
Въведение в класификацията на невронната мрежа
Невронните мрежи са най-ефективният начин (да, правилно сте прочели) за решаване на проблеми в реалния свят в изкуствения интелект. Понастоящем това е една от много широко изследваните области в компютърните науки, която би била разработена нова форма на Невронна мрежа, докато четете тази статия. Има стотици невронни мрежи за решаване на проблеми, специфични за различни домейни. Тук ще ви преведем през различни видове основни невронни мрежи в реда на нарастваща сложност.
Различни видове основи при класификацията на невронните мрежи
1. Плитки невронни мрежи (съвместно филтриране)
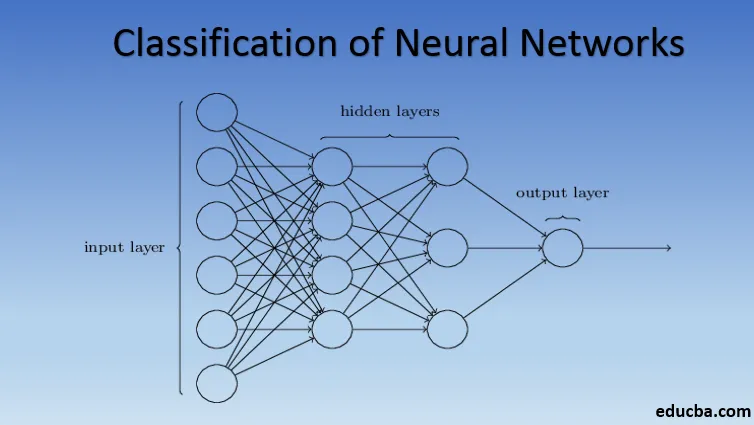
Невронните мрежи са изградени от групи Perceptron за симулиране на нервната структура на човешкия мозък. Плитките невронни мрежи имат един скрит слой от перцептрон. Един от често срещаните примери за плитки невронни мрежи е съвместното филтриране. Скритият слой на персептрон ще бъде обучен да представя сходствата между образуванията, за да генерира препоръки. Системата за препоръки в Netflix, Amazon, YouTube и др. Използва версия за съвместно филтриране, за да препоръча техните продукти според интереса на потребителите.
2. Многослоен перцептрон (дълбоки невронни мрежи)
Невронните мрежи с повече от един скрит слой се наричат Deep Neural Networks. Внимание спойлер! Всички следващи невронни мрежи са форма на дълбока невронна мрежа, оправена / подобрена за справяне с специфични за домейна проблеми. Като цяло те ни помагат да постигнем универсалност. Като се има предвид достатъчен брой скрити слоеве на неврона, дълбоката невронна мрежа може да се сближи, т.е. да реши всеки сложен проблем в реалния свят.
Теоремата за универсално сближаване е ядрото на дълбоките невронни мрежи, за да се обучават и прилягат всеки модел. Всяка версия на дълбоката невронна мрежа е разработена от напълно свързан слой от максимално събран продукт с матрично умножение, който е оптимизиран от алгоритмите за обратно разпространение. Ще продължим да научаваме подобренията, водещи до различни форми на дълбоки невронни мрежи.
3. Конволюционна невронна мрежа (CNN)
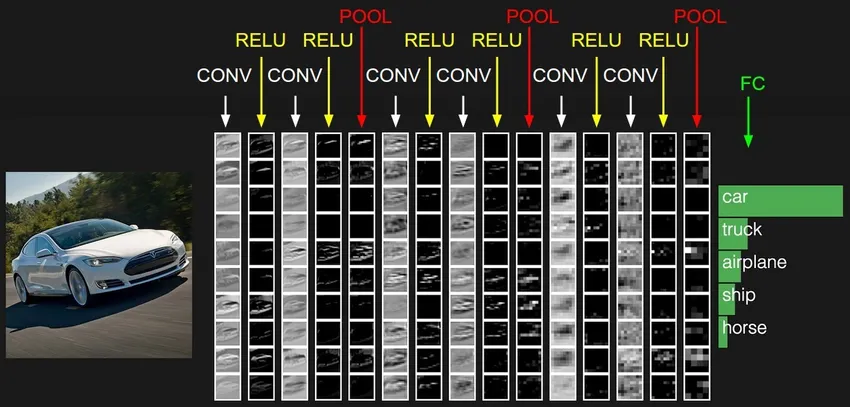
CNN са най-зрялата форма на дълбоки невронни мрежи, за да се получат най-точните, т.е. по-добри от човешките резултати в компютърното зрение. CNN се състоят от слоеве свити, създадени чрез сканиране на всеки пиксел от изображения в набор от данни. Докато данните получават приблизително слой по слой, CNN започва да разпознава шаблоните и по този начин разпознава обектите в изображенията. Тези обекти се използват широко в различни приложения за идентификация, класификация и др. Последните практики като трансферно обучение в CNN доведоха до значителни подобрения в неточността на моделите. Google Translator и Google Lens са най-съвременният пример за изкуство на CNN.
Приложението на CNN е експоненциално, тъй като те дори се използват при решаване на проблеми, които преди всичко не са свързани с компютърното зрение. Тук можете да намерите много просто, но интуитивно обяснение на CNN.
4. Повтаряща се невронна мрежа (RNN)
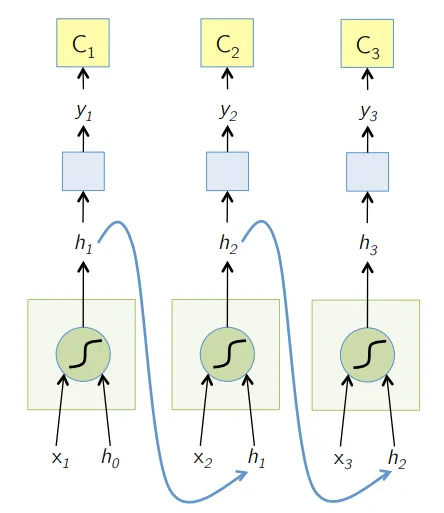
RNN са най-новата форма на дълбоки невронни мрежи за решаване на проблеми в NLP. Най-просто казано, RNN подават изхода на няколко скрити слоя обратно към входния слой, за да се агрегират и пренасят приближението към следващата итерация (епоха) на входния набор от данни. Освен това помага на модела да се самоучи и по-бързо коригира прогнозите. Такива модели са много полезни при разбирането на семантиката на текста при NLP операциите. Има различни варианти на RNN като Long Short Term Memory (LSTM), Gated Recurrent Unit (GRU) и т.н. В диаграмата по-долу активирането от h1 и h2 се подава съответно с вход x2 и x3.
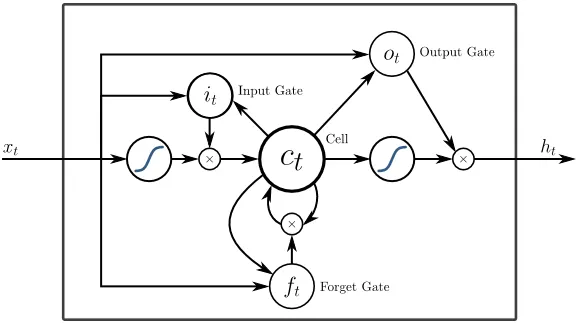
5. Дългосрочна краткосрочна памет (LSTM)
LSTM са създадени специално за справяне с изчезващия проблем с градиентите с RNN. Изчезването на градиентите се случва с големи невронни мрежи, където градиентите на функциите на загуба са склонни да се приближават до нула, правейки пауза на невронните мрежи, за да се научат. LSTM решава този проблем, като предотвратява функциите на активиране в неговите повтарящи се компоненти и като запаметените стойности не се променят. Тази малка промяна даде големи подобрения в крайния модел, в резултат на което технологичните гиганти адаптират LSTM в своите решения. Преглед на "най-простата обяснителна" илюстрация на LSTM,
6. Мрежи, базирани на внимание
Моделите на вниманието бавно превземат дори новите RNN на практика. Моделите на вниманието са изградени чрез фокусиране върху част от подмножеството на информацията, която им се предоставя, като по този начин се елиминира огромното количество фонова информация, която не е необходима за задачата, която се изпълнява. Моделите на вниманието са построени с комбинация от меко и твърдо внимание и прилягащи чрез меко внимание, разпространяващо обратно. Моделите с множество внимание, подредени йерархично, се нарича Трансформатор. Тези трансформатори са по-ефективни да управляват стековете паралелно, така че да произвеждат съвременни резултати със сравнително по-малко данни и време за обучение на модела. Разпределението на вниманието става много мощно, когато се използва с CNN / RNN и може да създаде текстово описание на изображение, както следва.

Технически гиганти като Google, Facebook и др. Бързо адаптират моделите на внимание към изграждането на своите решения.
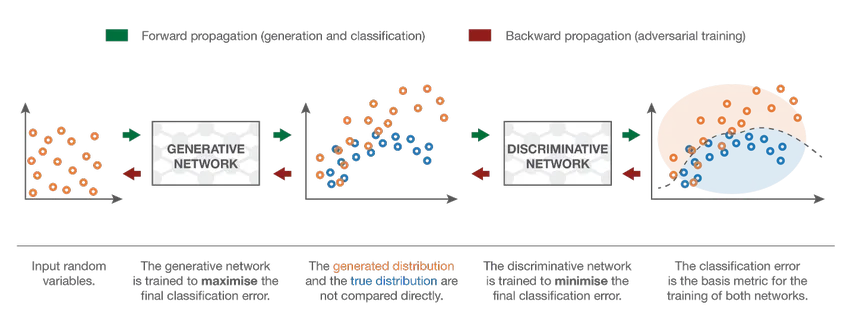
7. Генерална състезателна мрежа (GAN)
Въпреки че моделите на дълбоко обучение предоставят съвременни резултати, те могат да бъдат заблудени от далеч по-интелигентните човешки колеги чрез добавяне на шум към данните от реалния свят. GANs са най-новото развитие в задълбоченото обучение за справяне с подобни сценарии. GAN използват непроучено обучение, където дълбоките невронни мрежи се обучават с данните, генерирани от AI модел, заедно с реалния набор от данни, за да подобрят точността и ефективността на модела. Тези състезателни данни се използват най-вече за заблуждаване на дискриминационния модел с цел изграждане на оптимален модел. Полученият модел има тенденция да бъде по-добро приближение, отколкото може да преодолее такъв шум. Изследователският интерес към GAN доведе до по-сложни реализации като Conditional GAN (CGAN), Laplacian Pyramid GAN (LAPGAN), Super Resolution GAN (SRGAN) и др.
Заключение - Класификация на невронната мрежа
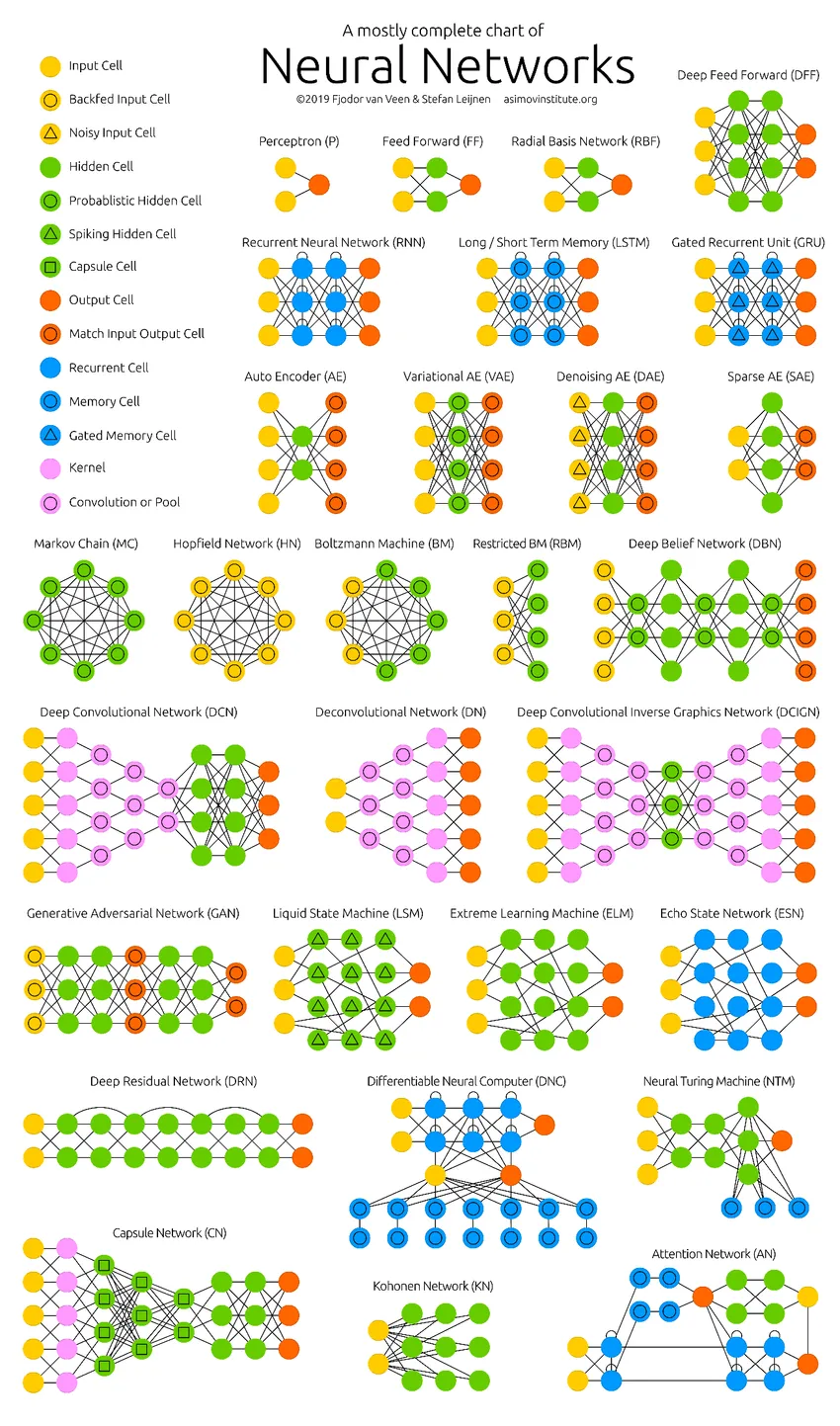
Дълбоките невронни мрежи натискат границите на компютрите. Те не се ограничават само до класификация (CNN, RNN) или прогнози (Collaborative Filtering), но дори и до генериране на данни (GAN). Тези данни могат да варират от красивата форма на изкуството до противоречивите дълбоки фалшификати, но въпреки това те надминават хората с задача всеки ден. Следователно, ние също трябва да вземем предвид етиката и въздействието на ИИ, докато работим усилено за изграждането на ефективен модел на невронната мрежа. Време е за чиста инфография за невронните мрежи.
Препоръчителни статии
Това е ръководство за класификацията на невронната мрежа. Тук обсъдихме различните видове основни невронни мрежи. Можете също да прегледате нашите статии, за да научите повече-
- Какво е невронни мрежи?
- Алгоритми на невронната мрежа
- Мрежови инструменти за сканиране
- Повтарящи се невронни мрежи (RNN)
- Топ 6 сравнения между CNN и RNN