
Какво е SVM алгоритъм?
SVM означава „Vector Vector Support“. SVM е контролиран алгоритъм за машинно обучение, който обикновено се използва за предизвикателства за класификация и регресия. Често срещани приложения на SVM алгоритъма са система за откриване на проникване, разпознаване на ръкописен текст, прогнозиране на структурата на протеина, откриване на стеганография в цифрови изображения и др.
В алгоритъма SVM всяка точка е представена като елемент от данни в n-мерното пространство, където стойността на всяка характеристика е стойността на конкретна координата.
След начертаване, класификацията е извършена чрез намиране на хипе-равнина, която разграничава два класа. Вижте по-долу изображението, за да разберете тази концепция.
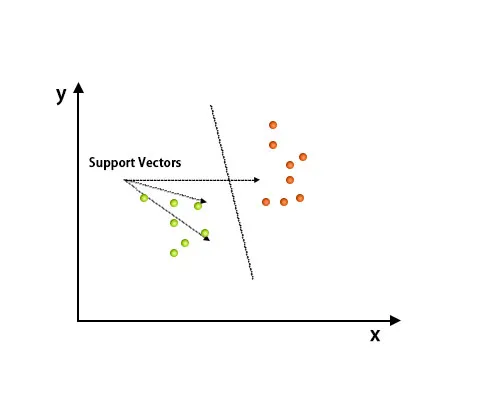
Алгоритъмът за поддръжка на Vector Machine се използва главно за решаване на проблеми с класификацията. Векторите за поддръжка не са нищо друго, освен координатите на всеки елемент от данни. Support Vector Machine е граница, която разграничава два класа с помощта на хиперплоскост.
Как работи SVM алгоритъмът?
В горния раздел сме обсъдили диференцирането на два класа с помощта на хиперплоскост. Сега ще видим как всъщност работи този SVM алгоритъм.
Сценарий 1: Идентифициране на дясната хиперплоскост
Тук сме взели три хиперплоскости т.е. A, B и C. Сега трябва да идентифицираме правилната хиперплоскост, за да класифицираме звезда и кръг.
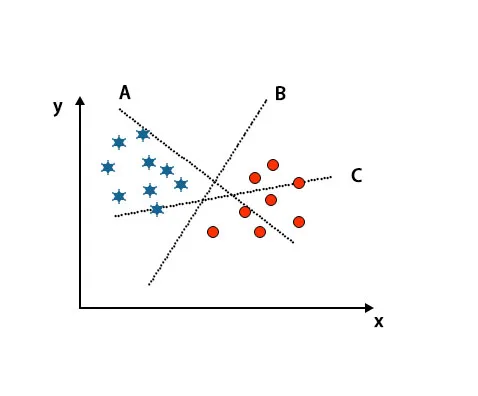
За да идентифицираме правилната хиперплоскост, трябва да знаем правилото за палеца. Изберете хиперплоскост, която разграничава два класа. В горепосоченото изображение, хиперплоскостта B много добре разграничава два класа.
Сценарий 2: Идентифициране на дясната хиперплоскост
Тук сме взели три хиперплоскости, т.е. A, B и C. Тези три хиперплоскости вече много добре разграничават класовете.
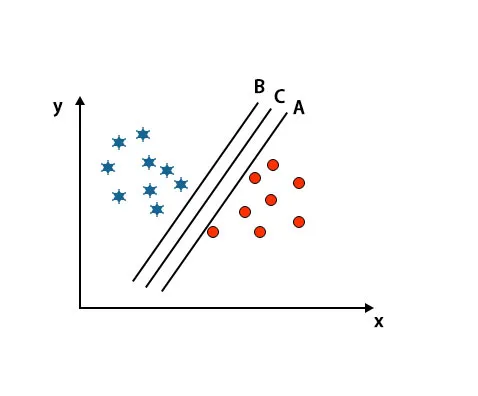
В този сценарий, за да идентифицираме правилната хиперплоскост, увеличаваме разстоянието между най-близките точки от данни. Това разстояние не е нищо друго освен разлика. Вижте по-долу изображението.
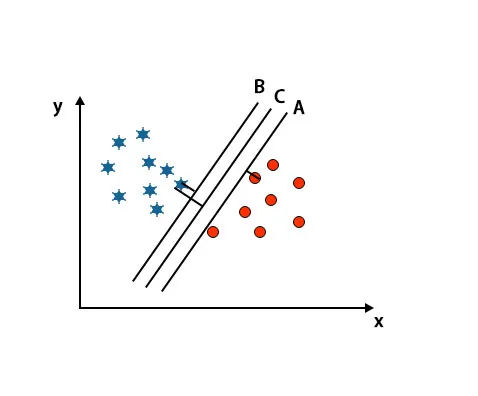
В горепосоченото изображение границата на хиперплоскостта С е по-висока от хиперплоскостта А и хиперплоскостта В. Така че в този сценарий С е правилната хиперплоскост. Ако изберем хиперплана с минимален марж, това може да доведе до погрешна класификация. Следователно избрахме хиперплан C с максимален запас поради здравина.
Сценарий 3: Идентифициране на дясната хиперплоскост
Забележка: За да идентифицирате хиперплана следвайте същите правила, както са споменати в предишните раздели.
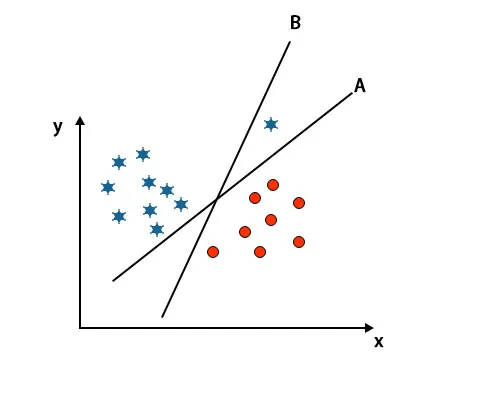
Както можете да видите на горепосоченото изображение, границата на хиперплоскост B е по-висока от границата на хиперплоскост А, затова някои ще изберат хиперплоскост B като дясна. Но в SVM алгоритъма, той избира тази хиперплоскост, която класифицира класовете точни преди максимално увеличаване на маржа. В този сценарий хиперплоскостта А е класифицирала всички точно и има известна грешка С класификацията на хиперплоскост В. Следователно А е правилната хиперплоскост.
Сценарий 4: Класифицирайте два класа
Както можете да видите на по-долу споменатото изображение, ние не можем да разграничим два класа, използвайки права линия, тъй като едната звезда лежи като външен в другия кръгов клас.
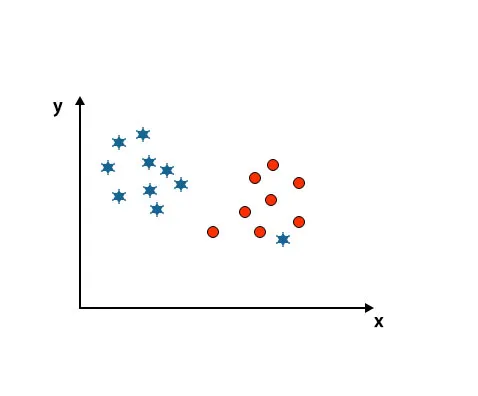
Ето, една звезда е в друг клас. За звезден клас тази звезда е по-външната. Поради свойството на устойчивост на SVM алгоритъма, той ще намери правилната хиперплоскост с по-висок марж, игнориращ външната страна.
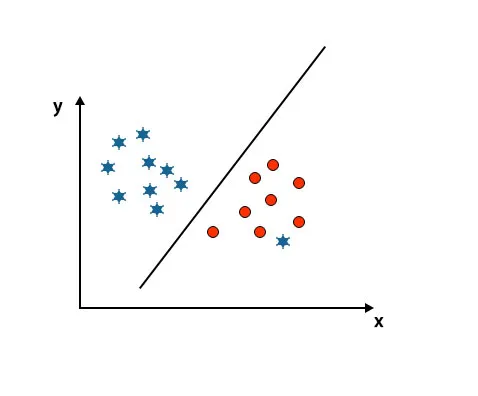
Сценарий 5: Фина хиперплоскост за разграничаване на класовете
Досега изглеждахме линейна хиперплоскост. В по-долу споменатото изображение нямаме линейна хиперплоскост между класовете.
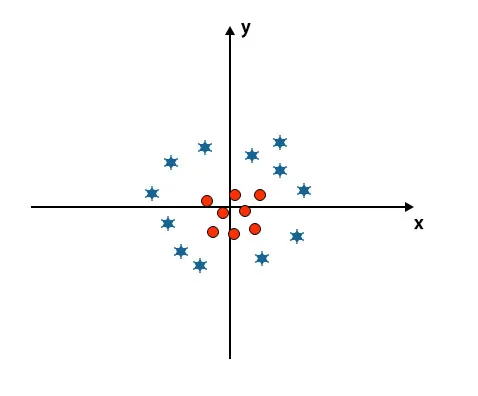
За да класифицира тези класове, SVM въвежда някои допълнителни функции. В този сценарий ще използваме тази нова функция z = x 2 + y 2.
Начертава всички точки от данни по оста x и z.

Забележка
- Всички стойности на z-ос трябва да са положителни, тъй като z е равно на сумата от x квадрат и y квадрат.
- В гореспоменатия сюжет червените кръгове са затворени до началото на x-ос и y-ос, което води до стойността на z към по-ниска, а звездата е точно обратната на окръжността, тя е далеч от началото на x-ос и y-ос, водеща стойността на z до висока.
В SVM алгоритъма е лесно да се класифицира с помощта на линейна хиперплоскост между два класа. Но тук възниква въпросът, трябва ли да добавим тази функция на SVM за идентифициране на хиперплоскост. Така че отговорът е не, за решаването на този проблем SVM има техника, която е известна като трик на ядрото.
Трикът на ядрото е функцията, която трансформира данните в подходяща форма. Има различни видове функции на ядрото, използвани в SVM алгоритъма, т.е. полиномиална, линейна, нелинейна, радиална основна функция и др. Тук с помощта на нискоизмерното входно пространство с трик на ядрото се преобразува в пространство с по-големи измерения.
Когато гледаме на хиперплоскостта произхода на оста и y-оста, тя изглежда като кръг. Вижте по-долу изображението.
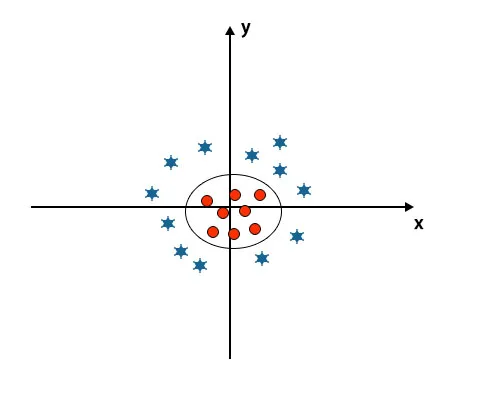
Плюсове на SVM алгоритъма
- Дори ако входните данни са нелинейни и неотделими, SVM генерират точни резултати от класификацията поради своята здравина.
- Във функцията за вземане на решение той използва подмножество от точки за обучение, наречени вектори на поддръжка, следователно е ефективна памет.
- Полезно е да се реши всеки сложен проблем с подходяща функция на ядрото.
- На практика SVM моделите се обобщават, с по-малък риск от прекаляване в SVM.
- SVMs работи чудесно за класифициране на текст и при намиране на най-добрия линеен разделител.
Минуси на SVM алгоритъм
- Това отнема дълго време за обучение при работа с големи набори от данни.
- Трудно е да се разбере крайният модел и индивидуалното въздействие.
заключение
Той е ръководен да поддържа алгоритъм за векторна машина, който е алгоритъм за машинно обучение. В тази статия обсъдихме в детайли какво е SVM алгоритъмът, как работи и кои са неговите предимства.
Препоръчителни статии
Това е ръководство за алгоритма на SVM. Тук обсъждаме работата му със сценарий, плюсове и минуси на SVM алгоритъм. Можете също да разгледате следните статии, за да научите повече -
- Алгоритми за извличане на данни
- Техники за извличане на данни
- Какво е машинно обучение?
- Инструменти за машинно обучение
- Примери за C ++ алгоритъм