

Разлика между Hadoop и HBase
Hadoop е рамка на Java с отворен код, използвана за управление и обработка на огромно количество структурирани и неструктурирани данни. Hadoop е мащабируем, затова се използва за обработка на големи натоварвания на данни. Големите данни се съхраняват, имат достъп и се обработват в надежден и разширяващ се клъстер. HBase (Hadoop Database) е нерелационна и не само SQL, т.е. NoSQL база данни, която работи на върха на Hadoop като разпределен и мащабируем голям магазин за данни. Това е база данни с отворен код, в която данните се съхраняват под формата на редове и колони, в тази клетка е пресечна точка на колони и редове.
По-долу са основните компоненти на Hadoop архитектурата:
- Hadoop разпределена файлова система (HDFS): Hadoop включва разпределена система за съхранение, разпределената файлова система Hadoop (HDFS). HDFS е архитектурата master-slave, която съхранява данни в клъстера. Данни, разпределени на няколко подчинени възли от главния възел в блока с форми. Главният възел се нарича Namenode, а подчинените възли се наричат Datanode. HDFS се разширява лесно и съхранява огромно количество данни за Datanodes. HDFS има конфигурируем коефициент на репликация с стойност по подразбиране 3, която може да се редактира.
- MapReduce: MapReduce е парадигма за програмиране, обработваща паралелно върху огромен брой набори от данни в мрежата. MapReduce се отнася до две различни задачи: картографиране на входните данни, в които данните, разделени на подмножество от данни, наречени като кортежи и намаляване на задачата, взема тези кортези от картата като вход и се комбинира, за да формира изхода на оригинала.
- Прежда: YARN означава още един навигатор на ресурси, който изчислява ресурси като управление на процесора и паметта, планиране на заявките за ресурси.
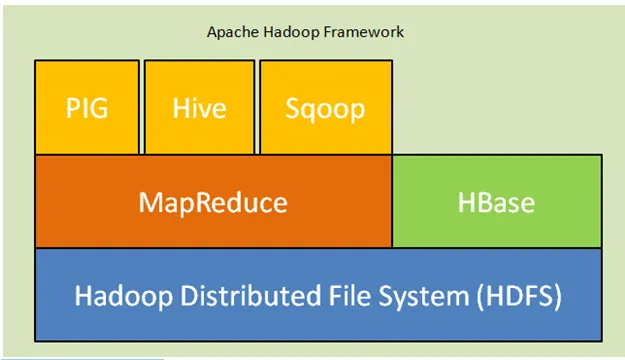
Фиг. Apache Hadoop Framework
Регионалният сървър обслужва данни за операции за четене / запис. Всички данни на HBase се съхраняват във файла HDFS. HDFS Datanode съхранява данните, които Регионалният сървър управлява. HDFS Namenode съхранява информацията за метаданните за всички физически блокове данни, които съдържат файловете.
Версията се използва за проследяване на промените в клетките, което поддържа версията на съдържанието. От това може да бъде извлечена всяка версия на съдържанието. Всяка стойност на клетката включва атрибута „версия“ по отношение на времевата марка за изтегляне на клетката. Всяка стойност в картата е непрекъснат масив от байтове. Картата се индексира с ключ за ред, ключ за колона и времева марка. Архитектурата на HBase е силно мащабируема, оскъдна, разпределена, устойчива и многомерна сортирана карта.
Сравнение между главата на Hadoop срещу HBase (Инфографика)
По-долу е топ 7 разликата между Hadoop срещу HBase
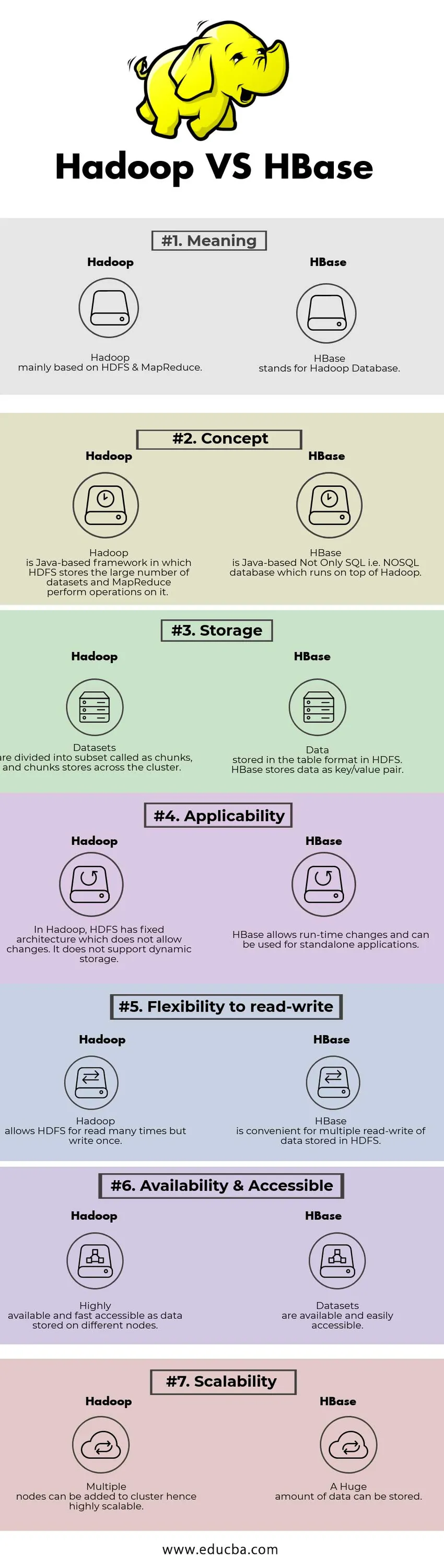
Ключови разлики между Hadoop срещу HBase
Разликата между Hadoop и HBase се обяснява в точките, представени по-долу:
- Hadoop не е подходящ за онлайн аналитична обработка (OLAP) и HBase е част от екосистемата Hadoop, която осигурява произволен достъп в реално време (четене / запис) до данни във файловата система на Hadoop.
- Рамката на Hadoop е устойчива на повреди по дизайн и поддържа бърз трансфер на данни между възлите, дори по време на системни сривове. HBase е нерелационна и с отворен код не-само-SQL база данни, която работи над Hadoop. HBase попада под CP тип теорема за CAP (последователност, наличност и толерантност на дяловете).
- Hadoop е най-подходящ за извършване на партиден анализ. Въпреки това, един от най-големите му недостатъци е неспособността му да извършва анализ в реално време, тенденцията на изискване на ИТ индустрията. HBase, от друга страна, може да се справи с големи масиви от данни и не е подходящ за партиден анализ. Вместо това се използва за писане / четене на данни от Hadoop в реално време.
- И Hadoop и HBase са способни да обработват структурирани, полуструктурирани, както и неструктурирани данни. В Hadoop при HDFS липсва механизъм за обработка на памет, който забавя процеса на анализ на данните; тъй като използва обикновена стара MapReduce, за да го направи. HBase, напротив, може да се похвали с двигател за обработка на памет, който драстично увеличава скоростта на четене / запис.
- Hadoop е много прозрачен в изпълнението на анализа на данните. HBase, от друга страна, като база данни на NoSQL в табличен формат, извлича стойности, като ги сортира под различни ключови стойности.
Таблица за сравняване на Hadoop срещу HBase
| БАЗА ЗА СРАВНЕНИЕ | Hadoop | HBase |
| значение | Hadoop основно базиран на HDFS & MapReduce. | HBase означава Hadoop Database. |
| понятие | Hadoop е базирана на Java рамка, в която HDFS съхранява големия брой набори от данни и MapReduce извършва операции върху нея. | HBase е базираната на Java не само SQL, т.е. NoSQL база данни, която работи над Hadoop. |
| съхранение | Наборите от данни са разделени на подмножество, наречени парчета, и парчета за съхраняване в клъстера. | Данните се съхраняват във формат на таблицата в HDFS. HBase съхранява данни като двойка ключ / стойност. |
| Приложимост | В Hadoop HDFS има фиксирана архитектура, която не позволява промени. Не поддържа динамично съхранение. | HBase позволява промени в процеса на изпълнение и може да се използва за самостоятелни приложения. |
| Гъвкавост за четене и писане | Hadoop позволява на HDFS да чете много пъти, но пише веднъж. | HBase е удобен за многократно четене и запис на данни, съхранявани в HDFS |
| Наличност и достъпност | Силно достъпни и бързо достъпни като данни, съхранявани на различни възли. | Наборите от данни са достъпни и лесно достъпни |
| скалируемост | Множество възли могат да бъдат добавени към клъстера, следователно е много мащабируем. | Огромно количество данни може да се съхранява. |
Заключение - Hadoop срещу HBase
Hadoop архитектура главно на базата на HDFS и MapReduce. HBase е поддържащият компонент в системата Hadoop. HBase е в състояние да хоства огромни таблици и да осигурява бърз случаен достъп до наличните данни, докато HDFS е подходящ за съхранение на големи файлове. Както Hadoop, така и HBase осигуряват бърз достъп до данни, но с операции за четене / запис на HBase могат да се извършват, а при HDFS се чете много пъти и веднъж може да се извърши записването. Тази статия описва разбирането на Hadoop и HBase, накратко подчертани характеристики и сравнени разумно.
Препоръчителен член
- Apache Hadoop срещу Apache Spark | Топ 10 сравнения, които трябва да знаете!
- Hadoop срещу кошера - открийте най-добрите разлики
- HBase срещу Cassandra - кой е по-добър (Инфографика)
- Топ 12 Сравнение на Apache Hive с Apache HBase (Инфографика)
- Hadoop срещу Spark: Какви са характеристиките