
Въведение в ансамбълните техники
Ансамбълното обучение е техника в машинното обучение, която се използва с помощта на няколко базови модела и комбинира изхода им за създаване на оптимизиран модел. Този тип алгоритъм за машинно обучение помага за подобряване на цялостната работа на модела. Тук базовият модел, който най-често се използва, е класификаторът на дървото на решенията. Дървото на решенията основно работи на няколко правила и осигурява предсказуем изход, където правилата са възлите и техните решения ще бъдат техните деца, а листовите възли ще представляват крайното решение. Както е показано в примера на дърво за решения.
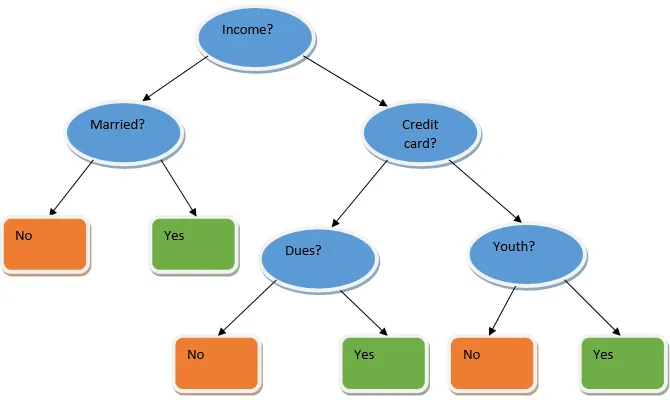
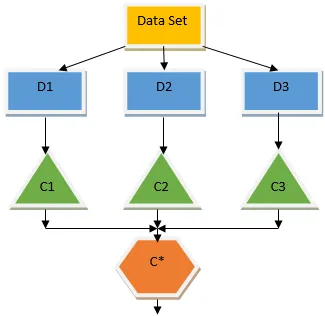
Горното дърво за решения основно говори за това дали на човек / клиент може да бъде даден заем или не. Едно от правилата за допустимост на кредита да е, че ако (доход = Да && Женен = Не), тогава Заем = Да, така че така работи класификаторът на дървото за решения. Ще включим тези класификатори като множество базови модели и ще комбинираме техния изход, за да изградим един оптимален предсказуем модел. Фигура 1.b показва общата картина на алгоритъм за обучение на ансамбъла.
Видове техники на ансамблите
Различни видове ансамбли, но основният ни акцент ще бъде върху следните два типа:
- зебло
- Увеличаване
Тези методи помагат за намаляване на дисперсията и пристрастията в модела на машинно обучение. Сега нека се опитаме да разберем какво е пристрастие и различие. Пристрастието е грешка, която възниква поради неправилни предположения в нашия алгоритъм; високото отклонение показва, че моделът ни е твърде прост / недостатъчен. Вариант е грешката, която е причинена поради чувствителността на модела към много малки колебания в набора от данни; висока дисперсия показва, че моделът ни е много сложен / превъзходен. Идеалният модел на ML трябва да има подходящ баланс между пристрастия и отклонение.
Агрегиране / Bagingstrap Bootstrap
Baging е ансамблова техника, която помага за намаляване на дисперсията в нашия модел и по този начин избягва прекаляването. Багажът е пример за алгоритъма за паралелно обучение. Багирането работи на два принципа.
- Начално зареждане: От първоначалния набор от данни се вземат предвид различни популации от проби със заместване.
- Агрегиране: усредняване на резултатите от всички класификатори и предоставяне на единичен изход, за това той използва гласуване с мнозинство в случай на класификация и осредняване в случай на проблем с регресията. Един от известните алгоритми за машинно обучение, който използва концепцията за опаковане, е случайна гора.
Случайна гора
В случайна гора от случайната извадка, изтеглена от популацията с подмяна и подмножество от функции се избира от множеството на всички функции, изградено е дърво за решения. От тези подмножества от функции, която функция дава най-доброто разделяне, се избира като корен за дървото на решенията. Подмножеството от функции трябва да бъде избрано на случаен принцип на всяка цена, в противен случай ще произведем само корелиран трес и дисперсията на модела няма да бъде подобрена.
Сега изградихме нашия модел с пробите, взети от населението, въпросът е как да валидираме модела? Тъй като ние обмисляме пробите със замяна, следователно всички проби няма да бъдат взети под внимание и някои от тях няма да бъдат включени във всяка торба, те се извикват от проби от торби. Можем да утвърдим нашия модел с тези OOB (извън опаковката) проби. Важните параметри, които трябва да се вземат предвид в произволна гора, са броят на пробите и броят на дърветата. Нека разгледаме „m“ като подмножеството от функции, а „p“ е пълният набор от функции, сега като правило за палеца, винаги е идеално да изберете
- m as√и минимален размер на възела като 1 за проблем с класификацията.
- m като P / 3 и минимален размер на възела, за да бъде 5 за проблем с регресията.
M и p трябва да се разглеждат като настройки на параметрите, когато имаме работа с практически проблем. Обучението може да бъде прекратено, след като грешката на OOB се стабилизира. Един недостатък на случайната гора е, че когато имаме 100 функции в нашия набор от данни и само няколко функции са важни, този алгоритъм ще се представи лошо.
Увеличаване
Увеличаването е последователен алгоритъм за учене, който помага за намаляване на пристрастия в нашия модел и дисперсия в някои случаи на контролирано обучение. Освен това помага за превръщането на слабите учащи се в силни учащи се. Увеличаването работи на принципа за последователно поставяне на слабите учащи се и придава тежест на всяка точка от данни след всеки кръг; повече тежест се присвоява на погрешно класифицираните данни в предишния кръг. Този последователен претеглен метод за обучение на нашия набор от данни е ключовата разлика за този на пакетирането.
Fig3.a показва общия подход за стимулиране
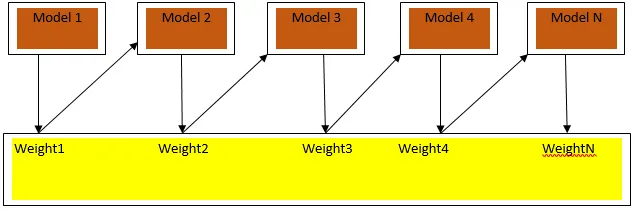
Окончателните прогнози се комбинират въз основа на гласуване с претеглено мнозинство в случай на класификация и претеглена сума в случай на регресия. Най-широко използваният алгоритъм за повишаване е адаптивното усилване (Adaboost).
Адаптивно усилване
Стъпките, участващи в алгоритъма на Adaboost, са следните:
- За дадените n точки от данни ние определяме целевия клас и инициализираме всички тегла до 1 / n.
- Подхождаме класификаторите към набора от данни и избираме класификацията с най-малко претеглената класификационна грешка
- Присвояваме теглата за класификатора с правило за палеца въз основа на точността, ако точността е повече от 50%, тогава теглото е положително и обратно.
- Актуализираме теглата на класификаторите в края на итерацията; актуализираме повече тежест за погрешно класифицираната точка, така че в следващата итерация да я класифицираме правилно.
- След цялата итерация получаваме крайния резултат на прогнозата въз основа на мажоритарната / претеглената средна стойност.
Adaboosting работи ефективно със слаби (по-малко сложни) учащи се и с високи класификатори на пристрастия. Основните предимства на Adaboosting са, че той е бърз, няма параметри на настройка, подобни на случая с пакетиране и не правим никакви предположения за слаби учащи се. Тази техника не дава точен резултат кога
- В нашите данни има повече хора, които остават.
- Наборът от данни е недостатъчен.
- Слабите учащи са силно сложни.
Те са чувствителни и към шум. Дърветата с решения, които се получават в резултат на усилване, ще имат ограничена дълбочина и висока точност.
заключение
Антенните техники за обучение се използват широко за подобряване на точността на модела; трябва да решим коя техника да използваме въз основа на нашия набор от данни. Но тези техники не се предпочитат в някои случаи, когато интерпретируемостта е от значение, тъй като губим интерпретируемостта с цената на подобряване на производителността. Те имат огромно значение в сектора на здравеопазването, където малко подобрение в работата е много ценно.
Препоръчителни статии
Това е ръководство за ансамбълните техники. Тук обсъждаме въвеждането и два основни типа техники на ансамбъла. Можете също да разгледате и другите ни свързани статии, за да научите повече-
- Технологии за стеганография
- Техники за машинно обучение
- Техники за изграждане на екип
- Алгоритми за научни данни
- Най-използваните техники на ансамбълното обучение