

Въведение в дървото на решенията при извличане на данни
В днешния свят на „Големите данни“ терминът „Извличане на данни“ означава, че трябва да разгледаме големи масиви от данни и да извършим „извличане“ на данните и да извадим важния сок или същността на това, което искат да кажат данните. Много аналогична ситуация е ситуацията с добив на въглища, където са необходими различни инструменти за изкопаване на въглищата, заровени дълбоко под земята. От инструментите в извличането на данни „Дървото на решенията“ е един от тях. По този начин извличането на данни само по себе си е огромно поле, в което следващите няколко абзаца ще се потопим дълбоко в „инструмента“ на „Дървото на решението“ в Data Mining.
Алгоритъм на дървото на решения при извличане на данни
Дървото на решенията е подход на контролирано обучение, при който ние обучаваме наличните данни, като вече знаем каква е всъщност целевата променлива. Както подсказва името, този алгоритъм има дървесен тип структура. Нека първо разгледаме теоретичния аспект на Дървото на решенията и след това да разгледаме същото в графичен подход. В дървото на решения алгоритъмът разделя набора от данни на подмножества въз основа на най-важния или значим атрибут. Най-значимият атрибут е обозначен в коренния възел и именно там се извършва разделянето на целия набор от данни, присъстващ в коренния възел. Това разделяне е известно като възли за вземане на решения. В случай, че не е възможно повече разцепване, възелът се нарича листен възел.
За да се спре алгоритъмът за достигане на превъзходен етап, се използва критерий за спиране. Един от критериите за спиране е минималният брой наблюдения в възела, преди да се случи разделянето. Докато прилагате дървото на решения при разделянето на набора от данни, човек трябва да бъде внимателен, че много възли могат просто да имат шумни данни. За да се погрижим за външни или шумни проблеми с данните, използваме техники, известни като Подрязване на данни. Подрязването на данни не е нищо друго, освен алгоритъм за класифициране на данни от подмножеството, което затруднява обучението от даден модел.
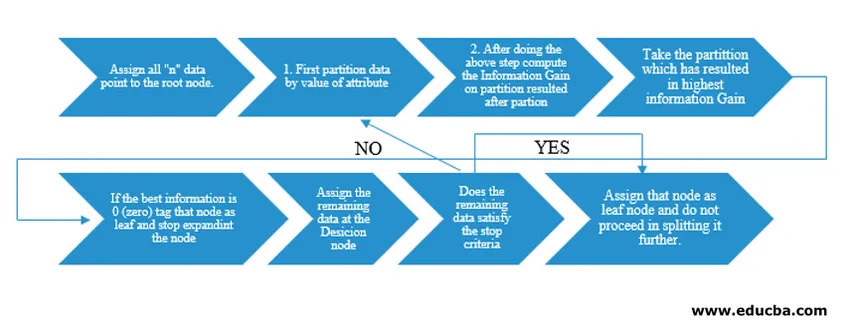
Алгоритъмът за дърво на решението беше пуснат като ID3 (Iterative Dichotomiser) от машинен изследовател J. Ross Quinlan. По-късно C4.5 беше освободен като наследник на ID3. И ID3, и C4.5 са алчен подход. Сега нека разгледаме диаграма на алгоритъма на дървото на решенията.
За нашето разбиране на псевдокодове, ние бихме взели „n“ точки от данни, всяка от които има „k“ атрибути. По-долу е направена диаграма, като се има предвид „Информационна печалба“ като условие за разделяне.
IG (on individual split) = Entropy before the split – Entropy after a split (On individual split)
Вместо увеличаване на информацията (IG) можем да използваме и индекса на Джини като критерии за разделяне. За да разберем разликата между тези два критерия по отношение на миряните, можем да мислим за тази печалба на информацията като разлика на ентропията преди разделянето и след разделянето (разделяне въз основа на всички налични функции).
Ентропията е като случайност и бихме достигнали точка след разделянето, за да имаме най-малко случайност. Следователно информационното повишаване трябва да бъде най-голямо в характеристиката, която искаме да разделим. В противен случай, ако искаме да изберем разделянето на базата на индекса на Джини, бихме намерили индекса на Джини за различни атрибути и използвайки същия, откриваме претегления индекс на Джини за различен сплит и използваме този с по-висок индекс на Джини, за да разделим набора от данни.
Важни условия на дървото на решенията при обработката на данни
Ето някои от важните условия на дървото на решения при извличането на данни, дадени по-долу:
- Root Node: Това е първият възел, където се извършва разделянето.
- Листов възел: Това е възелът, след който няма повече разклонения.
- Решение на възела: Възелът, образуван след разделяне на данни от предишен възел, е известен като възел за решение.
- Клон: Подраздел на дърво, съдържащ информация за последствията от разделянето на възела за решение.
- Подрязване: Когато има премахване на под-възли на възел за вземане на решение за обслужване на външни или шумни данни се нарича подрязване. Смята се също, че е обратното на разцепването.
Приложение на дървото на решенията при извличане на данни
Дървото за решения има архитектура от типа на блок-схемата, вградена с типа алгоритъм. По същество има вид "If X, тогава Y else Z", докато се прави разделянето. Този тип модел се използва за разбиране на човешката интуиция в програмното поле. Следователно човек може широко да използва това при различни проблеми с категоризацията.
- Този алгоритъм може да бъде широко използван в областта, в която е свързана обективната функция по отношение на анализа.
- Когато са на разположение множество начини на действие.
- Външен анализ.
- Разбиране на значителния набор от функции за целия набор от данни и „мина“ няколкото функции от списък от стотици функции в големи данни.
- Избор на най-добрия полет за пътуване до дестинация.
- Процес на вземане на решение въз основа на различни обстоятелства.
- Анализ на Churn.
- Анализ на чувството
Предимства на дървото на решенията
Ето някои предимства на дървото на решенията, обяснено по-долу:
- Лесно разбиране: Начинът, по който дървото на решенията е изобразено в неговите графични форми, прави лесно разбирането за човек с неаналитичен произход. Особено за хората в лидерството, които искат да разгледат кои характеристики са важни само с един поглед към дървото на решения, могат да изведат своята хипотеза.
- Изследване на данни: Както беше обсъдено, получаването на значителни променливи е основна функционалност на дървото на решенията и използването на същото, по време на проучването на данните може да се разбере как да се реши коя променлива ще се нуждае от специално внимание по време на фазата на извличане на данни и моделиране.
- По време на етапа на подготовка на данните има много малко човешка намеса и в резултат на това време, изразходвано по време на данните, почистването намалява.
- Дървото на решенията е в състояние да борави както с категорични, така и с цифрови променливи, а също така се справя и с многокласови проблеми с класификацията.
- Като част от предположението, дърветата на решенията нямат предположение от структура на пространствено разпределение и класификатор.
заключение
И накрая, в заключение Дърветата на решението въвеждат съвсем различен клас нелинейност и се грижат за решаването на проблеми с нелинейността. Този алгоритъм е най-добрият избор за имитиране на мислене на хората на ниво решение и представянето му в математически-графична форма. Той използва подход „отгоре надолу“ при определяне на резултатите от нови невиждани данни и следва принципа на разделяне и завладяване.
Препоръчителни статии
Това е ръководство за Дървото на решенията в извличането на данни. Тук обсъждаме алгоритъма, важността и прилагането на дървото на решения при извличането на данни, заедно с неговите предимства. Можете също да разгледате следните статии, за да научите повече -
- Машинно обучение за наука на данни
- Видове техники за анализ на данни
- Дърво на решения в R
- Какво представлява извличането на данни?
- Ръководство за различни методологии за анализ на данни