и в случай, че демоните на робите не успеят, майсторите демони разсрочват всички чакащи и в ход операция към друг роб. | RDD осигуряват толерантност на грешки към SPARK. Те се отнасят до набора от данни, налични във външно съхранение като (HDFS, HBase) и работят паралелно. |
| Scheduler | В Map Reduce използваме външен планировчик като Oozie. | Тъй като SPARK работи с изчисления в паметта, той действа като собствен планировчик. |
| цена | Намалението на картата е сравнително по-евтино в сравнение със SPARK. | Тъй като работи в паметта, така че изисква много RAM, което го прави сравнително по-скъпо. |
| Платформа, разработена на | Намалението на карти е разработено с помощта на Java. | SPARK е разработен с помощта на Scala. |
| Поддържан език | Карта Намаляване поддържа основно C, C ++, Ruby, Groovy, Perl, Python. | Spark поддържа Scala, Java, Python, R, SQL. |
| Поддръжка на SQL | Map Намаляване изпълнява заявки с помощта на Hive Query Language. | Spark има свой език за заявки, известен като Spark SQL. |
| скалируемост | В Намаляване на карти можем да добавим до n брой възли. Най-големият клъстер Hadoop има 14000 възли. | В Spark също можем да добавим n брой възли. Най-големият клъстер Spark има 8000 възли. |
| Машинно обучение | Map Reduce поддържа инструмент Apache Mahout за машинно обучение. | Spark поддържа MLlib инструмент за машинно обучение. |
| кеширане | Намалението на картата не е в състояние да кешира данните в паметта, така че да не е толкова бързо в сравнение с Spark. | Spark кешира данните в паметта за по-нататъшни итерации, така че е много бърз в сравнение с намаляването на картата. |
| Сигурност | Map Reduce поддържа повече проекти и функции за сигурност в сравнение с Spark | Защитата на искрите все още не е настъпила, тъй като тази на Map Reduce |
Заключение - MapReduce срещу Spark
Съгласно горната Разлика между MapReduce и Spark, съвсем ясно е, че SPARK е много по-напреднал изчислителен двигател в сравнение с Map Reduce. Spark е съвместим с всеки тип файлов формат и също така доста по-бърз от Map Reduce. Искрата в допълнение има и графична обработка и възможности за машинно обучение.
От една страна, намалението на картата е ограничено до пакетна обработка, а от друга Spark е в състояние да извършва всякакъв вид обработка (пакетна, интерактивна, итеративна, поточна, графична). Поради голямата съвместимост Spark е фаворитът на Data Scientist и следователно неговото заместване на Map Намалява и расте бързо. Но все пак трябва да съхраняваме данните в HDFS и ние също понякога може да се нуждаем от HBase. Затова трябва да стартираме както Spark, така и Hadoop, за да постигнем най-доброто.
Препоръчани статии:
Това е ръководство за MapReduce срещу Spark, тяхното значение, сравнение между главата, ключови разлики, таблица на сравнението и заключение. Можете също да разгледате следните статии, за да научите повече -
- 7 важни неща за Apache Spark (Ръководство)
- Hadoop vs Apache Spark - интересни неща, които трябва да знаете
- Apache Hadoop срещу Apache Spark | Топ 10 сравнения, които трябва да знаете!
- Как работи MapReduce?
- Съединение на технологията и бизнес анализа