

Разлика между големите данни и Apache Hadoop
Всичко е в Интернет. В Интернет има много данни. Следователно всичко е Big Data. Знаете ли, че 2, 5 Quintillion байтови данни се създават всеки ден и се събират като големи данни? Нашите ежедневни дейности като коментари, харесвания, публикации и т.н. в социални медии като Facebook, LinkedIn, Twitter и Instagram се добавят като големи данни. Предполага се, че до 2020 г. ще се създават почти 1, 7 мегабайта данни всяка секунда за всеки човек на земята. Можете да си представите и помислите колко данни се генерират, като се предполага, че всеки един човек на земята. Днес сме свързани и споделяме живота си онлайн. Повечето от нас са свързани онлайн. Живеем в умен дом и използваме интелигентни превозни средства и всички са свързани с нашите смарт телефони. Представяте ли си как тези устройства стават умни? Бих искал да ви дам много прост отговор, защото се прави анализ на много голямото количество данни, т.е. Big Data. В рамките на пет години в света ще има над 50 милиарда умно свързани устройства, всички разработени за събиране, анализиране и споделяне на данни, за да направим живота си по-комфортен.
Следват въвеждането на големи данни срещу Apache Hadoop
Въвеждане на термин Големи данни
Какво е Big Data? Какъв размер на данните се счита за голям и ще бъде наречен Big Data? Имаме много относителни предположения за термина Big Data. Възможно е количеството данни, например 50 терабайта, да се счита за големи данни за Start-up, но може да не е Big Data за компании като Google и Facebook. Това е така, защото те имат инфраструктурата да съхраняват и обработват това количество данни. Бих искал да определя термина Big Data като:
- Big Data е количеството данни, което е над възможностите на технологията да съхраняват, управляват и обработват ефективно.
- Big Data са данни, чийто мащаб, разнообразие и сложност изискват нова архитектура, техники, алгоритми и анализи, за да я управляват и извличат от нея стойност и скрити знания.
- Големите данни са информационни активи с голям обем и скорост и високо разнообразие, които изискват рентабилни иновативни форми на обработка на информацията, които дават възможност за по-добра представа, вземане на решения и автоматизация на процесите.
- Big Data се отнася до технологии и инициативи, които включват твърде много разнообразни, бързо променящи се или масови данни, за да могат ефективно да се справят с конвенционалните технологии, умения и инфраструктура. Казано по различен начин, обемът, скоростта или разнообразието от данни е твърде голям.
3 V на големи данни
- Обем: Обемът се отнася до количеството / количеството, при което се създават данни като на всеки час, транзакциите на клиентите на Wal-Mart предоставят на компанията около 2, 5 петабайта данни.
- Скорост: Скоростта се отнася до скоростта, с която данните се движат, като потребителите на Facebook изпращат средно 31, 25 милиона съобщения и разглеждат 2, 77 милиона видеоклипове всяка минута през интернет всеки ден.
- Разнообразие: Разнообразието се отнася до различни формати на данни, които се създават като структурирани, полуструктурирани и неструктурирани данни. Подобно изпращането на имейли с прикачен файл в Gmail е неструктурирана информация, докато публикуването на коментари с някои външни връзки също се нарича неструктурирани данни. Споделянето на снимки, аудиоклипове, видеоклипове са неструктурирана форма на данни.
Съхраняването и обработката на този огромен обем, скорост и разнообразие от данни е голям проблем. Трябва да мислим за друга технология, различна от RDBMS за Big Data. Това е така, защото RDBMS е в състояние да съхранява и обработва само структурирани данни. Така че тук Apache Hadoop идва като спасение.
Представяме Ви термин Apache Hadoop
Apache Hadoop е софтуерна рамка с отворен код за съхранение на данни и стартиране на приложения в клъстери от стоков хардуер. Apache Hadoop е софтуерна рамка, която позволява разпределената обработка на големи масиви от данни в групи от компютри, използвайки прости модели за програмиране. Той е проектиран да мащабира от единични сървъри до хиляди машини, всяка от които предлага локални изчисления и съхранение. Apache Hadoop е рамка за съхранение и обработка на големи данни. Apache Hadoop е в състояние да съхранява и обработва всички формати на данни като структурирани, полуструктурирани и неструктурирани данни. Apache Hadoop е отворен код и стоков хардуер донесе революция в ИТ индустрията. Той е лесно достъпен за всички нива на компаниите. Не е необходимо да инвестират повече за създаване на клъстер Hadoop и за различна инфраструктура. Така че нека да видим подробно полезната разлика между Big Data и Apache Hadoop в тази публикация.
Рамка Apache Hadoop
Рамката Apache Hadoop е разделена на две части:
- Hadoop Разпределена файлова система (HDFS): Този слой е отговорен за съхраняването на данни.
- MapReduce: Този слой е отговорен за обработката на данни на Hadoop Cluster.
Hadoop Framework е разделена на главна и робска архитектура. Слой на име Hadoop разпределена файлова система (HDFS) Node е главен компонент, докато Data Node е Slave компонент, докато в слой MapReduce Job Tracker е главен компонент, докато проследяващият задачи е подчинен компонент. По-долу е диаграмата за рамката на Apache Hadoop.
Защо Apache Hadoop е важен?
- Възможност за бързо съхранение и обработка на огромни количества от всякакъв вид данни
- Изчислителна мощност: разпределеният изчислителен модел на Hadoop бързо обработва големи данни. Колкото повече изчислителни възли използвате, толкова повече мощност на обработка имате.
- Толерантност на грешките: Обработката на данни и приложения е защитена срещу повреда в хардуера. Ако даден възел спадне, заданията автоматично се пренасочват към други възли, за да се гарантира, че разпределените изчисления не се провалят. Множеството копия на всички данни се съхраняват автоматично.
- Гъвкавост: Можете да съхранявате колкото искате данни и да решите как да ги използвате по-късно. Това включва неструктурирани данни като текст, изображения и видеоклипове.
- Ниска цена: рамката с отворен код е безплатна и използва стоков хардуер за съхранение на големи количества данни.
- Мащабируемост: Можете лесно да разраствате системата си, за да обработва повече данни, просто като добавите възли. Изисква се малко администрация
Сравнение между главата на големите данни срещу Apache Hadoop (Инфографика)
По-долу е топ 4 сравнението между Big Data срещу Apache Hadoop
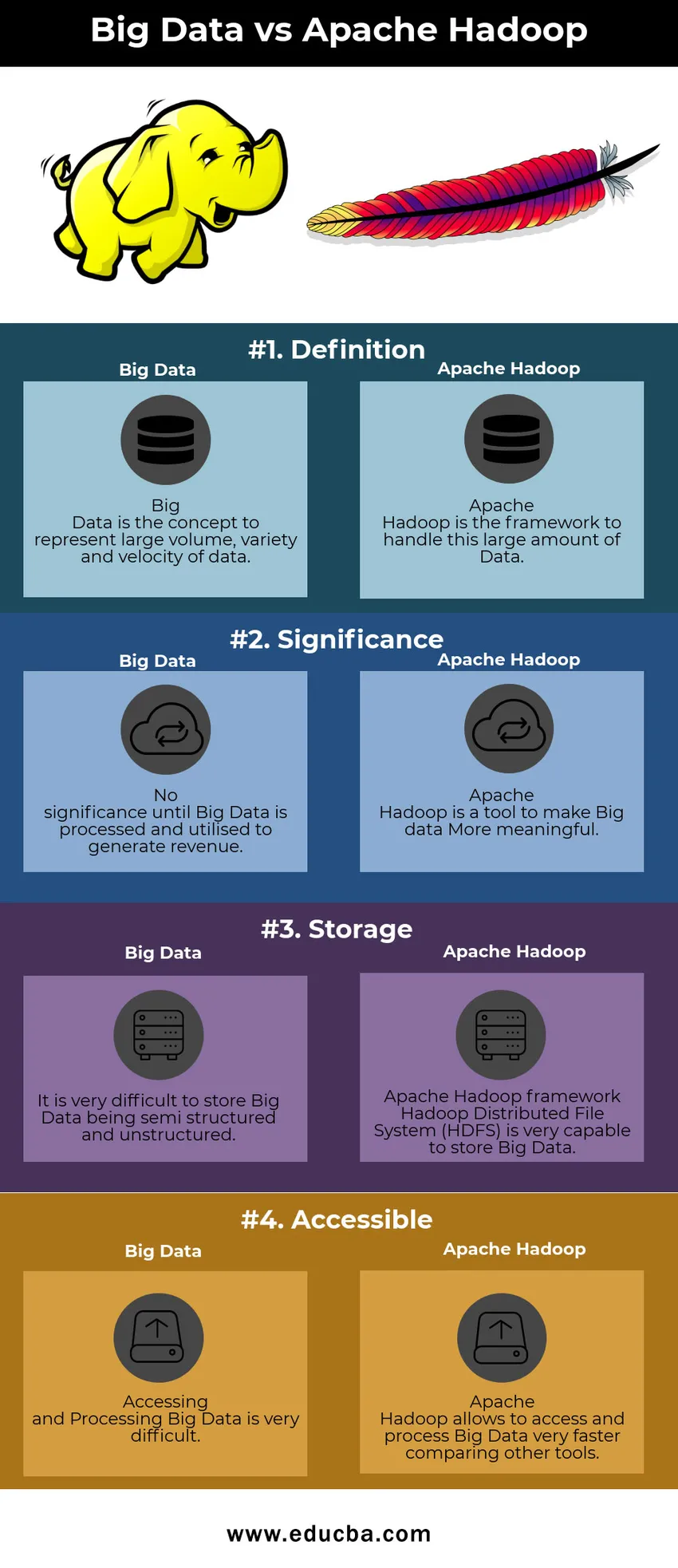
Таблица за сравнение на големи данни срещу Apache Hadoop
Обсъждам основните артефакти и разграничавам Big Data срещу Apache Hadoop
| Голяма информация | Apache Hadoop | |
| дефиниция | Big Data е концепцията за представяне на голям обем, разнообразие и скорост на данните | Apache Hadoop е рамката за работа с този голям обем данни |
| значение | Няма значение, докато Big Data не се обработват и използват за генериране на приходи | Apache Hadoop е инструмент за по-голямо значение на големите данни |
| съхранение | Много е трудно съхраняването на Big Data да е полуструктурирано и неструктурирано | Рамка Apache Hadoop Разпределената файлова система (HDFS) е много способна да съхранява големи данни |
| достъпен | Достъпът и обработката на големи данни е много труден | Apache Hadoop позволява достъп и обработка на Big Data много по-бързо, сравнявайки други инструменти |
Заключение - Големи данни срещу Apache Hadoop
Не можете да сравните Big Data и Apache Hadoop. Причината е, че Big Data е проблем, докато Apache Hadoop е решение. Тъй като количеството данни се увеличава експоненциално във всички сектори, така че е много трудно да се съхраняват и обработват данни от една система. За да обработим този голям обем данни, се нуждаем от разпределена обработка и съхраняване на данни. Затова Apache Hadoop предлага решение за съхранение и обработка на много голямо количество данни. Най-накрая ще заключа, че Big Data е голямо количество сложни данни, докато Apache Hadoop е механизъм за съхранение и обработка на големи данни много ефективно и гладко.
Препоръчителен член
Това е ръководство за Big Data vs Apache Hadoop, тяхното значение, сравнение между главата, ключови разлики, таблица на сравнението и заключение. тази статия се състои от всички полезни разлики между Big Data и Apache Hadoop. Можете също да разгледате следните статии, за да научите повече -
- Big Data vs Data Science - как са различни?
- Топ 5 големи тенденции на данни, които компаниите ще трябва да овладеят
- Hadoop vs Apache Spark - интересни неща, които трябва да знаете
- Apache Hadoop срещу Apache Spark | Топ 10 сравнения, които трябва да знаете!