

Какво е алгоритъмът на Naive Bayes?
Наивен алгоритъм на Байес е техника, която помага да се конструират класификатори. Класификаторите са моделите, които класифицират проблемните екземпляри и им дават етикети на класове, които са представени като вектори на предиктори или стойности на характеристиките. Тя се основава на теоремата на Байес. Нарича се наивен Байес, тъй като предполага, че стойността на дадена характеристика не зависи от другата характеристика, т.е. промяната на стойността на характеристиката не би повлияла на стойността на другия признак. Нарича се още като идиот Байес поради същата причина. Този алгоритъм работи ефективно за големи масиви от данни, поради което е най-подходящ за прогнози в реално време.
Той помага да се изчисли задната вероятност P (c | x), като се използва предварителната вероятност за клас P (c), предварителната вероятност на предиктор P (x) и вероятността за даден клас на предиктора, наричан също като вероятност P (x | c) ).
Формулата или уравнението за изчисляване на задната вероятност е:
- P (c | x) = (P (x | c) * P (c)) / P (x)
Как работи алгоритъмът на Naive Bayes?
Нека да разберем работата на алгоритма на наивните байеси, използвайки пример. Предполагаме набор от данни за времето за обучение и целевата променлива „Отиване на пазаруване“. Сега ще класифицираме дали момиче ще отиде да пазарува въз основа на метеорологичните условия.
Даденият набор от данни е:
| Метеорологично време | Отивате да пазарувате |
| слънчево | Не |
| дъждовен | да |
| облачен | да |
| слънчево | да |
| облачен | да |
| дъждовен | Не |
| слънчево | да |
| слънчево | да |
| дъждовен | Не |
| дъждовен | да |
| облачен | да |
| дъждовен | Не |
| облачен | да |
| слънчево | Не |
Следните стъпки ще бъдат изпълнени:
Стъпка 1: Направете честотни таблици, използвайки набори от данни.
| Метеорологично време | да | Не |
| слънчево | 3 | 2 |
| облачен | 4 | 0 |
| дъждовен | 2 | 3 |
| Обща сума | 9 | 5 |
Стъпка 2: Направете таблица на вероятностите, като изчислите вероятностите на всяко метеорологично състояние и отидете да пазарувате.
| Метеорологично време | да | Не | вероятност |
| слънчево | 3 | 2 | 5/14 = 0, 36 |
| облачен | 4 | 0 | 4/14 = 0, 29 |
| дъждовен | 2 | 3 | 5/14 = 0, 36 |
| Обща сума | 9 | 5 | |
| вероятност | 9/14 = 0, 64 | 5/14 = 0, 36 |
Стъпка 3: Сега трябва да изчислим задната вероятност, използвайки уравнението на Naive Bayes за всеки клас.
Проблемен пример: Момиче ще отиде да пазарува, ако времето е облачно. Правилно ли е това твърдение?
Решение:
- P (Да | Облачно) = (P (Облачно | Да) * P (Да)) / P (Облачно)
- P (Облачно | Да) = 4/9 = 0, 44
- P (Да) = 9/14 = 0, 64
- P (облачно) = 4/14 = 0, 39
Сега поставете всички изчислени стойности в горната формула
- P (Да | Облачно) = (0, 44 * 0, 64) / 0, 39
- P (Да | Облачно) = 0.722
Класът с най-голяма вероятност ще бъде резултатът от прогнозата. Използването на едни и същи вероятности от различни класове може да се предвиди.
За какво се използва алгоритмът на Naive Bayes?
1. Прогнозиране в реално време: Алгоритмът на Naive Bayes е бърз и винаги готов да се научи, поради което е най-подходящ за прогнози в реално време.
2. Прогнозиране на много класове : Вероятността за мултикласове на всяка целева променлива може да се предвиди с помощта на алгоритъм Naive Bayes.
3. Система за препоръчване: Класификаторът Naive Bayes с помощта на Collaborative Filtering изгражда система за препоръки. Тази система използва техники за извличане на данни и машинно обучение, за да филтрира информацията, която не е видяна преди, и след това да прогнозира дали потребителят би оценил даден ресурс или не.
4. Класификация на текст / Анализ на чувството / Филтриране на нежелана поща: Поради по-добрата си работа с многокласни проблеми и правилото си за независимост, алгоритъмът на Naive Bayes се представя по-добре или има по-висока степен на успеваемост в класификацията на текста, следователно, той се използва в анализа на сентенцията и Филтриране на спам.
Предимства на алгоритма на наивния Байес
- Лесен за изпълнение.
- Бърз
- Ако предположението за независимост важи, то то работи по-ефективно от другите алгоритми.
- Това изисква по-малко данни за обучение.
- Той е силно мащабируем.
- Може да направи вероятни прогнози.
- Може да обработва както непрекъснати, така и дискретни данни.
- Нечувствителен към без значение характеристики.
- Тя може да работи лесно с липсващи стойности.
- Лесно се актуализира при пристигането на нови данни.
- Най-подходящ за проблеми с класифицирането на текста.
Недостатъци на алгоритма на наивния Байес
- Силното предположение за функциите да бъдат независими, което едва ли е вярно в приложенията в реалния живот.
- Недостиг на данни.
- Шансове за загуба на точност.
- Нулева честота, т.е. ако категорията на която и да е категорична променлива не се наблюдава в набора от данни за тренировки, тогава моделът придава нулева вероятност на тази категория и тогава не може да се направи прогноза.
Как да изградим основен модел, използвайки алгоритма на Naive Bayes
Има три типа модели на наивни байеси, т.е. гаусски, мултиномни и Бернули. Нека да обсъдим накратко всеки от тях.
1. Гаусов: Алгоритъмът на наивните байеси на Гаус предполага, че непрекъснатите стойности, съответстващи на всяка характеристика, се разпределят според гауссовото разпределение, наречено също като нормално разпределение.
Вероятността или предварителната вероятност за предсказател на дадения клас се приема за Гаус, следователно условната вероятност може да се изчисли като:
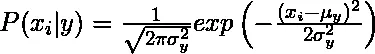
2. Мултиномиални: Честотите на настъпване на определени събития, представени от характеристики вектори, се генерират с помощта на мултиномно разпределение. Този модел се използва широко за класификация на документи.
3. Bernoulli: В този модел входовете се описват от характеристиките, които са независими двоични променливи или Booleans. Това се използва широко и в класификацията на документи като мултиномиални наивни байеси.
Можете да използвате всеки от горните модели, както е необходимо, за да обработвате и класифицирате набора от данни.
Можете да изградите гауссов модел с помощта на Python, като разберете примера, даден по-долу:
Код:
from sklearn.naive_bayes import GaussianNB
import numpy as np
a = np.array((-2, 7), (1, 2), (1, 5), (2, 3), (1, -1), (-2, 0), (-4, 0), (-2, 2), (3, 7), (1, 1), (-4, 1), (-3, 7)))
b = np.array((3, 3, 3, 3, 4, 3, 4, 3, 3, 3, 4, 4, 4))
md = GaussianNB()
md.fit (a, b)
pd = md.predict (((1, 2), (3, 4)))
print (pd)
изход:
((3, 4))
заключение
В тази статия научихме подробно концепциите на алгоритма на наивните байеси. Използва се най-вече в класификацията на текста. Той е лесен за изпълнение и бърз за изпълнение. Основният му недостатък е, че изисква функциите да бъдат независими, което не е вярно в реалните приложения.
Препоръчителни статии
Това е ръководство за алгоритма на наивните байеси. Тук обсъдихме основната концепция, работа, предимства и недостатъци на алгоритма на наивните байеси. Можете да разгледате и другите ни предложени статии, за да научите повече -
- Подсилване на алгоритъм
- Алгоритъм в програмирането
- Въведение в алгоритъма