

Въведение в AWS EMR
AWS EMR предоставя много функционалности, които ни улесняват, някои от технологиите са:
- Amazon EC2
- Amazon RDS
- Amazon S3
- Amazon CloudFront
- Автоматично мащабиране на Amazon
- Амазонка Ламбда
- Амазонка Redshift
- Amazon Elastic MapReduce (EMR)
Една от основните услуги, предоставяни от AWS EMR и с която ще се занимаваме, е Amazon EMR.
EMR, обикновено наричана Elastic Map Reduce, идва с лесен и достъпен начин за справяне с обработката на по-големи парчета данни. Представете си сценарий с големи данни, при който имаме огромно количество данни и извършваме набор от операции над тях, да речем, че задачата за намаляване на картата се изпълнява, един от основните проблеми, пред които е изправено приложението Bigdata, е настройката на програмата, ние често ни е трудно да прецизираме програмата си по такъв начин, че целият разпределен ресурс се изразходва правилно. Поради този по-горе коефициент на настройка, времето за обработка нараства постепенно. Еластична карта Намалете услугата от Amazon, е уеб услуга, която предоставя рамка, която управлява всички тези необходими функции, необходими за обработката на големи данни по рентабилен, бърз и сигурен начин. От създаването на клъстери до разпространението на данни в различни случаи всички тези неща се управляват лесно чрез Amazon EMR. Услугите тук са по заявка означава, че можем да контролираме номерата въз основа на данните, които имаме, което прави, ако е рентабилно и мащабируемо.
Причини за използване на AWS EMR
Така че защо да използвате AMR какво го прави по-добър от другите. Често срещаме много основен проблем, при който не можем да разпределим всички ресурси, налични през клъстера, за всяко приложение, AMAZON EMR се грижи за тези проблеми и въз основа на размера на данните и търсенето на приложението разпределя необходимия ресурс. Също така, бидейки еластичен по природа, можем да го променим съответно. EMR има огромна поддръжка на приложения, било то Hadoop, Spark, HBase, което улеснява обработката на данни. Той поддържа различни ETL операции бързо и рентабилно. Може да се използва и за MLIB в Spark. Можем да изпълняваме различни алгоритми за машинно обучение вътре в него. Независимо дали става дума за пакетни данни или поточно предаване на данни в реално време EMR е в състояние да организира и обработва двата типа данни.
Работа на AWS EMR
Сега нека видим тази диаграма на Amazon EMR клъстера и ще се опитаме да разберем как всъщност работи:
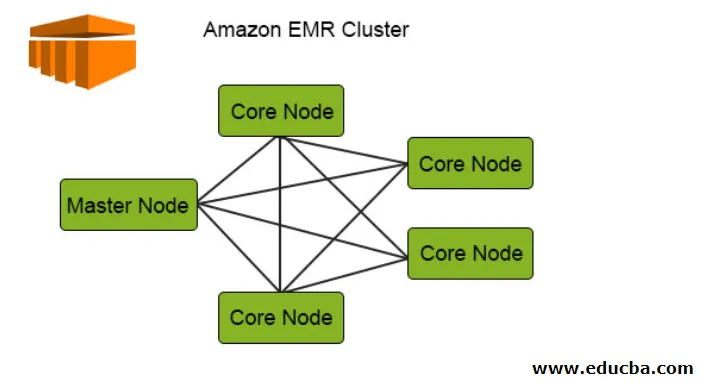
Следващата диаграма изобразява разпределението на клъстера в EMR. Нека да проверим тази подробност:
1. Клъстерите са централният компонент в EMR архитектурата на Amazon. Те са колекция от EC2 инстанции, наречени възли. Всеки възел има своите специфични роли в клъстера, наречен тип Node и въз основа на техните роли можем да ги класифицираме в 3 типа:
- Главен възел
- Основен възел
- Задача на възел
2. Главният възел, както подсказва името, е главният, който е отговорен за управлението на клъстера, изпълнението на компонентите и разпределението на данните през възлите за обработка. Той просто следи дали всичко се управлява правилно и работи добре и работи в случай на повреда.
3. Core Node има отговорността да изпълнява задачата и да съхранява данните в HDFS в клъстера. Всички части за обработка се обработват от основния възел и данните след тази обработка се поставят на желаното HDFS местоположение.
4. Задължителният възел на задачата има само задачата да изпълни задачата, която не съхранява данните в HDFS.
5. Всеки път след подаване на работа имаме няколко метода, за да изберем как трябва да приключат работата. Тъй като това е от прекратяването на клъстера след приключване на заданието до дългогодишен клъстер, използващ EMR конзола и CLI, за да изпратим стъпки, ние имаме цялата привилегия да го направим.
6. Можем директно да стартираме заданието на EMR, като го свържем с главния възел чрез наличните интерфейси и инструменти, които изпълняват задания директно в клъстера.
7. Също така можем да стартираме нашите данни на различни стъпки с помощта на EMR, всичко, което трябва да направим, е да изпратим една или повече подредени стъпки в EMR клъстера. Данните се съхраняват като файл и се обработват последователно. Започвайки от „Изчакващо състояние до завършено състояние“, можем да проследим стъпките на обработка и да открием грешките, също така и от „Неуспешно отменяне“, всички тези стъпки могат лесно да бъдат проследени до това.
8. След като приключи всичкият екземпляр, се постига завършеното състояние за клъстера.
Архитектура за AWS EMR
Архитектурата на EMR се представя, започвайки от частта за съхранение до частта за приложение.
- Първият слой идва със слоя за съхранение, който включва различни файлови системи, използвани с нашия клъстер. Да бъде от HDFS до EMRFS до локална файлова система, всички те се използват за съхранение на данни през цялото приложение. Кеширането на междинните резултати по време на обработката на MapReduce може да се постигне с помощта на тези технологии, които се предлагат с EMR.
- Вторият слой идва с Управление на ресурсите за клъстера, този слой е отговорен за управлението на ресурсите за клъстерите и възлите над приложението. Това основно помага като инструменти за управление, които помагат за равномерното разпределение на данните през клъстера и правилното управление. Инструментът за управление на ресурси по подразбиране, който EMR използва, е YARN, който беше въведен в Apache Hadoop 2.0. Централно управлява ресурсите за множество рамки за обработка на данни. Той се грижи за цялата информация, която е необходима за доброто функциониране на клъстера, като това е от здравето на възлите до разпределението на ресурсите с управление на паметта.
- Третият слой идва с рамката за обработка на данни, този слой е отговорен за анализа и обработката на данни. има много рамки, поддържани от EMR, които играят важна роля в паралелната и ефективна обработка на данни. Някои от рамката, която поддържа и ние сме наясно, е APACHE HADOOP, SPARK, SPARK STREAMING и т.н.
- Четвъртият слой се състои от Приложението и програми като HIVE, PIG, библиотека за стрийминг, ML Алгоритми, които са полезни за обработка и управление на големи масиви от данни.
Предимства на AWS EMR
Нека сега проверим някои от предимствата на използването на EMR:
- Висока скорост: Тъй като всички ресурси се използват правилно, времето за обработка на заявката е сравнително по-бързо, отколкото останалите инструменти за обработка на данни имат много ясна картина.
- Групова обработка на данни: По-голям размер на данните EMR има възможност за обработка на огромно количество данни за достатъчно време.
- Минимална загуба на данни: Тъй като данните се разпределят в клъстера и се обработват паралелно по мрежата, има минимален шанс за загуба на данни и добре, степента на точност на обработените данни е по-добра.
- Ефективна цена : Като е рентабилна, тя е по-евтина от всяка друга налична алтернатива, която я прави силна за използване в индустрията. Тъй като ценообразуването е по-малко, можем да поберем над големи количества данни и да ги обработим в рамките на бюджета.
- AWS Integrated: Той е интегриран с всички услуги на AWS, което прави лесната наличност под покрив, така че сигурността, съхранението, работата в мрежа всичко е интегрирано на едно място.
- Сигурност: Предлага се с невероятна група за сигурност за контрол на входящия и изходящия трафик, а използването на IAM Roles го прави по-сигурен, тъй като предлага различни разрешения, които правят данните защитени.
- Мониторинг и внедряване: разполагаме с подходящи инструменти за мониторинг за цялото приложение, което работи над EMR клъстери, което го прави прозрачен и лесен за част от анализа, освен това идва с функция за автоматично внедряване, където приложението се конфигурира и разгръща автоматично.
Има много повече предимства от използването на EMR като по-добър избор на друг метод за изчисляване на клъстери.
AWS EMR цени
EMR се предлага с невероятна ценова листа, която привлича разработчиците или пазара към нея. Тъй като той предлага функция за ценообразуване при поискване, можем да го използваме малко повече от час и брой възли в нашия клъстер. Можем да платим за секунда ставка за всяка секунда, която използваме с една минута като минимум. Също така можем да изберем нашите инстанции да се използват като резервирани инстанции или точкови инстанции, като мястото е значително икономия.
Можем да изчислим общата сметка чрез обикновен месечен калкулатор от линка по-долу: -
https://calculator.s3.amazonaws.com/index.html#s=EMR
За повече подробности относно точните подробности за цените можете да се обърнете към документа по-долу от Amazon: -
https://aws.amazon.com/emr/pricing/
заключение
От горната статия видяхме как EMR може да се използва за честна обработка на големи данни, като всички ресурси се използват условно.
Наличието на EMR решава основния ни проблем с обработката на данни и намалява много времето за обработка с голям брой, като е рентабилен, той е лесен и удобен за използване.
Препоръчителен член
Това е ръководство за AWS EMR. Тук обсъждаме въведение в AWS EMR заедно с неговите Работни и Архитектура, както и Предимствата. Можете да разгледате и другите ни предложени статии, за да научите повече -
- AWS Алтернативи
- AWS Команди
- AWS услуги
- Въпроси за интервю на AWS
- Услуги за съхранение на AWS
- Топ 7 състезатели на AWS
- Списък на функциите на Amazon Web Services