

Въведение в техниките за научни данни
В днешния свят, където данните са новото злато, съществуват различни видове анализ за бизнес, който може да направи. Резултатът от проект за научни данни варира значително в зависимост от вида на наличните данни и следователно въздействието е променлива. Тъй като има много различен вид анализ, става наложително да се разбере какви няколко основни техники трябва да бъдат избрани. Основната цел на техниките за наука на данни е не само търсене на подходяща информация, но и откриване на слаби връзки, които водят до слабо функциониране на модела.
Какво е наука за данни?
Науката за данните е област, която се разпространява в няколко дисциплини. Той включва научни методи, процеси, алгоритми и системи за събиране на знания и работа по същото. Това поле включва различни жанрове и е обща платформа за обединяване на концепции за статистика, анализ на данни и машинно обучение. В това отношение теоретичните знания на статистиката заедно с данните в реално време и техниките в машинното обучение работят ръка за ръка, за да се получат ползотворни резултати за бизнеса. Използвайки различни техники, използвани в науката за данни, ние в днешния свят можем да предполагаме по-добро вземане на решения, които в противен случай може да липсват от човешкото око и ум. Не забравяйте, че машината никога не забравя! За да увеличите максимално печалбата в управляван от данни свят, магията на Data Science е необходим инструмент, който трябва да има.
Различни видове техники за научни данни
В следващите няколко абзаца ще разгледаме общи техники за научни данни, използвани във всеки друг проект. Въпреки че понякога техниката на науката за данни може да бъде специфична за бизнес проблема и може да не попада в категориите по-долу, е напълно добре да ги наречем като различни видове. На високо ниво разделяме техниките на надзорни (ние знаем въздействието на целта) и неподдържани (не знаем за целевата променлива, която се опитваме да постигнем). В следващото ниво техниките могат да бъдат разделени по отношение на
- Резултатът, който бихме получили или какъв е намерението на бизнес проблема
- Тип на използваните данни.
Нека първо разгледаме сегрегацията въз основа на намерението.
1. Неуправляемо обучение
- Откриване на аномалия
При този тип техника ние идентифицираме всяко неочаквано събитие в целия набор от данни. Тъй като поведението се различава от действителното случване на данни, основните предположения са:
- Появата на тези случаи е много малка.
- Разликата в поведението е значителна.
Обяснени са алгоритмите на аномалията, като Isolation Forest, който предоставя оценка за всеки запис в набор от данни. Този алгоритъм е модел на базата на дърво. Използвайки този тип техника за откриване и неговата популярност, те се използват в различни бизнес случаи, например, прегледи на уеб страници, процент на изглаждане, приходи на кликване и т.н. В графиката по-долу можем да обясним как изглежда аномалията.
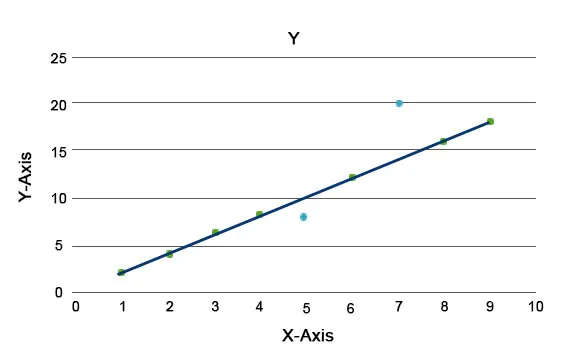
Тук тези в синьо представляват аномалия в набора от данни. Те се различават от обикновената линия на тренда и се срещат по-малко.
- Анализ на клъстеринг
Чрез този анализ основната задача е да се раздели целият набор от данни в групи, така че тенденцията или чертите в една група данни точки да са доста сходни една с друга. В терминологията на науката за данни ние ги наричаме клъстер. Например в търговията на дребно има план за мащабиране на бизнеса и е наложително да се знае как биха се държали новите клиенти в нов регион въз основа на миналите данни, които имаме. Става невъзможно да се изработи стратегия за всеки индивид в дадена популация, но ще бъде полезно групирането на населението в клъстери, така че стратегията да бъде ефективна в група и да е мащабируема.
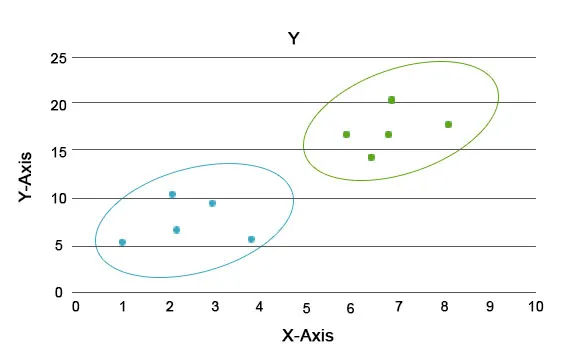
Тук синият и оранжевият цвят са различни групи, които имат уникални черти в себе си.
- Анализ на асоциацията
Този анализ ни помага да изградим интересни взаимоотношения между елементи в набор от данни. Този анализ разкрива скритите връзки и помага при представянето на елементи от набора от данни под формата на правила за асоцииране или набори от чести елементи. Правилото за асоцииране е разбито на 2 стъпки:
- Често генериране на набор от артикули: В това се генерира набор, където често срещаните елементи се настройват заедно.
- Генериране на правила: Построеният по-горе набор се предава през различни слоеве за формиране на правила, за да се изгради скрита връзка помежду си. Например, наборът може да попадне или в концептуални проблеми или проблеми с прилагането, или в проблеми с приложението. След това те се разклоняват в съответните дървета за изграждане на правилата за асоцииране.
Например, APRIORI е алгоритъм за изграждане на правила за асоцииране.
2. Контролирано обучение
- Регресионен анализ
При регресионен анализ ние определяме зависимата / целевата променлива и останалите променливи като независими променливи и в крайна сметка хипотезираме как една / повече независими променливи влияят на целевата променлива. Регресията с една независима променлива се нарича унивариантна и с повече от една е известна като мултивариантна. Нека да разберем, използвайки унивариантна и след това скала за многовариантна.
Например, y е целевата променлива и x 1 е независимата променлива. И така, от знанието за правата, можем да запишем уравнението като y = mx 1 + c. Тук “m” определя колко силно y е повлияно от x 1 . Ако „m“ е много близо до нула, това означава, че с промяна в x 1, y не се влияе силно. С число, по-голямо от 1, въздействието се засилва и малката промяна в х 1 води до големи изменения в у. Подобно на едновариантното, в многовариантното може да се запише като y = m 1 x 1 + m 2 x 2 + m 3 x 3 ………., Тук въздействието на всяка независима променлива се определя от съответстващото й „m“.
- Класификационен анализ
Подобно на клъстерния анализ, алгоритмите за класификация са изградени с целевата променлива под формата на класове. Разликата между клъстерирането и класификацията се състои в това, че при клъстеринга не знаем в коя група попадат точките от данни, докато в класификацията знаем към коя група принадлежи. И се различава от регресията от гледна точка, че броят на групите трябва да бъде фиксирано число за разлика от регресията, той е непрекъснат. Има куп алгоритми в анализа на класификацията, например, Подкрепящи векторни машини, Логистична регресия, Дървета на решения и т.н.
заключение
В заключение, ние разбираме, че всеки тип анализ е огромен сам по себе си, но тук можем да предоставим малък вкус на различни техники. В следващите няколко бележки ще вземем всеки един от тях поотделно и ще влезем в подробности относно различните под-техники, използвани във всяка родителска техника.
Препоръчителен член
Това е ръководство за техниките за научни данни. Тук обсъждаме въвеждането и различните видове техники в науката за данни. Можете да разгледате и другите ни предложени статии, за да научите повече -
- Инструменти за научни данни | Топ 12 инструменти
- Алгоритми за научни данни с типове
- Въведение в кариерата на научните данни
- Data Science срещу визуализация на данни
- Примери за многовариантна регресия
- Създайте дърво на решения с предимства
- Кратък преглед на жизнения цикъл на науката за данни