
Какво е GLM в R?
Генерализираните линейни модели е подмножество от модели на линейна регресия и ефективно поддържа ненормални разпределения. За да подкрепите това, се препоръчва да използвате функция glm (). GLM работи добре с променлива, когато дисперсията не е постоянна и се разпределя нормално. Дефинирана е функция за свързване, за да трансформира променливата на отговора, за да съответства на подходящия модел. LM модел се прави както със семейството, така и с формулата. Моделът GLM има три ключови компонента, наречени произволен (вероятност), систематичен (линеен предсказател), компонент на връзката (за функция logit). Предимството на използването на glm е, че имат гъвкавост на модела, няма нужда от постоянна разлика и този модел отговаря на максималната оценка на вероятността и съотношенията му. В тази тема ще научим за GLM в R.
GLM функция
Синтаксис: glm (формула, фамилия, данни, тегла, подмножество, Start = null, model = TRUE, method = ””…)
Тук Типовете семейства (включват типове модели) включват биномиални, Поасонови, Гаусски, гама, квази. Всяка дистрибуция изпълнява различно използване и може да се използва както в класификация, така и в прогнозиране. И когато моделът е гаус, отговорът трябва да бъде истинско цяло число.
И когато моделът е двучлен, отговорът трябва да бъде класове с двоични стойности.
И когато моделът е Poisson, отговорът трябва да е неотрицателен с числова стойност.
И когато моделът е гама, отговорът трябва да бъде положителна цифрова стойност.
glm.fit () - За да се побере модел
Lrfit () - обозначава логистична регресия.
update () - помага при актуализиране на модел.
anova () - неговият незадължителен тест.
Как да създадете GLM в R?
Тук ще видим как да създадем лесен обобщен линеен модел с двоични данни, използвайки функция glm (). И като продължите с набора от данни на Дървета.
Примери
// Импортиране на библиотекаlibrary(dplyr)
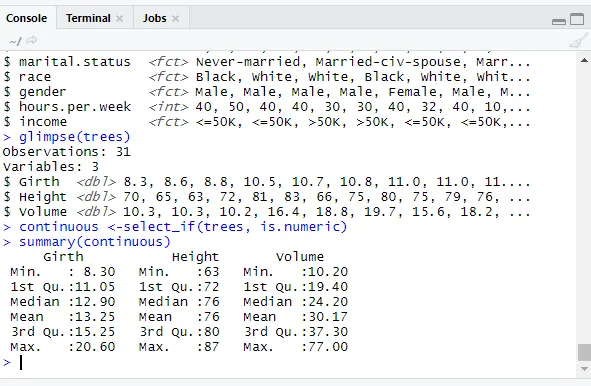
glimpse(trees)

За да видите категорични стойности са назначени фактори.
levels(factor(trees$Girth))
// Проверка на непрекъснати променливи
library(dplyr)
continuous <-select_if(trees, is.numeric)
summary(continuous)
// Включване на набора от данни за дърво в R търсене Pathattach (дървета)
x<-glm(Volume~Height+Girth)
x
изход:
| Повикване: glm (формула = Обем ~ Височина + Обхват)
коефициенти: (Прихващане) Височина на обхвата -57.9877 0.3393 4.7082 Степени на свобода: 30 Общо (т.е. Нет); 28 Остатъчни Нулево отклонение: 8106 Остатъчно отклонение: 421.9 AIC: 176.9 |
summary(x)
| Обадете се:
glm (формула = обем ~ височина + обхват) Остатъчни отклонения: Мин. 1Q Средна 3Q Макс -6.4065 -2.6493 -0.2876 2.2003 8.4847 коефициенти: Оценете Std. Грешка t стойност Pr (> | t |) (Прихващане) -57.9877 8.6382 -6.713 2.75e-07 *** Височина 0.3393 0.1302 2.607 0.0145 * Обхват 4.7082 0.2643 17.816 <2e-16 *** - Signif. кодове: 0 '***' 0, 001 '**' 0.01 '*' 0, 05 '.' 0, 1 '' 1 (Параметър на дисперсия за семейство Гаус, приети за 15.06862) Нулево отклонение: 8106.08 при 30 градуса свобода Остатъчно отклонение: 421, 92 на 28 градуса свобода AIC: 176.91 Брой повторения на Фишър за оценка: 2 |
Резултатът от обобщената функция извиква обажданията, коефициентите и остатъците. Горният отговор показва, че височината и коефициентът на полезно действие не са значими, тъй като вероятността за тях е по-малка от 0, 5. И има два варианта на отклонение, наречени нула и остатъчен. И накрая, оценката на риболова е алгоритъм, който решава въпросите за максимална вероятност. При биномиалният отговор е вектор или матрица. cbind () се използва за свързване на векторите на колоните в матрица. И за да получите подробна информация за подходящото обобщение се използва.
За да направите като тест за качулка се изпълнява следния код.
step(x, test="LRT")
Start: AIC=176.91
Volume ~ Height + Girth
Df Deviance AIC scaled dev. Pr(>Chi)
421.9 176.91
- Height 1 524.3 181.65 6.735 0.009455 **
- Girth 1 5204.9 252.80 77.889 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Call: glm(formula = Volume ~ Height + Girth)
Coefficients:
(Intercept) Height Girth
-57.9877 0.3393 4.7082
Degrees of Freedom: 30 Total (ie Null); 28 Residual
Null Deviance: 8106
Residual Deviance: 421.9 AIC: 176.9
Поставяне на модел
a<-cbind(Height, Girth - Height)
> a
резюме (дървета)
Girth Height Volume
Min. : 8.30 Min. :63 Min. :10.20
1st Qu.:11.05 1st Qu.:72 1st Qu.:19.40
Median :12.90 Median :76 Median :24.20
Mean :13.25 Mean :76 Mean :30.17
3rd Qu.:15.25 3rd Qu.:80 3rd Qu.:37.30
Max. :20.60 Max. :87 Max. :77.00
За да получите съответното стандартно отклонение
apply(trees, sd)
Girth Height Volume
3.138139 6.371813 16.437846
predict <- predict(logit, data_test, type = 'response')
На следващо място, ние препращаме към променливата за отброяване на броя, за да моделираме подходящ отговор. За да изчислим това, ще използваме набора от данни на USAccDeath.
Нека въведем следните фрагменти в конзолата R и да видим как се извършва броя на годините и квадратът на годината върху тях.
data("USAccDeaths")
force(USAccDeaths)
// Да анализираме годината от 1973-1978г.
disc <- data.frame(count=as.numeric(USAccDeaths), year=seq(0, (length(USAccDeaths)-1), 1)))
yearSqr=disc$year^2
a1 <- glm(count~year+yearSqr, family="poisson", data=disc)
summary(a1)
| Обадете се:
glm (формула = брой ~ година + годинаSqr, семейство = “poisson”, данни = диск) Остатъчни отклонения: Мин. 1Q Средна 3Q Макс -22.4344 -6.4401 -0.0981 6.0508 21.4578 коефициенти: Оценете Std. Грешка z стойност Pr (> | z |) (Прихващане) 9.187e + 00 3.557e-03 2582.49 <2e-16 *** година -7.207e-03 2.354e-04 -30.62 <2e-16 *** годинаSqr 8.841e-05 3.221e-06 27.45 <2e-16 *** - Signif. кодове: 0 '***' 0, 001 '**' 0.01 '*' 0, 05 '.' 0, 1 '' 1 (Параметър на дисперсия за семейство Poisson, приети за 1) Нулево отклонение: 7357.4 при 71 градуса свобода Остатъчно отклонение: 6358.0 при 69 градуса на свобода AIC: 7149.8 Брой повторения на Фишър за оценка: 4 |
За да се провери най-доброто съответствие на модела, може да се използва следната команда за намиране
остатъците от теста. От резултата по-долу стойността е 0.
1 - pchisq(deviance(a1), df.residual(a1))
Използване на семейство QuasiPoisson за по-голямото отклонение в дадените данни
a2 <- glm(count~year+yearSqr, family="quasipoisson", data=disc)
summary(a2)
| Обадете се:
glm (формула = брой ~ година + годинаSqr, семейство = „квазипоасон“, данни = диск) Остатъчни отклонения: Мин. 1Q Средна 3Q Макс -22.4344 -6.4401 -0.0981 6.0508 21.4578 коефициенти: Оценете Std. Грешка t стойност Pr (> | t |) (Прихващане) 9.187e + 00 3.417e-02 268.822 <2e-16 *** година -7.207e-03 2.261e-03 -3.188 0.00216 ** годинаSqr 8.841e-05 3.095e-05 2.857 0.00565 ** - (Параметър на дисперсия за семейство квазипоасони, приети за 92.28857) Нулево отклонение: 7357.4 при 71 градуса свобода Остатъчно отклонение: 6358.0 при 69 градуса на свобода AIC: NA Брой повторения на Фишър за оценка: 4 |
Сравняването на Poisson с биномиалната AIC стойност се различава значително. Те могат да бъдат анализирани чрез прецизност и коефициент на извикване. Следващата стъпка е да се провери, че остатъчната дисперсия е пропорционална на средната стойност. Тогава можем да замислим с помощта на библиотеката ROCR за подобряване на модела.
заключение
Затова сме се съсредоточили върху специален модел, наречен генерализиран линеен модел, който помага при фокусирането и оценката на параметрите на модела. Това е преди всичко потенциалът за променлива на непрекъснат отговор. И видяхме как glm пасва на R вградени пакети. Те са най-популярните подходи за измерване на броя на данните и стабилен инструмент за класификационни техники, използвани от учен с данни. Езикът R, разбира се, помага при извършването на сложни математически функции
Препоръчителни статии
Това е ръководство за GLM в R. Тук обсъждаме GLM функцията и как да създадем GLM в R с примери за набори от дърво и набор от данни. Можете също да разгледате следната статия, за да научите повече -
- R Език за програмиране
- Архитектура на големи данни
- Логистична регресия в R
- Работа с големи данни за анализи
- Поасонова регресия в R | Реализиране на Поасонова регресия