
Разлика между кошера и HBase
Apache Hive и HBase са базирани на Hadoop технологии за големи данни. И двамата използваха за търсене на данни. Hive и HBase работят на върха на Hadoop и те се различават по своята функционалност. Hive е базиран на намаляване SQL диалект, докато HBase поддържа само MapReduce. HBase съхранява данни под формата на двойки ключ / стойност или колони, докато Hive не съхранява данни.
Разлики между главата на Hive срещу HBase (Инфографика)
По-долу е топ 8 разликата между Hive срещу HBase
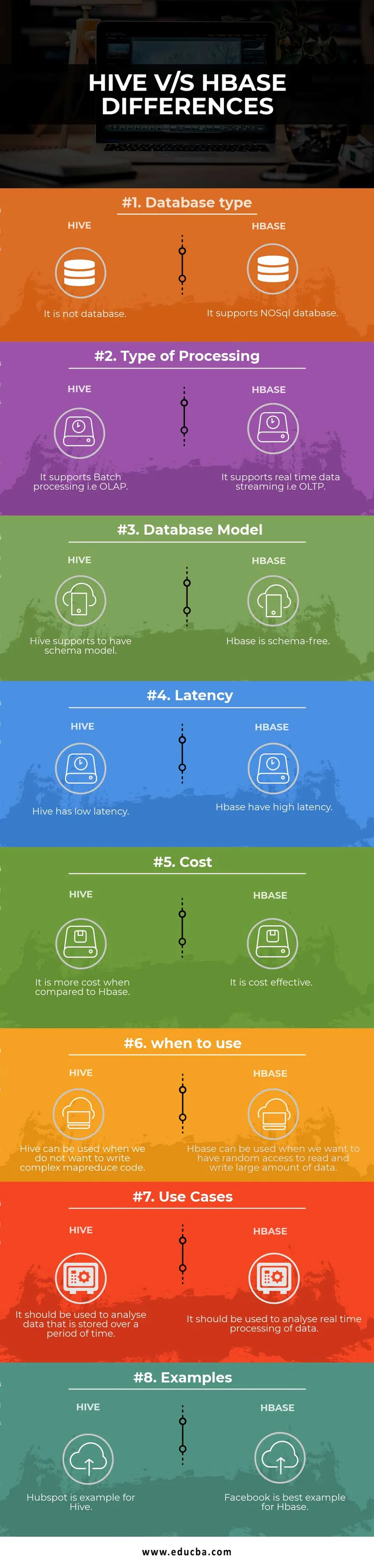
Ключови разлики между Hive срещу HBase
- Hbase е съвместим с ACID, докато кошерът не е.
- Hive поддържа критерии за разделяне и филтриране въз основа на формата на датата, докато HBase поддържа автоматизирано разделяне.
- Hive не поддържа изявления за актуализация, докато HBase ги поддържа.
- Hbase е по-бърз в сравнение с Hive при получаване на данни.
- Hive се използва за обработка на структурирани данни, докато HBase, тъй като е без схеми, може да обработва всякакъв тип данни.
- Hbase е силно (хоризонтално) мащабируем в сравнение с кошера.
- Hive анализира данните на HDFS с поддръжката на SQL заявки и след това те преобразуват това в карта и намаляват задачите, докато в Hbase, тъй като в реално време поточно, той директно извършва своите операции върху базата данни чрез дял на таблици и семейства колони.
- когато идваме при запитването на кошер за данни използва обвивка, известна като Hive shell, за да издаде командите, докато HBase, тъй като е база данни, ще използваме команда за обработка на данните в HBase.
- За да отидем до черупката на Hive ще използваме командния кошер. След като го направите, той ще изглежда като кошер>. В HBase, ние просто даваме като Използвайте HBase.
Таблица за сравняване на кошера срещу HBase
| Основа за сравнение | кошер | Hbase |
| Тип база данни | Това не е база данни | Той поддържа база данни NoSQL |
| Вид обработка | Той поддържа пакетна обработка, т.е. OLAP | Той поддържа поточно предаване на данни в реално време, т.е. OLTP |
| Модел на база данни | Поддържа кошера, за да има модел на схема | Hbase е без схема |
| латентност | Кошера има ниска латентност | Hbase има висока латентност |
| цена | По-скъпо е в сравнение с HBase | Това е рентабилно |
| кога да се използва | Hive може да се използва, когато не искаме да пишем сложен код MapReduce | HBase може да се използва, когато искаме да имаме случаен достъп за четене и записване на голямо количество данни |
| Случаи на употреба | Той трябва да се използва за анализ на данни, които се съхраняват за определен период от време | Той трябва да се използва за анализ на обработката на данни в реално време. |
| Примери | Hubspot е пример за Hive | Facebook е най-добрият пример за Hbase |
Разлики в кодирането между Hive срещу HBase
Нека сега обсъдим основните разлики между Hive и HBase при кодирането.
| Основа за сравнение | кошер | Hbase |
| За да създадете база данни | СЪЗДАВАНЕ НА ДАТАБАЗА (АКО НЕ СЪЩЕСТВУВА) ИМЕНА НА ДАТАБАЗА; | Тъй като Hbase е база данни, не е необходимо да създаваме конкретна база данни |
| За да пуснете база данни | ДАРАБАЗА НА ДРОБА (АКО съществува) ДАТАБАЗА-ИМЕ (ОГРАНИЧЕНИЕ ИЛИ КАСКАД); | NA |
| За да създадете таблица | СЪЗДАВАНЕ (ВРЕМЕННА ИЛИ ВЪНШНА) ТАБЛИЦА (АКО НЕ СЪЩЕСТВЯВА) ТАБЛИЦА ((име на име на колона (коментар на колона-коментар), ….)) (коментар таблица_комментиране) (ROW FORMAT формат на реда) (съхранява се като формат на файла) | СЪЗДАВАНЕ "", "" |
| За да промените таблица | ИЗПЪЛНИТЕ име на ТАБЛИЦА ИЗМЕНЕТЕ НА ново име
ALTER TABLE име DROP (COLUMN) - име на колона ALTER TABLE name ADD COLUMNS (col-spec (, col-spec ..)) ALTER TABLE name ПРОМЯНА на името на колоната new-name new-type ИЗПОЛЗВАНЕ НА ИЗБОРА НА ТАБЛИЦА ЗАМЕНА КОЛОНИ (col-spec (, col-spec ..)) | ALTER 'TABLE-NAME', NAME => 'COLUMN-NAME', VERSIONS => |
| Деактивиране на таблица | NA | деактивирайте „TABLE-NAME“ ->, за да деактивирате зададено име на таблица
enable_all 'r *' -> за деактивиране на всички таблици, които съответстват на правилния израз |
| Активиране на таблица | NA | активирайте „TABLE-NAME“ |
| За да пуснете таблица | ПАРАДЕТЕ ТАБЛИЦА, АКО ИМА ТАБЛИЦА | Ако искаме да пуснем таблица, тогава първо трябва да я деактивираме
деактивирайте „име на таблица“ пуснете „таблица-име“ По подобен начин можем да използваме disabled_all и drop_all, за да изтрием таблиците, които съответстват на определения редовен израз. |
| За списък на бази данни | показване на бази данни; | NA |
| За да изброите таблици в базата данни | покажете таблици; | списък |
| За да опишете схема на таблица | опишете името на таблицата; | опишете „име на таблица“ |
Интеграция на Hive срещу HBase
- Инсталирайте и конфигурирайте Hive.
- Инсталиране и конфигуриране на HBase.
- За интегриране както на кошер, така и на HBase, ние използваме СЪХРАНЕНИЕ НА СЪХРАНЕНИЕ в кошер.
- Манипулатори за съхранение е комбинация от SERDE, InputFormat, OutputFormat, която приема всяко външно образувание като таблица в Hive.
- Така че тази функция помага на потребителя да издава SQL заявки, независимо дали таблицата присъства в Hadoop или в базата данни, базирана на NOSQL, като HBase, MongoDB, Cassandra, Amazon DynamoDB.
- Сега ще разгледаме един пример за свързване на Hive с HBase с помощта на HiveStorageHandler:
- Първо, трябва да създадем Hbase таблица с помощта на командата.
създайте „Студент“, „лична информация“, „информация за отдел“
-> Лична информация и информация за отдел създават две различни семейства от колони в таблицата за ученици.
- Трябва да вмъкнем някои данни в таблицата на Student. Например, както беше споменато по-долу.
поставете 'студент', 'sid01', 'personalinfo: име', 'Ram'
поставете 'student', 'sid01', 'personalinfo: mailid', ' '
поставете 'student', 'sid01', 'deptinfo: deptname', 'Java'
поставете 'Студент', 'sid01', 'deptinfo: joinyear', '1994'
-> По подобен начин можем да създадем данни за sid02, sid03…
- Сега трябва да създадем таблица Hive, сочеща към таблицата HBase.
- За всяка колона в Hbase ще създадем една конкретна таблица за тази колона в Hive.В този случай ще създадем 2 таблици в Hive
create external table student_hbase(sid String, name String, mailid String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler with serdeproperties("hbase.columns.mapping"=":key, personalinfo:name, personalinfo:mailid")
tblproperties("hbase.table.name"="student");
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
-> По подобен начин трябва да създадем таблица с подробности за информация в кошера.
- Сега можем да напишем SQL заявка в кошер, както е споменато по-долу.
select * from student_hbase;
По този начин можем да интегрираме Hive с HBase.
Заключение - Hive срещу HBase
Както беше обсъдено, и двете са различни технологии, които осигуряват различни функционалности, при които Hive работи, използвайки SQL език и може да се нарече също така, когато HQL и HBase използват двойки ключ-стойност за анализ на данните. Hive и HBase работят по-добре, ако са комбинирани, тъй като Hive имат ниска латентност и могат да обработват огромно количество данни, но не могат да поддържат актуални данни и HBase не поддържа анализ на данни, но поддържа актуализации на ниво ред на голямо количество на данни.
Препоръчителен член
Това е ръководство за Hive срещу HBase, тяхното значение, сравнение между главата, ключови разлики, таблица на сравнението и заключение. Можете също да разгледате следните статии, за да научите повече -
- Apache Pig vs Apache Hive - Топ 12 полезни разлики
- Разберете 7-те най-добри разлики между Hadoop срещу HBase
- Топ 12 Сравнение на Apache Hive с Apache HBase (Инфографика)
- Hadoop срещу кошера - открийте най-добрите разлики