

Въведение в Apache Flume
Apache Flume е рамка за поглъщане на данни, която записва базирани на събития данни в разпределената файлова система Hadoop. Известен факт е, че Hadoop обработва големи данни, възниква въпрос как данните, генерирани от различни уеб сървъри, се предават на файловата система на Hadoop? Отговорът е Apache Flume. Flume е проектиран за поглъщане на данни с голям обем до Hadoop на данни, базирани на събития.
Помислете за сценарий, при който броят на уеб сървърите генерира регистрационни файлове и тези лог файлове трябва да се предават на файловата система Hadoop. Flume събира тези файлове като събития и ги предава на Hadoop. Въпреки че Flume се използва за предаване до Hadoop, няма строго правило, че дестинацията трябва да бъде Hadoop. Flume може да пише в други рамки като Hbase или Solr.
Flume Architecture
Като цяло архитектурата на Apache Flume се състои от следните компоненти:
- Източник на дим
- Flume Channel
- Flume Sink
- Flume агент
- Flume Event
Нека да разгледаме накратко всеки компонент на Flume
1. Източник на дим
Източник на Flume присъства в генератори на данни като Face book или Twitter. Източникът събира данни от генератора и ги прехвърля на Flume Channel под формата на Flume Events. Flume поддържа различни видове източници като Avro Flume Source - свързва се на Avro порт и получава събития от външен клиент на Avro, Thrift Flume Source - свързва се на порта на Thrift и получава събития от външни поточни клиенти на Thrift, източник на Spooling Directory и Kafka Flume Source.
2. Flume Channel
Междинен магазин, който буферира събитията, изпратени от Flume Source, докато те бъдат консумирани от Sink, се нарича Flume Channel. Каналът действа като междинен мост между Източника и Мивката. Flume каналите имат транзакционен характер.
Flume осигурява поддръжка за канал за файлове и канал за памет. Файловият канал е траен по своя характер, което означава, че след като данните са записани за каналиране, той няма да бъде загубен, въпреки че ако агентът се рестартира. В паметта събитията на канала се съхраняват в паметта, така че той не е траен, но много бърз по своята същност.
3. Мивка на миди
Flume Sink присъства в хранилища на данни като HDFS, HBase. Flume мивка консумира събития от Channel и ги съхранява в дестинации магазини като HDFS. Няма правило, според което мивката да доставя събития в Store, вместо това можем да я конфигурираме по такъв начин, че мивката да може да доставя събития на друг агент. Flume поддържа различни мивки като мивка HDFS, мивка за кошери, мивка за икономия, Avro Sink.
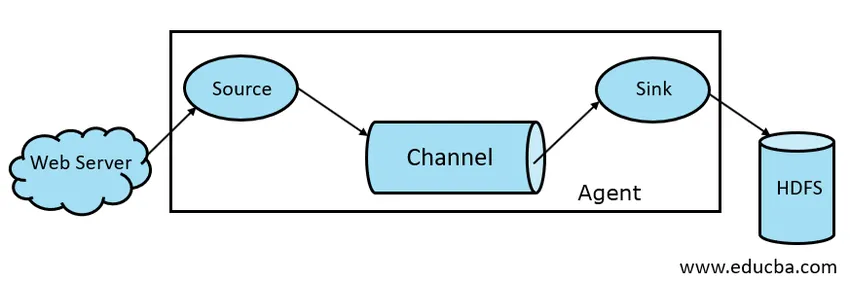
Фиг 1.1 Основна архитектура на димовете
4. Flume агент
Агентът на Flume е дългогодишен Java процес, който работи на източник - канал - комбиниране на мивка. Flume може да има повече от един агент. Можем да разгледаме Flume като съвкупност от свързани агенти на Flume, които са разпространени в природата.
5. Flume Event
Събитие е единицата данни, пренасяна във Flume . Общото представяне на Data Object във Flume се нарича Event. Събитието е съставено от полезен товар от байтов масив с незадължителни заглавки.
Работа на Flume
Агентът Flume е процес на Java, който се състои от Източник - Канал - Мивка в най-простата си форма. Източникът събира данни от генератора на данни под формата на събития и ги предава на Channel. Източник може да доставя до няколко канала според изискванията. Fan out е процесът, при който един източник ще запише на множество канали, така че те да могат да доставят на множество мивки.
Събитието е основната единица данни, които се предават във Flume. Канал буферира данните, докато не бъде погълнат от Sink. Sink събира данните от Channel и го доставя до Централизирано съхранение на данни като HDFS или Sink може да препраща тези събития до друг агент на Flume според изискванията.
Flume поддържа транзакции. За да постигне надеждност, Flume използва отделни транзакции от източник до канал и от канал до мивка. Ако събитията не бъдат доставени, транзакцията се отменя и по-късно се преизпълнява.
За да разберем работата на Flume, нека да вземем пример за конфигурация на Flume, където източникът е спойлинг директория, а мивката е Hdfs. В този пример агентът на Flume е в най-простата форма, т.е. единична топология на мивка на източник - канал, която е конфигурирана с помощта на файл със свойства на Java.
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.channels.channel1.type = file
В горния пример за конфигурация агентът е базата, с която дефинираме други свойства. source1 и sink1 и channel1 са имената на източника, мивката и канала съответно и техните видове и местоположения също се споменават съответно.
Предимства на Apache Flume
- Flume е мащабируем, надежден и устойчив на повреди. Тези свойства са разгледани подробно по-долу
- Мащабируемост - Flume е мащабируем хоризонтално, т.е. можем да добавим нови възли според нашето изискване
- Надеждно - Apache Flume има поддръжка за транзакции и гарантира, че в процеса на предаване на данни няма загуба на данни. Той има различни транзакции от източник към канал и от канал до източник.
- Flume е персонализируем и осигурява поддръжка на различни източници и мивки като Kafka, Avro, директория за навиване, Thrift и т.н.
- В Flume, един източник може да предава данни към множество канали, а тези канали от своя страна ще предават данните на множество мивки, като по този начин един източник може да предава данни към множество мивки. Този механизъм се нарича Fan out. Flume също поддържа за Fan out.
- Flume осигурява постоянен поток на предаване на данни, т.е. ако скоростта на четене на данни се увеличава и след това скоростта на записване на данни също се увеличава.
- Въпреки че Flume обикновено записва данни в централизирано хранилище като HDFS или Hbase, можем да конфигурираме Flume според нашето изискване, така че Sink може да записва данни на друг агент. Това показва гъвкавост на Flume
- Apache Flume е с отворен код в природата.
заключение
В тази статия на Flume подробно са разгледани компонентите на Flume и работата на Flume. Flume е гъвкава, надеждна и мащабируема платформа за предаване на данни в централизиран магазин като HDFS. Способността му да се интегрира с различни приложения като Kafka, Hdfs, Thrift правят своя жизнеспособна опция за приемане на данни.
Препоръчителни статии
Това е ръководство за Apache Flume. Тук обсъждаме архитектурата, работата и предимствата на Apache Flume. Може да разгледате и следните статии, за да научите повече -
- Какво е Apache Flink?
- Разлика между Apache Kafka срещу Flume
- Архитектура на големи данни
- Hadoop инструменти
- Научете различните JavaScript събития