

Въведение в архитектурата Hadoop
Hadoop Architecture е рамка с отворен код, която помага при лесната обработка на големи набори от данни. Той помага при създаването на приложения, които обработват огромни данни с по-голяма скорост. Той използва разпределените изчислителни концепции, при които данните се разпространяват в различни възли на клъстер. Приложенията, които са изградени с помощта на Hadoop, използват стокови компютри. Тези компютри се предлагат лесно на пазара на евтини цени. Този резултат е постигане на по-голяма изчислителна мощност с ниска цена. Всички налични данни в Hadoop пребивават в HDFS вместо в локална файлова система. HDFS е разпределена файлова система на Hadoop. Този модел се основава на локалността на данните, където изчислителната логика се изпраща до възлите, присъстващи в клъстер, който съдържа данните. Тази логика не е нищо друго освен логика, която компилира програмата.
Hadoop Архитектура
Основната идея на тази архитектура е, че цялото съхранение и обработка се извършва на два етапа и по два начина. Първата стъпка е обработка, която се извършва чрез програмиране на Map намаление, а втората стъпка е запаметяване на данните, които се правят на HDFS. Той има архитектура master-slave за съхранение и обработка на данни. Главният възел за съхранение на данни в Hadoop е възелът с име. Има и главен възел, който върши работата по наблюдение и обработка на паралели с помощта на Hadoop Map Reduce. Робите са други машини от групата Hadoop, които помагат при съхраняването на данни и също извършват сложни изчисления. Всеки подчинен възел е присвоен с проследяване на задачи, а възелът за данни има проследяващ задачи, който помага при стартирането на процесите и тяхната ефективна синхронизация. Този тип система може да бъде настроена или в облак, или в помещение. Възелът Name е единична точка на повреда, когато не работи в режим на висока наличност. Архитектурата на Hadoop има също така възможност за поддържане на възел „stand by Name“, за да се защити системата от повреди. Преди това имаше вторични имена възли, които действаха като резервно копие, когато основният възел на име беше отпаднал.
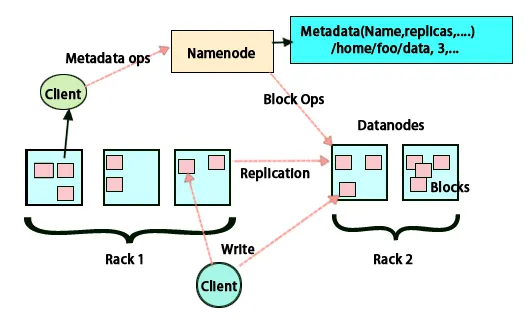
FSimage и Edit Log
FSimage и Edit Log гарантират постоянството на метаданните на файловата система, за да бъдат в крак с цялата информация и възел с имена съхранява метаданните в два файла. Тези файлове са FSimage и журналът за редактиране. Задачата на FSimage е да поддържа пълна снимка на файловата система в даден момент. Промените, които непрекъснато се правят в системата, трябва да бъдат регистрирани. Тези постепенни промени като преименуване или добавяне на детайли към файла се съхраняват в дневника за редактиране. Рамката предоставя по-добър вариант, а не да създавате нов FSimage всеки път, по-добър вариант да можете да съхранявате данните, докато нов файл за FSimage. FSimage създава нова снимка всеки път, когато се правят промени. Ако възелът Name не успее, той може да възстанови предишното си състояние. Вторичният възел на име може също да актуализира своето копие винаги, когато има промени в FSimage и редактиране на регистрационни файлове. По този начин тя гарантира, че въпреки че възелът на име е надолу, при наличието на вторичен име на възел няма да има загуба на данни. Възелът с име не изисква тези изображения да се презареждат във втория възел на име.
Репликация на данни
HDFS е предназначен за бърза обработка на данни и предоставяне на надеждни данни. Той съхранява данни на машини и в големи клъстери. Всички файлове се съхраняват в серия от блокове. Тези блокове се възпроизвеждат за поносимост на грешки. Размерът на блока и коефициентът на репликация могат да се определят от потребителите и да се конфигурират според потребителските изисквания. По подразбиране коефициентът на репликация е 3. Коефициентът на репликация може да бъде определен по време на създаването на файла и може да бъде променен по-късно. Всички решения относно тези реплики се вземат от възела с име. Възелът с име продължава да изпраща сърдечни удари и да блокира отчет на редовни интервали за всички възли на данни в клъстера. Получаването на пулс предполага, че възелът на данни работи правилно. Отчетът за блока указва списъка на всички блокове, присъстващи на възела с данни.
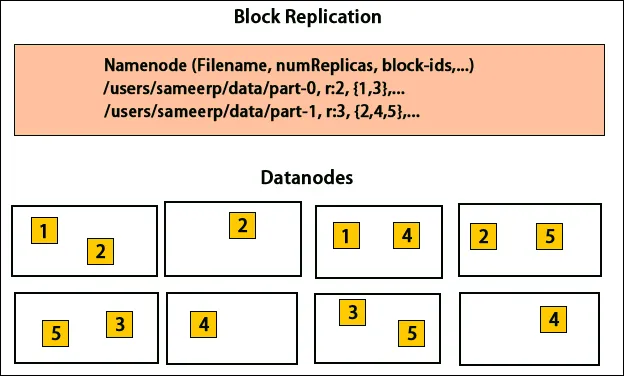
Поставяне на реплики
Поставянето на реплики е много важна задача в Hadoop за надеждност и производителност. Всички различни блокове данни се поставят на различни стелажи. Реализацията на разположение на реплики може да се извърши според надеждността, наличността и използването на мрежовата честотна лента. Клъстерът от компютри може да бъде разпределен в различни стелажи. Не повече от два възела могат да бъдат поставени на един и същи стелаж. Третата реплика трябва да бъде поставена на различен стелаж, за да се гарантира по-голяма надеждност на данните. Двата възли на багажника комуникират чрез различни превключватели. Възелът с име има идентификатора на стелажа за всеки възел от данни. Но поставянето на всички възли в различни стелажи предотвратява загубата на всякакви данни и позволява използването на честотна лента от множество стелажи. Той също така намалява трафика между рейките и подобрява производителността. Също така, шансът за повреда в багажника е много по-малък в сравнение с този на отказ на възел. Той намалява общата честотна лента на мрежата, когато данните се четат от два уникални стелажа, а не от три.
Намаляване на картата
Map Reduct се използва за обработка на данни, които се съхраняват на HDFS. Той записва разпределени данни в разпределени приложения, което гарантира ефективна обработка на големи количества данни. Те преработват на големи клъстери и изискват стока, която е надеждна и поносима при повреди. Ядрото на намаляването на картата може да бъде три операции като картографиране, събиране на двойки и разбъркване на получените данни.
Заключение - Hadoop Architecture
Hadoop е рамка с отворен код, която помага в система за устойчивост на повреди. Той може да съхранява големи количества данни и помага при съхраняването на надеждни данни. Двете части за съхранение на данни в HDFS и обработването им чрез намаляване на картата помагат за правилната и ефективна работа. Той има архитектура, която помага при управлението на всички блокове данни, а също така има най-новото копие, като го съхранява в FSimage и редактира дневници. Коефициентът на репликация също помага за копирането на данни и връщането им обратно, когато има неуспех. HDFS също премества премахнатите файлове в кошчето за оптимално използване на пространството.
Препоръчителни статии
Това е ръководство за Hadoop Architecture. Тук сме обсъдили Архитектурата, Намаляването на картата, Поставянето на реплики, Репликацията на данни. Можете да разгледате и другите ни предложени статии, за да научите повече -
- Станете разработчик на Hadoop
- Въведение в Android
- Какво е Tableau? | Преглед
- Какво представлява MapReduce в Hadoop?