

Въведение в методите за извличане на данни
Данните се увеличават ежедневно в огромен мащаб. Но всички събрани или събрани данни не са полезни. Значителните данни трябва да бъдат отделени от шумните данни (безсмислени данни). Този процес на отделяне се осъществява чрез извличане на данни.
Какво е извличане на данни?
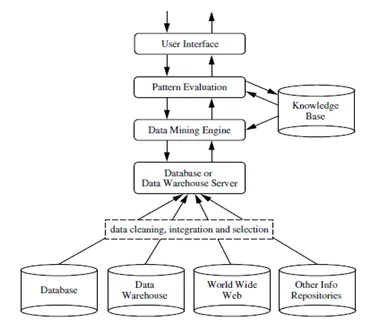
Извличането на данни е процес на извличане на полезна информация или знания от огромно количество данни (или големи данни). Пропастта между данни и информация е намалена чрез използване на различни инструменти за извличане на данни. Извличането на данни може също да бъде посочено като откриване на знания от данни или KDD .
Източници: - www.ques10.com
Извличането на данни може да се извърши в различни видове бази данни и хранилища на информация като релационни бази данни, хранилища на данни, транзакционни бази данни, потоци от данни и много други.
Различни методи за извличане на данни:
Има много методи, използвани за извличане на данни, но решаващата стъпка е да изберете подходящия метод от тях според бизнеса или изложението на проблема. Тези методи за извличане на данни помагат да се прогнозира бъдещето и след това да се вземат решения съответно. Те също така помагат за анализиране на пазарната тенденция и за увеличаване на приходите на компанията.
Някои методи за извличане на данни са:
- сдружаване
- класификация
- Анализ на клъстеринг
- предвиждане
- Последователни модели или проследяване на модели
- Дървета на решенията
- По-голям анализ или анализ на аномалията
- Невронна мрежа
Нека разберем всеки метод за извличане на данни един по един.
1. Асоциация:
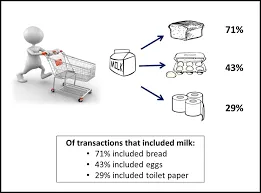
Това е метод, използван за намиране на корелация между два или повече елемента чрез идентифициране на скрития модел в набора от данни, а оттам и наричан анализ на връзката . Този метод се използва при анализа на пазарните кошници, за да се предскаже поведението на клиента.
Да предположим, маркетинг мениджърът на супермаркет иска да определи кои продукти често се купуват заедно.
Като пример,
Купува (x, "бира") -> купува (x, "чипс") (подкрепа = 1%, увереност = 50%)
- Тук х представлява клиент, който купува бира и чипс заедно.
- Увереността показва сигурност, че ако клиент купи бира, има 50% вероятност той да купи и чиповете.
- Подкрепата означава, че 1% от всички анализирани транзакции показаха, че бирата и чипсът се купуват заедно.
Много подобни примери като хляб и масло или компютър и софтуер могат да бъдат разгледани.
Има два вида правила за асоцииране:
- Правило за едномерна асоциация: Тези правила съдържат един атрибут, който се повтаря.
- Многомерно правило за асоцииране: Тези правила съдържат множество атрибути, които се повтарят.
https://bit.ly/2N61gzR
2. Класификация:
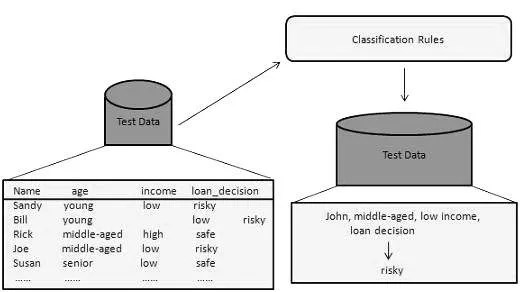
Този метод за извличане на данни се използва за разграничаване на елементите в наборите от данни в класове или групи. Той помага точно да се предвиди поведението на артикулите в групата. Това е процес на две стъпки:
- Етап на обучение (фаза на обучение): В този алгоритъм за класификация се изгражда класификаторът чрез анализ на набор от тренировки.
- Етап на класификация: Данните от теста се използват за оценка на точността или точността на правилата за класификация.
Например, банкова компания използва за идентифициране на кандидатите за кредит при ниски, средни или високи кредитни рискове. По същия начин медицински изследовател анализира данните за рака, за да прогнозира кое лекарство да предпише на пациента.
Източници: - www.tutorialspoint.com
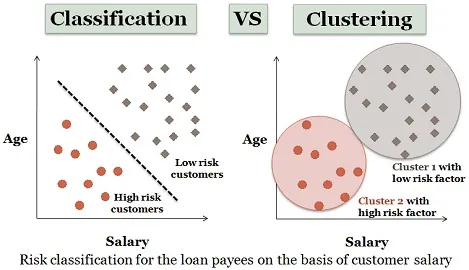
3. Анализ на клъстеринг:
Клъстерирането е почти подобно на класификацията, но в тези клъстери се правят в зависимост от приликите на данните. Различните клъстери имат различни или несвързани обекти. Нарича се още като сегментиране на данни, тъй като разделя огромни набори от данни в клъстери според приликите.
Използват се различни методи за групиране:
- Йерархични агломеративни методи
- Методи, базирани на решетки
- Методи за разделяне
- Методи, основани на модела
- Методи, основани на плътност
Подобен пример на кандидати за кредит също може да бъде разгледан тук. Има някои разлики, които са изобразени на фигурата по-долу.
https://bit.ly/2N6aZpP
4. Прогнозиране:
Този метод се използва за прогнозиране на бъдещето въз основа на минали и настоящи тенденции или набор от данни. Прогнозирането се използва най-вече с комбинацията от други методи за извличане на данни като класификация, съвпадение на модели, анализ на тенденции и връзка.
Например, ако мениджърът по продажби на супермаркет би искал да предвиди размера на приходите, които всеки артикул би генерирал въз основа на данни от минали продажби. Тя моделира функция с непрекъсната стойност, която прогнозира липсващи числови стойности на данни.

Източници: - data-mining.philippe-fournier
Регресионният анализ е най-добрият избор за извършване на прогнозиране. Може да се използва за определяне на връзка между независими променливи и зависими променливи.
5. Последователни модели или проследяване на модели:
Този метод за извличане на данни се използва за идентифициране на модели, които се срещат често за определен период от време.
Например, мениджърът по продажбите на компания за дрехи вижда, че продажбите на якета изглежда се увеличават точно преди зимния сезон или продажбите в хлебни изделия се увеличават по време на Коледа или Нова година.
Нека да разгледаме пример с графика
Източници: - data-mining.philippe-fournier-viger
6.Различни дървета:
Дървото за решения е дърво структура (както подсказва името му), където
- Всеки вътрешен възел представлява тест на атрибута.
- Клонът обозначава резултата от теста.
- Терминалните възли държат етикета на класа.
- Най-горният възел е коренният възел, който има простия въпрос, който има два или повече отговора. Съответно, дървото расте и се генерира диаграма като структура.
Източници: - www.tutorialride.com
В това решение правителството на дърветата класифицира граждани под 18 или повече години. Това би им помогнало да решат дали лиценз трябва да бъде издаден на определен гражданин или не.
7.Общ анализ или анализ на аномалията:
Този метод за извличане на данни се използва за идентифициране на елементи от данни, които не съответстват на очаквания модел или очаквано поведение. Тези неочаквани данни се считат за отшелници или шум. Те са полезни в много области като откриване на измами с кредитни карти, откриване на проникване, откриване на неизправности и т.н. Това също се нарича Outlier Mining .
Например, да приемем, че графиката по-долу е начертана с помощта на някои набори от данни в нашата база данни.
Така че е изчертана най-добрата линия на прилягане. Точките, лежащи в близост до линията, показват очаквано поведение, докато точката далеч от линията е Outlier.
Това би помогнало за откриване на аномалиите и съответно предприемане на евентуални действия.
https://bit.ly/2GrgjDP
8. Невронна мрежа:
Този метод или модел за извличане на данни се основава на биологични невронни мрежи. Това е съвкупност от неврони като обработващи единици с претеглени връзки между тях. Те се използват за моделиране на връзката между входовете и изходите. Използва се за класификация, регресионен анализ, обработка на данни и т.н. Тази техника работи на три стълба -
- Модел
- Алгоритъм за обучение (контролиран или неподдържан)
- Функция за активиране
Източници: - www.saedsayad.com
Препоръчителни статии
Това беше ръководство за методите за извличане на данни Тук с примера сме обсъдили какво е извличане на данни и различни видове метод за извличане на данни. Можете също да разгледате следните статии, за да научите повече -
- Софтуер за големи данни Анализ
- Въпроси за интервю за структурата на данните
- Важни техники за извличане на данни
- Архитектура за добив на данни