

Какво е AWS Kinesis?
Kinesis е платформа, която помага за събиране, обработка и анализ на поточни данни в Amazon Web Services. Данните за поточно предаване са голямо количество данни, които са породени от различни източници като социални медии, IoT сензори, прогноза за времето, здравеопазване и др. Те се използват при изграждане на приложения въз основа на изискването на потребителя. Някои от често срещаните приложения включват прогнозна анализа в големи данни, машинно обучение и др. В тази тема ще научим за AWS Kinesis.
AWS Kinesis Services
Преди да преминем към услугите, нека първо разберем някои терминологии, използвани в Kinesis.
терминология
| термин | дефиниция |
| Запис на данни | Единица данни, съхранявана в потока от данни на Kinesis. Състои се от блок данни, пореден номер и ключ за дял |
| елитра | Набор от поредицата от записи на данни. Броят на парчетата може да се увеличи или намали, ако скоростта на данните се увеличи. |
| Период на задържане | Периодът от време, през който данните могат да бъдат достъпни след добавянето им в потока.
Период на задържане по подразбиране: 24 часа |
| производител | Той подава записи на данни в Kinesis Stream |
| Консуматор | Получава записи от Kinesis Stream и ги обработва. |
Kinesis предоставя 3 основни услуги. Те са:
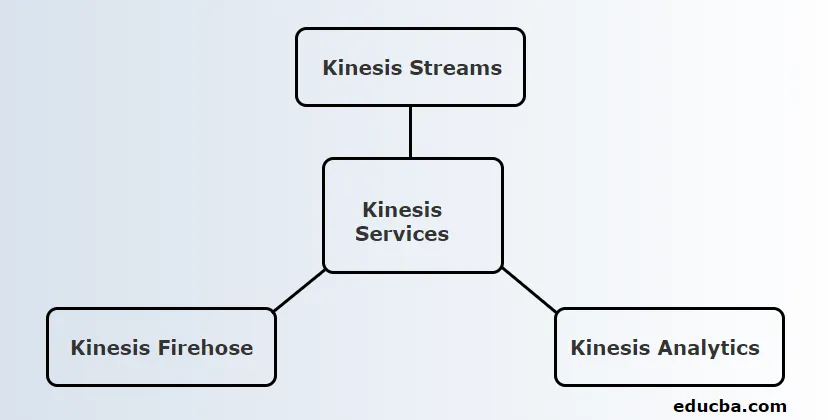
1. Кинезис потоци
Kinesis Stream се състои от набор от поредици от записи на данни, известни като Shards. Тези Shards имат фиксиран капацитет, който може да осигури максимална скорост на четене от 2 MB / секунда и скорост на запис 1 MB / секунда. Максималният капацитет на един поток е сумата от капацитета на всеки шейд.
Работа на Kinesis:
- Данните, получени от IoT и други източници, които са известни като Производители, се въвеждат в Kinesis потоци за съхранение в Shards.
- Тези данни ще бъдат налични в Shard за максимум 24 часа.
- Ако трябва да се съхранява за повече от това време по подразбиране, потребителят може да се увеличи до период на задържане от 7 дни.
- След като данните достигнат Shards, EC2 инстанциите могат да вземат тези данни за различни цели.
- EC2 случаи, които извличат данни, са известни като Потребители.
- След обработката на данни тя се подава в една от услугите на Amazon Web Services като Simple Storage Service (S3), DynamoDB, Redshift и т.н.
2. Kinesis Firehose
Kinesis Firehose е полезен за преместване на данни към уеб услуги на Amazon като Redshift, Simple storage storage, Elastic Search и др. Това е част от стрийминг платформата, която не управлява никакви ресурси. Производителите на данни са конфигурирани така, че данните трябва да бъдат изпращани на Kinesis Firehose и той автоматично ги изпраща до съответната дестинация.
Работа на Kinesis Firehose:
- Както бе споменато в работата на AWS Kinesis Streams, Kinesis Firehose също получава данни от производители като мобилни телефони, лаптопи, EC2 и т.н. Това е така, защото Kinesis Firehose го прави автоматично.
- След това данните се анализират автоматично и се подават в Simple Storage Service
- Тъй като няма период на задържане, данните трябва да бъдат анализирани или изпратени до всяко съхранение, зависи от изискванията на потребителя.
- Ако данните трябва да бъдат изпратени до Redshift, първо трябва да бъдат преместени в Simple Storage Service и трябва да копирате в Redshift оттам.
- Но в случай на Elastic Search, данните могат да бъдат директно подавани в него, подобно на Simple Storage Service.
3. Kinesis Analytics
Kinesis Firehose позволява да се изпълняват SQL заявките в данните, които присъстват в Kinesis Firehose. Използвайки тези SQL заявки, данните могат да се съхраняват в Redshift, Simple Storage Service, ElasticSearch и др.
AWS Kinesis Architecture
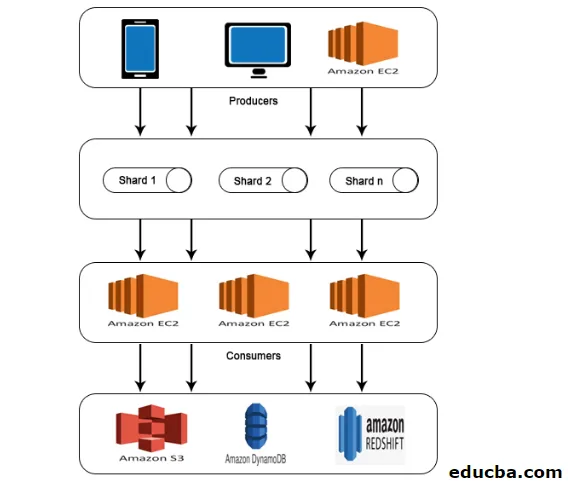
AWS Kinesis Architecture се състои от
- Производителите
- Късчета
- Потребителите
- съхранение
Подобно на работата, обяснена в AWS Kinesis Data Stream, данните от производителите се подават в Shards, където данните се обработват и анализират. След това анализираните данни се преместват в случаи на EC2 за изпълнение на определени приложения. Най-накрая данните ще се съхраняват във всяка от уеб услугите на Amazon като S3, Redshift и т.н.
Как да използвате AWS кинезис?
За да работите с AWS Kinesis, трябва да направите следните две стъпки.
1. Инсталирайте интерфейса на командния ред AWS (CLI).
Инсталирането на интерфейса на командния ред е различно за различните операционни системи. Така че, инсталирайте CLI въз основа на вашата операционна система.
За потребители на Linux използвайте командата sudo pip install AWS CLI
Уверете се, че имате версия на python 2.6.5 или по-нова. След изтеглянето го конфигурирайте с помощта на командата за конфигуриране на AWS. След това ще бъдат зададени следните подробности, както е показано по-долу.
AWS Access Key ID (None): #########################
AWS Secret Access Key (None): #########################
Default region name (None): ##################
Default output format (None): ###########
За потребителите на Windows изтеглете подходящия MSI Installer и го стартирайте.
2. Извършвайте операции по Kinesis, използвайки CLI
Моля, обърнете внимание, че потоците от данни на Kinesis не са достъпни за AWS безплатен слой. Така създадените Kinesis потоци ще бъдат таксувани.
Сега нека да видим някои кинезисни операции в CLI.
- Създайте поток
Създайте поток KStream със Shard count 2, като използвате следната команда.
aws kinesis create-stream --stream-name KStream --shard-count 2
Проверете дали потокът е създаден.
aws kinesis describe-stream --stream-name KStream
Ако е създаден, ще се появи изход, подобен на следващия пример.
(
"StreamDescription": (
"StreamStatus": "ACTIVE",
"StreamName": " KStream ",
"StreamARN": ####################,
"Shards": (
(
"ShardId": #################,
"HashKeyRange": (
"EndingHashKey": ###################,
"StartingHashKey": "0"
),
"SequenceNumberRange": (
"StartingSequenceNumber": "###################"
)
)
) )
)
- Поставете запис
Сега, запис на данни може да бъде поставен с помощта на команда put-record. Тук в потока се вкарва запис, съдържащ тест за данни.
aws kinesis put-record --stream-name KStream --partition-key 456 --data test
Ако вмъкването е успешно, изходът ще бъде показан, както е показано по-долу.
(
"ShardId": "#############",
"SequenceNumber": "##################"
)
- Вземете запис
Първо, потребителят трябва да получи итератора на шрамове, който представлява позицията на потока за шейда.
aws kinesis get-shard-iterator --shard-id shardId-########## --shard-iterator-type TRIM_HORIZON --stream-name KStream
След това изпълнете командата, като използвате получения итератор на осколки.
aws kinesis get-records --shard-iterator ###########
Получава се извадка от извадката, както е показано по-долу.
(
"Records":( (
"Data":"######",
"PartitionKey":"456”,
"ApproximateArrivalTimestamp": 1.441215410867E9,
"SequenceNumber":"##########"
) ),
"MillisBehindLatest":24000,
"NextShardIterator":"#######"
)
- Почисти
За да избегнете такси, създаденият поток може да бъде изтрит с помощта на командата по-долу.
aws kinesis delete-stream --stream-name KStream
заключение
AWS Kinesis е платформа, която събира, обработва и анализира поточни данни за няколко приложения като машинно обучение, прогнозна анализа и т.н. Данните за поточно предаване могат да бъдат във всеки формат като аудио, видео, данни от сензори и т.н.
Препоръчителни статии
Това е ръководство за AWS Kinesis. Тук обсъждаме как да използваме AWS Kinesis, а също и нейното обслужване с работа и архитектура. Можете също да разгледате следната статия, за да научите повече -
- AWS Архитектура
- Какво е AWS Lambda?
- Технологии за големи данни
- Архитектура за добив на данни
- Услуги за съхранение на AWS
- Ръководство за конкурентите на AWS с функции