

Какво е функция на кошера?
Както знаем днес, Hadoop е една от многостранните технологии в големите данни. Hadoop има възможност да се справи с голям набор от данни, но тъй като растежът на данните е пропорционален, писането на програми за намаляване на карти става трудно. За да изпълнява SQL заявки, присъстващи в HDFS, една такава технология беше въведена от Hadoop, наречена apache Hive, стартирана от Facebook. Hive се използва изключително от анализатора на данни. Те са разгърнати за три функции, а именно: Обобщаване на данни, анализ на данни за разпределен файл и заявка на данни. Hive предоставя SQL като заявки, наречени HQL - висок език за заявки поддържа DML, определени от потребителя функции. Компилаторът на Hive преобразува вътрешно тази заявка в работни места за намаляване на карти, което опростява работата на Hadoop при писането на сложни програми. Бихме могли да намерим кошер в приложение като съхранение на данни, визуализация на данни и ad-hoc анализ, google analytics. Ключовото предимство е, че те използват SQL знания, което е основно умение, прилагано от специалисти по данни и софтуерни специалисти.
Различни функции на кошера
Hive поддържа различни типове данни, които не се срещат в други системи от бази данни. тя включва карта, масив и структура. Hive има някои вградени функции за изпълнение на няколко математически и аритметични функции със специална цел. Функциите в кошера могат да бъдат категоризирани в следните видове. Те са вградени функции и дефинирани от потребителя функции.
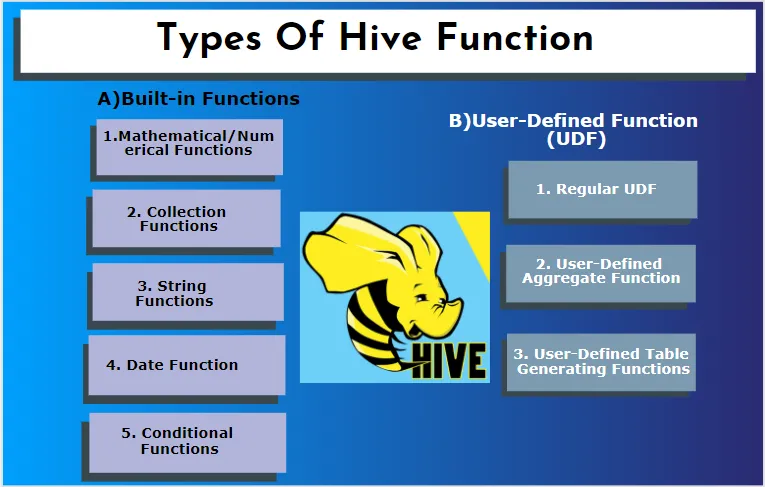
A) Вградени функции
Тези функции извличат данни от таблиците на кошера и обработват изчисленията. Някои от вградените функции са:
1. Математически / цифрови функции
Тези функции се използват главно за математически изчисления. Тези функции се използват в SQL заявки.
| Име на функция | пример | описание |
| ABS (двойно x) | Кошера> изберете ABS (-200) от tmp; | Той ще върне абсолютната стойност на число. |
| CEIL (двойно x) | Кошера> изберете CEIL (8.5) от tmp; | Той ще получи най-малкото цяло число, по-голямо или равно на стойност x. |
| Rand (), rand (int семе) | Кошера> изберете Rand () от tmp;
Ранд (0-9) | Той връща произволно число, зависи от стойността на семената, които произволните числа биха били детерминирани. |
| Pow (двойно x, двойно y) | Кошера> изберете Pow (5, 2) от tmp; | Тя връща x стойност, повдигната на y мощността. |
| ЕТАЖ (двойно y) | Кошера> изберете ЕТАЖ (11.8) от tmp; | Тя връща максимално цяло число по-малко или равно, за да даде стойност y. |
| EXP (двоен а) | Кошера> изберете Exp (30) от tmp; | Той ще върне стойността на експонента от 30. стойностите на естествения алгоритъм. |
| PMOD (int a, int b) | Кошера> изберете PMOD (2, 4) от tmp; | Той дава положителния модул на числото. |
2. Функции за събиране
Изхвърлянето на всички елементи заедно и връщането на единични елементи зависи от включения тип данни.
| Име на функция | пример | описание |
| Map_values (Карта) | Кошера> изберете стойности на картата ('hi', 45) | Извлича нередовни елементи от масива. |
| Размер (карта) | Кошера> изберете размер (карта) | Връща броя на елементите в картата на типа данни. |
| Array_contains (масив b) | Кошера> изберете array_contains (a (10)) | Връща TRUE, ако масивът съдържа стойността. |
| Sort_array (масив a) | Кошера> изберете sort_array ((10, 3, 6, 1, 7)) | Сортира входния масив във възходящ ред според естествения ред на елементите от масива и връща стойността. |
3. Струнни функции
Използването на низови функции анализът на данните се извършва отлично.
| Разделяне (string s, string pat) | Кошера> изберете сплит ('educba ~ кошер ~ Hadoop, ' ~ ') изход: ("educba", "кошер", "Hadoop") | Разделя низа около изразите на pat и връща масив. |
| зареждане (string s, int Len, подложка за низ) | Кошера> изберете товар ('EDUCBA', 6, 'H') | Връща низове с десен подплънки с дължината на низа. (характер на подложката). |
| Дължина (низ) | Кошера> изберете дължина ('educba') | Тази функция връща дължината на низа. |
| Rtrim (низ a) | Кошера> изберете rtrim ('TOPIC');
Резултат: „Тема“ | Връща резултата, като изрязва интервали от десните краища. |
| Concat (низ m, низ n) | Кошера> изберете concat ('data', 'ware') Резултат: Dataware | Резултатът е в низа, като се свързват два низа, това може да отнеме произволен брой входове. |
| Обратно (низ) | Кошера> изберете заден ход („Мобилен“) | Връща резултата от обърнат низ. |
4. Функция за дата
Необходимо е да има формат данни в кошера, за да се предотврати нулева грешка в изхода. Необходимо е да има съвместимост с датата, за да вървите с функциите за дата на кошера.
| Unix_timestamp (дата на низа, модел на низ) | Кошер> изберете Unix_ timestamp ('2019-06-08', 'yyyy-mm-dd'); Резултат: 124576 400 отнемано време: 0, 146 секунди | Тази функция връща датата в специфичния формат и връща секунди между дата и Unix времена. |
| Unix_timestamp (дата на низа) | Кошер> изберете Unix_ timestamp ('2019-06-08 09:20:10', 'yyyy-mm-dd'); | Тя връща датата във формат „yyyy-MM-dd HH: mm: ss“ във времевата марка Unix. |
| Час (дата на низ) | Кошер> изберете час ('2019-06-08 09:20:10'); Резултат: 09 часа | Връща часа на отметката |
5. Условни функции
| Ако (Булов тест, стойност T е вярна, t неверна) | Кошера> изберете IF (1 = 1, 'TRUE', 'FALSE') като IF_CONDITION_TEST; | Проверява с условието дали стойността е true връща 1, а false false 0. |
| Не е нула (b) | Кошера> Избор не е нула (нула); | Това извлича ненулеви изявления. ако null връща false. |
| Coalesce (стойност1, стойност2) | Пример: кошер> изберете coalesce (Null, null, 4, null, 6). тя връща 4. | Той извлича първо ненулеви стойности от списъка със стойности. |
Б) Дефинирана от потребителя функция (UDF)
Hive използва специфични за потребителя функции според изискванията на клиента, пише се в java програмиране. Той се реализира от два интерфейса, а именно прост API и сложен API. Те се извикват от заявката на кошера. Три вида СДС:
1. Редовен СДС
Работи се на маса с един ред. Създава се чрез създаване на клас java, след което ги пакетирате в .jar файл, следващата стъпка е да се провери с пътя на кошера. след това най-накрая ги изпълнява в запитване на кошер.
2. Дефинирана от потребителя агрегирана функция
Те използват агрегирани функции като avg / mean чрез прилагане на пет метода init (), итерация (), частично (), сливане (), прекратяване ().
3. Дефинирани от потребителя функции за генериране на таблица
Тя работи с един ред в таблица и води до множество редове.
заключение
В заключение, ние научихме как да работим в платформата на кошера с вградени функции и дефинирани от потребителя функции подробно чрез тази статия. Повечето организации имат програмист и SQL разработчик, който да работи върху процеса на сървъра, но кошерът от апаш е мощен инструмент, който им помага да използват рамката на Hadoop без предварително познаване на програмите и намаляване на карти. Hive помага на новите потребители да стартират и изследват анализа на данни без никакви пречки.
Препоръчителни статии
Това е ръководство за функцията на кошера. Тук обсъждаме концепцията, два различни типа функции и подфункции в Hive. Можете да разгледате и другите ни предложени статии, за да научите повече -
- Най-струнните функции в кошера
- Въпроси за интервю на кошера
- Какво е RMAN Oracle?
- Какво е модел водопад?
- Въведение в архитектурата на кошера
- Поръчка на кошера от