

Разлика между Hadoop и кошер
Hadoop:
Hadoop е рамка или софтуер, който е изобретен за управление на огромни данни или големи данни. Hadoop се използва за съхранение и обработка на големи данни, разпространени в клъстер от стокови сървъри.
Hadoop съхранява данните, като използва разпределената файлова система на Hadoop и я обработва / запитва с помощта на модела за програмиране Map Reduce.
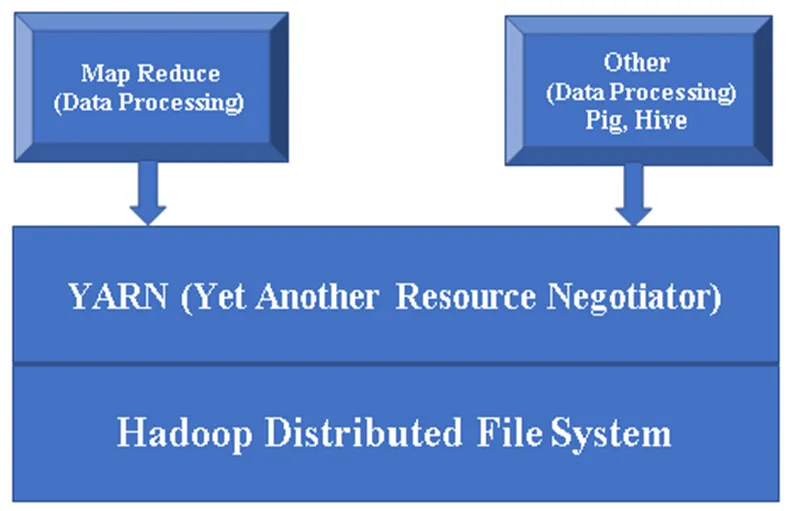
Фигура 1, Основна архитектура на компонент на Hadoop.
Основни компоненти на Hadoop:
Hadoop Base / Common: Hadoop common ще ви предостави една платформа за инсталиране на всички нейни компоненти.
HDFS (разпределена файлова система на Hadoop): HDFS е основна част от рамката на Hadoop и се грижи за всички данни в клъстера Hadoop. Той работи върху Master / Slave Architecture и съхранява данните, като използва репликация.
Главна / Slave архитектура и репликация:
- Главен възел / Име на възел: Името възел съхранява метаданните на всеки блок / файл, съхранявани в HDFS, HDFS може да има само един Главен възел (В случай на HA друг Главен възел ще работи като вторичен главен възел).
- Slave Node / Data Node: Възлите за данни съдържат действителни файлове с данни в блокове. HDFS може да има множество възли за данни.
- Репликация: HDFS съхранява данните си, като ги разделя на блокове. Размерът на блока по подразбиране е 64 MB. Поради репликацията данните се съхраняват в 3 (Коефициентът на репликация по подразбиране, може да бъде увеличен според изискванията) различни възли за данни, следователно има най-малка възможност за загуба на данните в случай на повреда на възел.
ПРЪЖДА (още един преговарящ ресурс): Основно се използва за управление на ресурси на Hadoop, освен това играе важна роля в планирането на приложението на потребителите.
MR (Намаляване на картата): Това е основният модел на програмиране на Hadoop. Използва се за обработка / заявка на данни в рамките на Hadoop.
Hive:
Hive е приложение, което работи над Hadoop и предоставя SQL интерфейс за обработка / заявка на данни. Hive е проектиран и разработен от Facebook, преди да стане част от проекта Apache-Hadoop.
Hive изпълнява заявката си с помощта на HQL (език на заявките на Hive). Hive има същата структура като RDBMS и в Hive могат да се използват почти същите команди.
Hive може да съхранява данните във външни таблици, така че не е задължително да се използва HDFS, също така поддържа файлови формати като ORC, Avro файлове, последователност и текстови файлове и т.н.
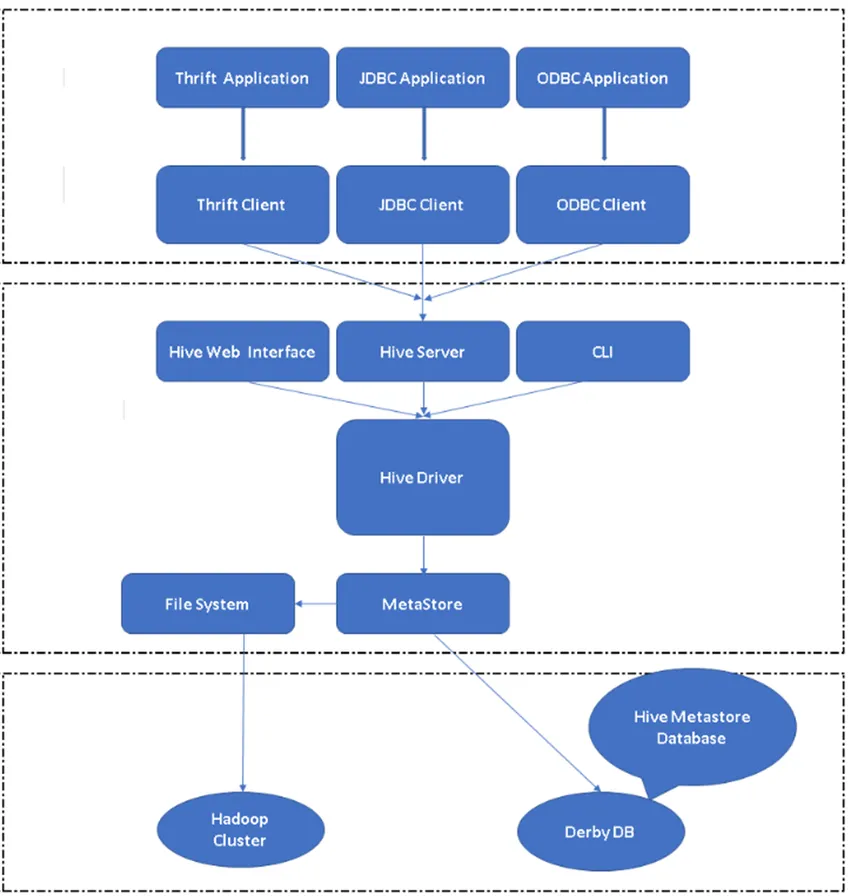
Фигура 2, Архитектура на Hive и неговите основни компоненти.
Основен компонент на кошера:
Клиенти на Hive: Не само SQL, Hive също така поддържа езици за програмиране като Java, C, Python, използвайки различни драйвери като ODBC, JDBC и Thrift. Човек може да напише всяко приложение за клиент на кошера на други езици и може да работи в Hive с помощта на тези клиенти.
Услуги на кошера: Под услугите на кошера се изпълняват команди и заявки. Уеб интерфейс на кошера има пет подкомпоненти.
- CLI: Интерфейс на командния ред по подразбиране, предоставен от Hive за изпълнение на Hive заявки / команди.
- Уеб интерфейси на кошера: Това е прост графичен потребителски интерфейс. Той е алтернатива на командния ред Hive и се използва за изпълнение на заявки и команди в приложението Hive.
- Сървър на кошери: Нарича се още като Apache Thrift. Отговорно е да приема команди от различни интерфейси на командния ред и да предава всички команди / заявки в Hive, също така той извлича крайния резултат.
- Apache Hive Driver: Той е отговорен за вземането на входовете от CLI, уеб интерфейса, ODBC, JDBC или Thrift интерфейсите от клиент и предава информацията в metastore, където се съхранява цялата информация за файла.
- Metastore: Metastore е хранилище за съхраняване на цялата информация за метаданни на Hive. Метаданните на Hive съхраняват информацията като структура на таблици, дялове и тип колони и т.н. …
Съхранение на кошера: Това е мястото, където се изпълнява действителната задача. Всички заявки, които се изпълняват от Hive, извършиха действието в Hive storage.
Сравнение между главата на Hadoop срещу Hive (Инфографика)
По-долу е топ 8 разликата между Hadoop срещу Hive
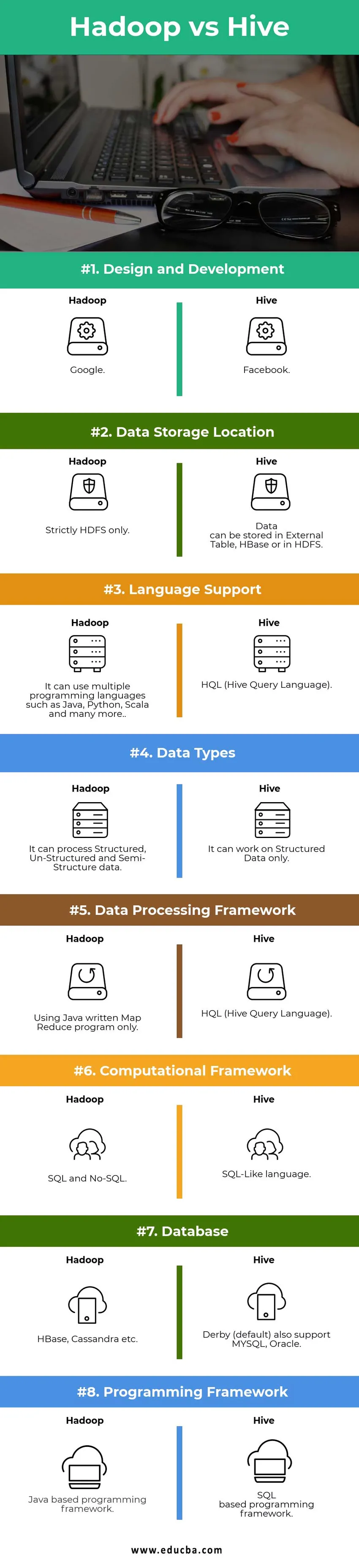
Основни разлики между Hadoop срещу Hive:
По-долу са списъците с точки, опишете ключовите разлики между Hadoop и Hive:
1) Hadoop е рамка за обработка / заявка на големи данни, докато Hive е инструмент, базиран на SQL, който изгражда над Hadoop за обработка на данните.
2) Hive обработва / запитва всички данни, използвайки HQL (Hive Query Language), това е SQL-Like Language, докато Hadoop може да разбере само намаление на картата.
3) Намаляването на картата е неразделна част от Hadoop, заявката на Hive първо се преобразува в карта Намаляване, отколкото обработена от Hadoop, за да се запитват данните.
4) Hive работи на SQL Like заявка, докато Hadoop го разбира само чрез Java-базирано намаление на картата.
5) В Hive, по-рано използваните традиционни „Relational Database“ команди също могат да се използват за заявка на големите данни, докато сте в Hadoop, трябва да напишете сложни програми за намаляване на картата с помощта на Java, което не е подобно на традиционен Java.
6) Hive може да обработва / запитва само структурираните данни, докато Hadoop е предназначен за всички видове данни, независимо дали са структурирани, неструктурирани или полуструктурирани.
7) Използвайки Hive, човек може да обработва / запитва данните без сложно програмиране, докато е в екосистемата Simple Hadoop, трябва да напише сложна Java програма за същите данни.
8) Една от страничните рамки на Hadoop се нуждае от линия 100s за подготовка на Java-базирана MR програма, друга страна Hadoop с Hive може да запитва същите данни, използвайки 8 до 10 реда от HQL.
9) В Hive е много трудно да се вмъкне изходът на една заявка като вход на друга, докато същата заявка може да се направи лесно, използвайки Hadoop с MR.
10) Не е задължително да има Metastore в кластера Hadoop, докато Hadoop съхранява всичките си метаданни във формат HDFS (разпределена файлова система Hadoop).
Таблица за сравняване на Hadoop срещу кошера
| Сравнителни точки | кошер | Hadoop |
|
Дизайн и разработка | ||
| Местоположение за съхранение на данни |
Данните могат да се съхраняват във Външни Таблица, HBase или в HDFS. | Строго HDFS само. |
| Езикова поддръжка | HQL (език на заявката на кошера) |
Може да използва няколко езика за програмиране като Java, Python, Scala и много други. |
| Типове данни | Той може да работи само върху структурирани данни. |
Той може да обработва структурирани, неструктурирани и полуструктурни данни. |
| Рамка за обработка на данни |
HQL (език на заявката на кошера) | Използвайки само написана на Java програма за намаляване на картата. |
|
Изчислителна рамка | SQL-подобен език. | SQL и No-SQL. |
| База данни |
Дерби (по подразбиране) също поддържа MYSQL, Oracle … | HBase, Cassandra и т.н. … |
| Програмна рамка |
Основана на SQL рамка за програмиране. | Java-базирана рамка за програмиране. |
Заключение - Hadoop срещу Hive
И Hadoop и Hive се използват за обработка на големите данни. Hadoop е рамка, която осигурява платформа за други приложения да заявяват / обработват големите данни, докато Hive е просто SQL-базирано приложение, което обработва данните, използвайки HQL (Hive Query Language)
Hadoop може да се използва без Hive за обработка на големите данни, докато не е лесно да се използва Hive без Hadoop.
В заключение не можем да сравним Hadoop и Hive по никакъв начин и във всеки аспект. И Hadoop и Hive са напълно различни. Използването на двете технологии заедно може да направи процеса на запитване на Big Data много по-лесен и удобен за потребителите на големи данни.
Препоръчани статии:
Това е ръководство за Hadoop срещу кошера, тяхното значение, сравнение между главата, ключови разлики, таблица на сравнението и заключение. Можете също да разгледате следните статии, за да научите повече -
- Hadoop vs Apache Spark - интересни неща, които трябва да знаете
- HADOOP срещу RDBMS | Познайте 12-те полезни разлики
- Колко големи данни променят лицето на здравеопазването
- Топ 12 Сравнение на Apache Hive с Apache HBase (Инфографика)
- Невероятно ръководство за Hadoop срещу Spark