

Въведение в карта Присъединете се в кошер
Присъединяването към карта е функция, използвана в заявките на Hive за повишаване на нейната ефективност по отношение на скоростта. Присъединяването е условие, използвано за комбиниране на данните от 2 таблици. И така, когато извършваме нормално присъединяване, заданието се изпраща до задача за намаляване на картата, която разделя основната задача на 2 етапа - „Етап на карта“ и „Намаляване на етап“. Етапът на карта интерпретира входните данни и връща изхода на етапа на намаляване под формата на двойки ключ-стойност. Следващото преминава през етапа на разбъркване, където се сортират и комбинират. Редукторът приема тази сортирана стойност и завършва работата за присъединяване.
Таблица може да се зареди в паметта изцяло в картограф и без да се налага да използвате процеса Map / Reducer. Той чете данните от по-малката таблица и ги съхранява в хеш таблица в паметта и след това сериализира в файл с хеш памет, като по този начин значително намалява времето. Известен е още като Map Side Join in Hive. По принцип тя включва извършване на присъединяване между 2 таблици, като се използва само Map Map и пропуска фазата на намаляване. Намаляване на времето в изчисленията на вашите заявки може да се наблюдава, ако те редовно използват малка таблица се присъединява.
Синтаксис за присъединяване към карта в кошер
Ако искаме да извършим заявка за присъединяване с помощта на map-join, тогава трябва да посочим ключова дума „/ * + MAPJOIN (b) * /“ в изявлението, както е показано по-долу:
>SELECT /*+ MAPJOIN(c) */ * FROM tablename1 t1 JOIN tablename2 t2 ON (t1.emp_id = t2.emp_id);
За този пример трябва да създадем 2 таблици с имена tablename1 и tablename2, имащи 2 колони: emp_id и emp_name. Единият трябва да бъде по-голям файл и един по-малък.
Преди да стартирате заявката, трябва да зададем по-долу свойството true:
hive.auto.convert.join=true
Заявката за присъединяване към присъединяване към карта е написана както по-горе и резултатът, който получаваме е:
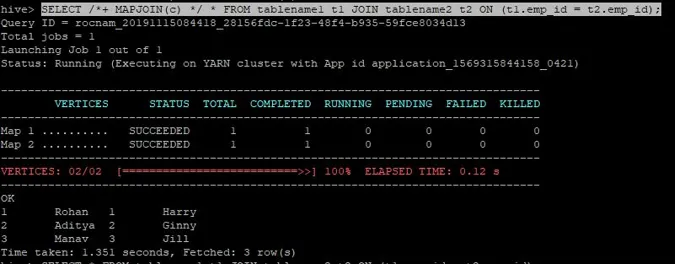
Заявката приключи за 1.351 секунди.
Примери за присъединяване към карта в кошер
Ето следните примери, споменати по-долу
1. Пример за присъединяване към карта
За този пример, нека създадем 2 таблици, наречени table1 и table2 със 100 и 200 записа съответно. Можете да се обърнете към командата и екранните снимки по-долу за изпълнение на същото:
>CREATE TABLE IF NOT EXISTS table1 ( emp_id int, emp_name String, email_id String, gender String, ip_address String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");
>CREATE TABLE IF NOT EXISTS table2 ( emp_id int, emp_name String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");

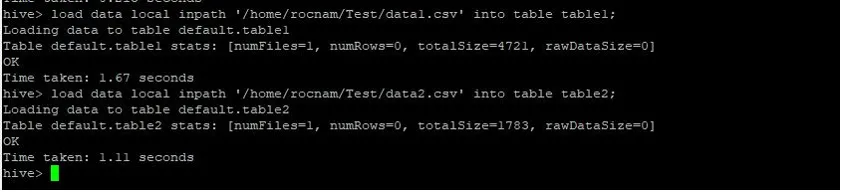
Сега зареждаме записите в двете таблици, използвайки команди по-долу:
>load data local inpath '/relativePath/data1.csv' into table table1;
>load data local inpath '/relativePath/data2.csv' into table table2;
Нека да извършим нормална заявка за присъединяване към картата на техните идентификационни номера, както е показано по-долу, и да проверим времето, необходимо за същото:
>SELECT /*+ MAPJOIN(table2) */ table1.emp_name, table1.emp_id, table2.emp_id FROM table1 JOIN table2 ON table1.emp_name = table2.emp_name;
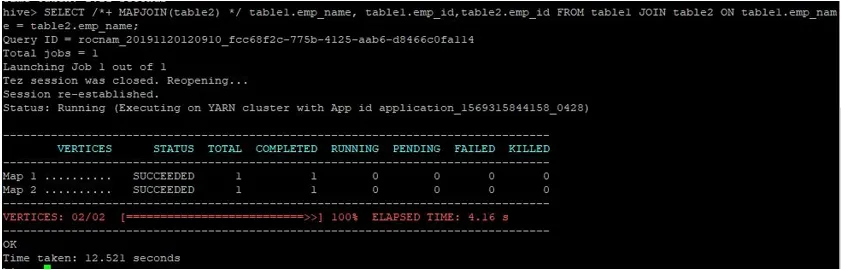
Както виждаме, нормалната заявка за присъединяване към карта отне 12.521 секунди.
2. Пример за присъединяване към Bucket-Map
Нека сега използваме Bucket-map join, за да изпълним същото. Има няколко ограничения, които трябва да се спазват за копане:
- Кофите могат да бъдат съединени помежду си, само ако общата кофа на която и да е една таблица е кратна на броя кофи в другата таблица.
- Трябва да има букетирани маси за извършване на копаене. Следователно нека да създадем същото.
Следват командите, използвани за създаване на букетирани таблици table1 и table2:
>>CREATE TABLE IF NOT EXISTS table1_buk (emp_id int, emp_name String, email_id String, gender String, ip_address String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ';
>CREATE TABLE IF NOT EXISTS table2_buk ( emp_id int, emp_name String) clustered by(emp_name) into 8 buckets row format delimited fields terminated BY ', ' ;

Ние също така ще вмъкваме същите записи от table1 в тези таблици:
>insert into table1_buk select * from table1;
>insert into table2_buk select * from table2;
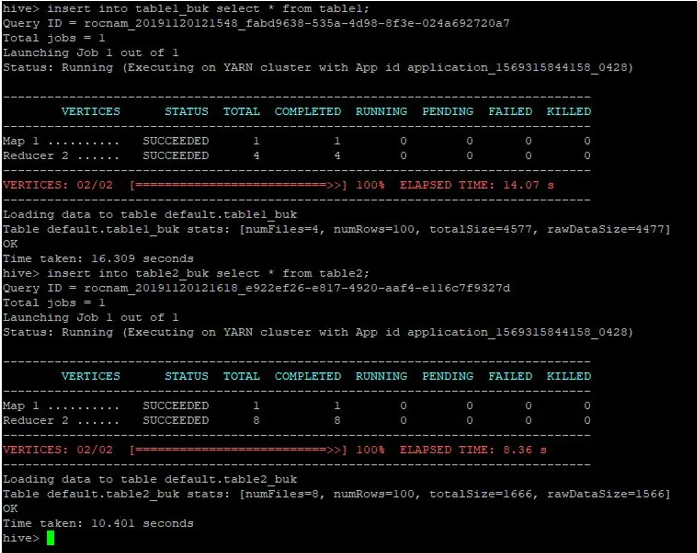
Сега, след като имаме нашите две букетирани таблици, нека да извършим присъединяване към карта с кофа по тях. Първата таблица има 4 кофи, докато втората има 8 кофи, създадени в същата колона.
За да работи заявката за присъединяване към кофата към кофата, трябва да зададем по-долу свойството true в кошера:
set hive.optimize.bucketmapjoin = true
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
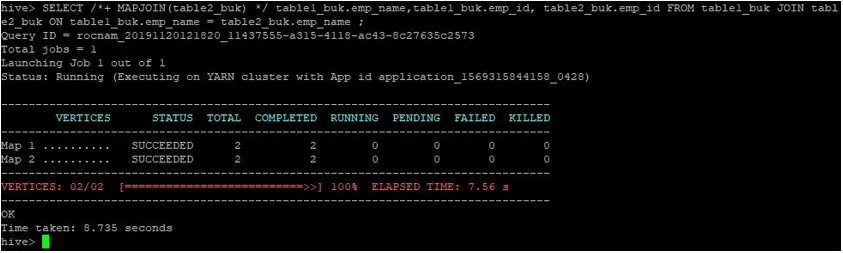
Както виждаме, заявката приключи за 8.735 секунди, което е по-бързо от нормално присъединяване към карта.
3. Сортирайте Пример за присъединяване към карта на кофата за сливане (SMB)
SMB може да се извърши на букетирани маси с еднакъв брой кофи и ако таблиците трябва да бъдат сортирани и котирани в колони за присъединяване. Нивото на Mapper съответно се присъединява към тези кофи.
Същото като при присъединяването към Bucket-map, има 4 кофи за table1 и 8 кофи за table2. За този пример ще създадем друга таблица с 4 кофи.
За да стартираме SMB заявка, трябва да зададем следните свойства на кошера, както е показано по-долу:
Hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
hive.optimize.bucketmapjoin = true;
hive.optimize.bucketmapjoin.sortedmerge = true;
За да се извърши SMB присъединяването, трябва да бъдат сортирани данни по колоните за присъединяване. Следователно, ние презаписваме данните в таблица 1, както е описано по-долу:
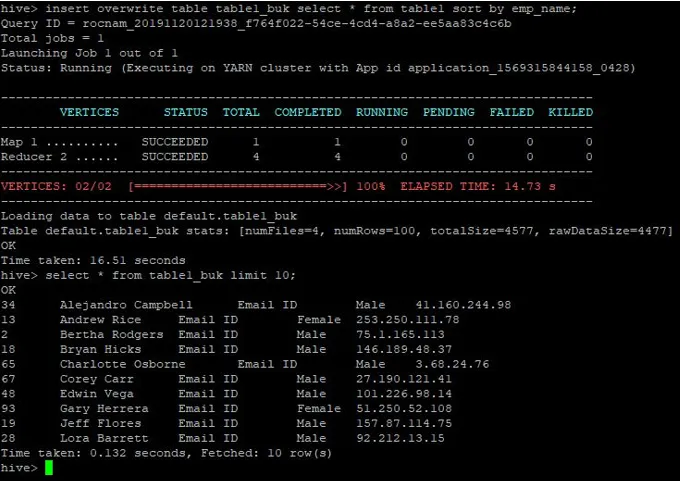
>insert overwrite table table1_buk select * from table1 sort by emp_name;
Данните са сортирани сега, което може да се види на снимката по-долу:
Ние също така ще презапишем данните в букет таблица2, както е посочено по-долу:
>insert overwrite table table2_buk select * from table2 sort by emp_name;

Нека изпълним присъединяването за по-горе 2 таблици, както следва:
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
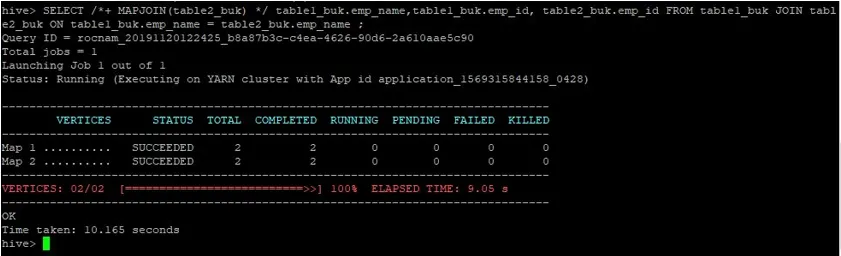
Виждаме, че заявката отне 10.165 секунди, което отново е по-добро от нормално присъединяване към картата.
Нека сега създадем друга таблица за table2 с 4 кофи и същите данни, сортирани с emp_name.
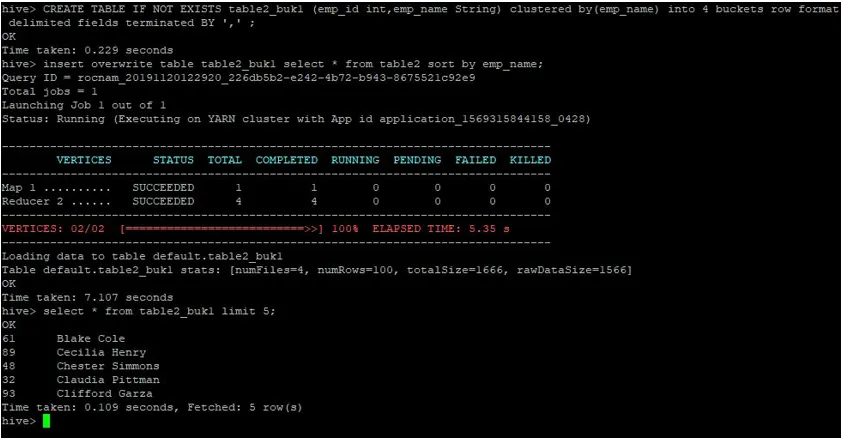
>CREATE TABLE IF NOT EXISTS table2_buk1 (emp_id int, emp_name String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ' ;
>insert overwrite table table2_buk1 select * from table2 sort by emp_name;
Имайки предвид, че сега имаме и двете таблици с 4 кофи, нека отново извършим заявка за присъединяване.
>SELECT /*+ MAPJOIN(table2_buk1) */table1_buk.emp_name, table1_buk.emp_id, table2_buk1.emp_id FROM table1_buk JOIN table2_buk1 ON table1_buk.emp_name = table2_buk1.emp_name ;
Заявката отне 8.851 секунди отново по-бързо от нормалното заявка за присъединяване към картата.
Предимства
- Присъединяването към карта намалява времето, отделено за процеси на сортиране и сливане, протичащи в разбъркването, и намалява етапите, като по този начин минимизира разходите също.
- Повишава ефективността на изпълнение на задачата.
Ограничения
- Една и съща таблица / псевдоним не е позволено да се използва за присъединяване на различни колони в една и съща заявка.
- Заявката за присъединяване към карта не може да преобразува Пълното външно присъединяване в присъединяващата се страна на картата.
- Присъединяването към карта може да се извърши само когато една от таблиците е достатъчно малка, така че да може да се побере в паметта. Следователно тя не може да бъде изпълнена там, където данните от таблицата са огромни.
- Лево присъединяване е възможно да се извърши към присъединяването към карта само когато размерът на дясната таблица е малък.
- Право присъединяване е възможно да се извърши към присъединяването към карта само когато размерът на лявата таблица е малък.
заключение
Опитахме се да включим най-добрите възможни точки от Map Join in Hive. Както видяхме по-горе, присъединяването от страна на картата работи най-добре, когато една таблица има по-малко данни, така че работата да приключи бързо. Времето, необходимо за заявките, показани тук, зависи от размера на набора от данни, следователно времето, показано тук, е само за анализ. Присъединяването към карта може лесно да се реализира в приложения в реално време, тъй като разполагаме с огромни данни, като по този начин спомагаме за намаляване на мрежовия I / O трафик.
Препоръчителни статии
Това е ръководство за Map Join in Hive. Тук обсъждаме примерите на Map Join in Hive, заедно с предимствата и ограниченията. Можете също да разгледате следната статия, за да научите повече -
- Присъединява се в кошер
- Функции за вграждане в кошер
- Какво е кошер?
- Команди на кошера