
Определение на средния алгоритъм на изместване
Алгоритъмът на средно изместване попада под неуправляемо обучение, което е категоризирано като алгоритъм на клъстеринг. Идеологията на алгоритъма „Средно изместване“ е, че той итеративно присвоява точки от данни на клъстерите, като се измества към точката, която има точка с най-висока плътност (Режим). Средната логика на преместване, базирана на основата на концепцията за оценка на плътността на ядрото, наречена KDE.
Средно изместване на алгоритъм на изместване
Неуправляема техника на обучение, открита от Фукунага и Хостеллер за намиране на групи:
- Mean Shift е известен още като алгоритъм за търсене на режим, който присвоява точките от данни на клъстерите по начин, като измества точките на данни към областта с висока плътност. Най-високата плътност на точките от данни се нарича модел в региона. Алгоритъмът на средна смяна има приложения, широко използвани в областта на компютърното зрение и сегментиране на изображенията.
- KDE е метод за оценка на разпределението на точките от данни. Той работи, като поставя ядро на всяка точка от данни. Ядрото в математическия термин е функция за претегляне, която ще прилага тегла за отделни точки от данни. Добавянето на цялото отделно ядро генерира вероятността.
Функцията на ядрото е необходима, за да отговаря на следните условия:
- Първото изискване е да се гарантира, че оценката на плътността на ядрото е нормализирана.
- Второто изискване е KDE да е добре свързан със симетрията на пространството.
Две популярни функции на ядрото
По-долу са описани двете популярни функции на ядрото:
- Плоска ядка
- Gaussian Kernel
- Въз основа на използвания парам на ядрото, резултатната функция на плътност варира. Ако не е посочен параметър на ядрото, Gaussian Kernel се извиква по подразбиране. KDE използва концепцията за функция на плътност на вероятностите, която помага да се намерят локалните максимуми на разпределението на данните. Алгоритъмът работи, като кара точките да се привличат една друга, позволявайки на точките с данни към областта с висока плътност.
- Точките от данни, които се опитват да се сближат към локалните максимуми, ще бъдат от една и съща група клъстери. За разлика от алгоритъма за клъстериране на K-Means, изходът на алгоритъма за средно изместване не зависи от предположенията за формата на точката на данни и броя на клъстерите. Броят на клъстерите ще се определя от алгоритъма по отношение на данните.
- За да извършим реализацията на алгоритъма на средната смяна, използваме python пакет SKlearn.
Прилагане на алгоритма за средно изместване
По-долу е изпълнението на алгоритъма:
Пример №1
Въз основа на Sklearn урок за алгоритъм на средното изместване на клъстеринг. Първият фрагмент ще реализира среден алгоритъм за изместване, за да намери струпванията на двуизмерния набор от данни. Пакети, използвани за прилагане на алгоритма за средно изместване.
Код:
fromcluster importMeanShift, estimate_bandwidth
from sklearn.datasets.samples_generator import make_blobs as mb
importpyplot as plt
fromitertools import cycle as cy
Едно ключово нещо, което трябва да се отбележи, е, че ще използваме библиотеката make_blobs на sklearn за генериране на точки от данни, центрирани на 3 места. За да приложим алгоритъма на средното изместване към генерираните точки, трябва да зададем широчината на честотната лента, която представлява взаимодействието между дължината. Библиотеката на Sklearn има вградени функции за оценка на честотната лента.
Код:
#Sample data points
cen = ((1, .75), (-.75, -1), (1, -1)) x_train, _ = mb(n_samples=10000, centers= cen, cluster_std=0.6)
# Bandwidth estimation using in-built function
est_bandwidth = estimate_bandwidth(x_train, quantile=.1,
n_samples=500)
mean_shift = MeanShift(bandwidth= est_bandwidth, bin_seeding=True)
fit(x_train)
ms_labels = mean_shift.labels_
c_centers = ms_labels.cluster_centers_
n_clusters_ = ms_labels.max()+1
# Plot result
figure(1)
clf()
colors = cy('bgrcmykbgrcmykbgrcmykbgrcmyk')
fori, each inzip(range(n_clusters_), colors):
my_members = labels == i
cluster_center = c_centers(k) plot(x_train(my_members, 0), x_train(my_members, 1), each + '.')
plot(cluster_center(0), cluster_center(1),
'o', markerfacecolor=each,
markeredgecolor='k', markersize=14)
title('Estimated cluster numbers: %d'% n_clusters_)
show()
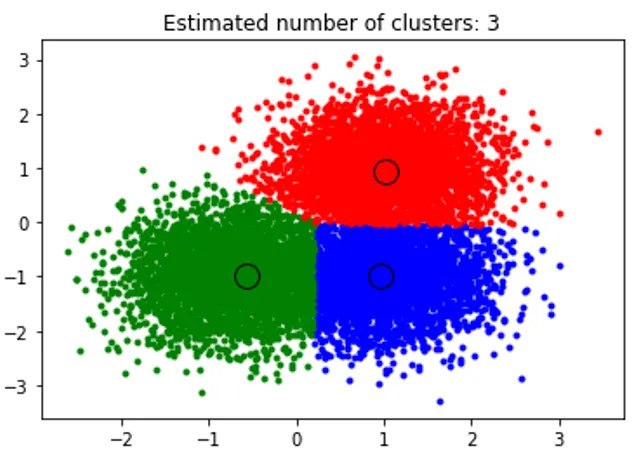
Горният фрагмент изпълнява клъстериране и алгоритъмът намира клъстери, центрирани върху всяко генерирано от нас блоб. Можем да видим, че от изображението по-долу, начертано от фрагмента, се показва алгоритъмът на средното преместване, способен да идентифицира броя на клъстерите, необходими за времето на изпълнение и да измисли подходящата честотна лента, която да представи дължината на взаимодействие
изход:
Пример №2
Въз основа на сегментирането на изображението в компютърното зрение. Вторият фрагмент ще изследва как алгоритъмът за средно изместване, използван в Deep Learning, за да извърши сегментиране на цветното изображение. Използваме алгоритма за средно изместване, за да идентифицираме пространствените клъстери. По-ранният фрагмент използвахме 2-D набор данни, докато в този пример ще изследваме 3-D пространството. Пикселът на изображението ще се третира като точки от данни (r, g, b). Трябва да преобразуваме изображението във формат на масив, така че всеки пиксел да представлява точка от данни в изображението, което ще отидем в сегмента. Клъстерирането на цветовите стойности в пространството връща серия от клъстери, където пикселите в клъстера ще бъдат подобни на RGB пространството. Пакети, използвани за прилагане на алгоритма за средно изместване:
Код:
importnumpy as np
fromcluster importMeanShift, estimate_bandwidth
fromdatasets.samples_generator importmake_blobs
importpyplot as plt
fromitertools import cycle
fromPIL import Image
По-долу Snippet за извършване на сегментиране на оригиналното изображение:
#Segmentation of Color Image
img = Image.open('Sample.jpg.webp')
img = np.array(img)
#Need to convert image into feature array based
flatten_img=np.reshape(img, (-1, 3))
#bandwidth estimation
est_bandwidth = estimate_bandwidth(flatten_img,
quantile=.2, n_samples=500)
mean_shift = MeanShift(est_bandwidth, bin_seeding=True)
fit(flatten_img)
labels= mean_shift.labels_
# Plot image vs segmented image
figure(2)
subplot(1, 1, 1)
imshow(img)
axis('off')
subplot(1, 1, 2)
imshow(np.reshape(labels, (854, 1224)))
axis('off')
Генерираното изображение заявява, че този подход за идентифициране на формите на изображенията и определяне на пространствените клъстери може да се извърши ефективно без никаква обработка на изображението.
изход:


Предимства и приложения Среден алгоритъм на изместване
По-долу са предимствата и приложението на средния алгоритъм:
- Той се използва широко за решаване на компютърно зрение, където се използва за сегментиране на изображението.
- Клъстеризиране на точки от данни в реално време, без да се споменава броят на клъстерите.
- Представлява добре при сегментиране на изображението и проследяване на видео.
- По-здрав за Outliers.
Плюсове на алгоритма на средно изместване
По-долу са алгоритъма за промяна на плюса:
- Изходът на алгоритъма е независим от инициализациите.
- Процедурата е ефективна, тъй като има само един параметър - честотна лента.
- Без предположения за броя на клъстерите от данни и формата.
- Той има по-добри показатели от K-Means Clustering.
Минуси на алгоритма на средното изместване
По-долу са показани минусите на средния алгоритъм за изместване:
- Скъп за големи функции.
- В сравнение с клъстерирането на K-Means, това е много бавно.
- Изходът на алгоритъма зависи от честотната лента на параметъра.
- Изходът зависи от размера на прозореца.
заключение
Въпреки че това е пряк подход, който главно се използва за решаване на проблеми, свързани с сегментирането на изображенията, клъстерирането. Той е сравнително по-бавен от K-Means и е изчислително скъп.
Препоръчителни статии
Това е ръководство за алгоритма за средно изместване. Тук обсъждаме проблеми, свързани с сегментирането на изображението, клъстерирането, ползите и две функции на ядрото. Можете също да разгледате и другите ни свързани статии, за да научите повече-
- K- означава алгоритъм за клъстериране
- KNN Алгоритъм в R
- Какво е генетичен алгоритъм?
- Методи на ядрото
- Методи на ядрото в машинното обучение
- Подробно обяснение на алгоритма на C ++