
Линейна регресия в Excel (Съдържание)
- Въведение в линейна регресия в Excel
- Методи за използване на линейна регресия в Excel
Въведение в линейна регресия в Excel
Линейната регресия е статистическа техника / метод, използван за изследване на връзката между две непрекъснати количествени променливи. В тази техника независими променливи се използват за прогнозиране на стойността на зависима променлива. Ако има само една независима променлива, тогава това е обикновена линейна регресия и ако редица независими променливи са повече от една, то тя е множествена линейна регресия. Моделите на линейна регресия имат връзка между зависими и независими променливи, като приспособяват линейно уравнение към наблюдаваните данни. Линеен се отнася до факта, че ние използваме линия, за да отговарят на нашите данни. Зависимите променливи, използвани в регресионния анализ, се наричат също променливи на отговор или прогнози, а независимите променливи се наричат също обяснителни променливи или предиктори.
Линията на линейна регресия има уравнение от вида: Y = a + bX;
Където:
- X е обяснителната променлива,
- Y е зависимата променлива,
- b е наклонът на линията,
- a е y-прехващане (т.е. стойност на y, когато x = 0).
Методът с най-малко квадрати обикновено се използва при линейна регресия, която изчислява най-добрата линия за наблюдение на наблюдавани данни, като свежда до минимум сумата от квадрати отклонение на точките от линията.
Методи за използване на линейна регресия в Excel
Този пример ви учи на методите за извършване на линеен регресионен анализ в Excel. Нека разгледаме няколко метода.
Можете да изтеглите този шаблон за линейна регресия в Excel тук - Linear Regression Excel шаблонМетод №1 - Скатер диаграма с тенденция
Нека да кажем, че имаме набор от данни за някои хора с тяхната възраст, индекс на биомаса (ИТМ) и сумата, изразходвана от тях за медицински разходи за месец. Сега с разбиране за характеристиките на индивидите като възраст и ИТМ, бихме искали да открием как тези променливи влияят на медицинските разходи и следователно да ги използваме за извършване на регресия и оценка / прогнозиране на средните медицински разходи за някои конкретни лица. Нека първо да видим как само възрастта влияе на медицинските разходи. Нека видим набора от данни:
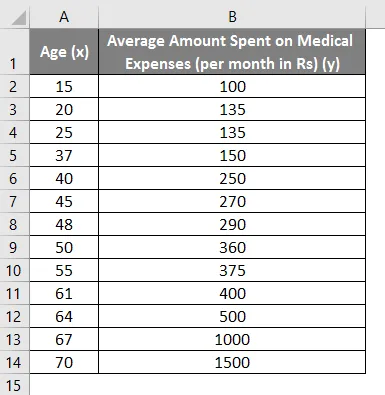
Сума за медицински разходи = b * възраст + a
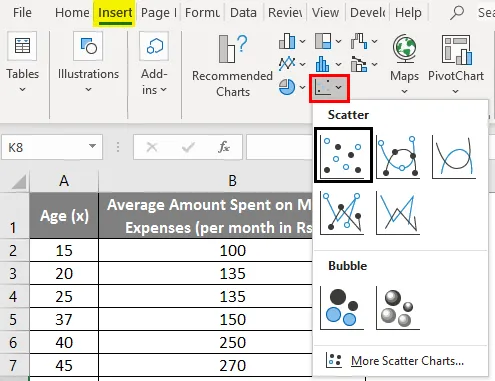
- Изберете двете колони на набора от данни (x и y), включително заглавки.
- Кликнете върху „Вмъкване“ и разгънете падащото меню за „Scatter Chart“ и изберете миниатюрата „Scatter“ (първата)
- Сега ще се появи разпръснат сюжет и ние ще начертаем регресионната линия на това. За целта кликнете с десния бутон на мишката върху която и да е точка от данни и изберете „Добавяне на тенденция“
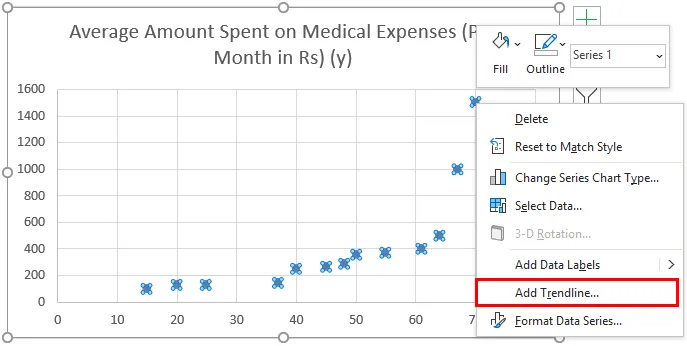
- Сега в панела „Форматиране на тенденция“ отдясно, изберете „Линейна тенденция“ и „Показване на уравнение на диаграма“.
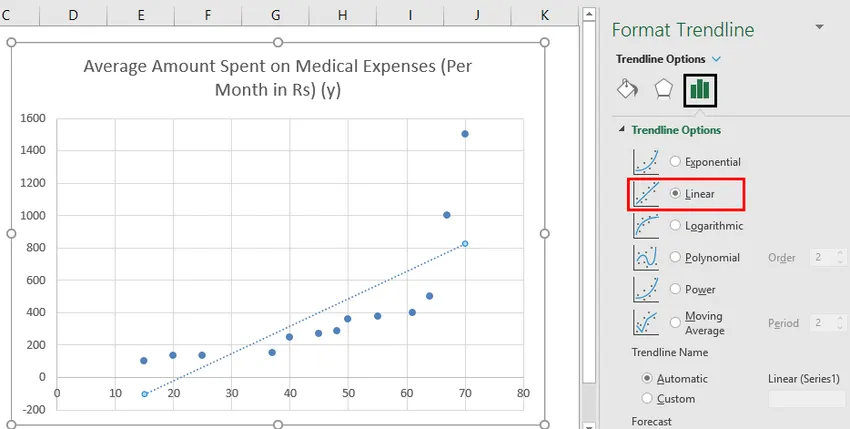
- Изберете „Уравнение за показване на диаграма“.
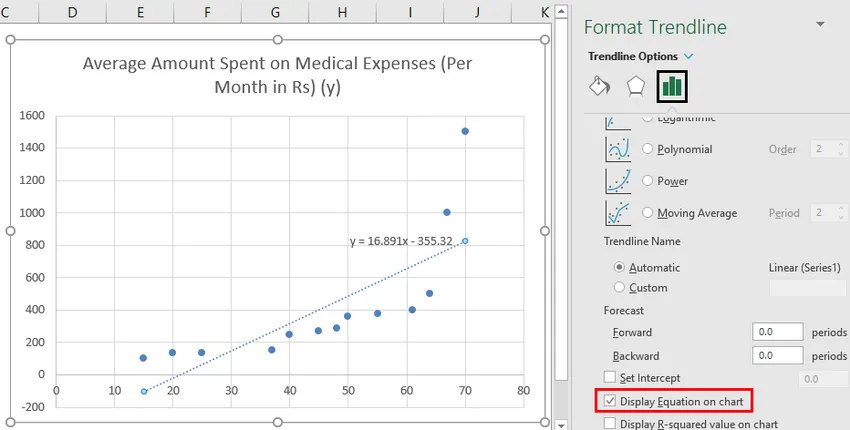
Можем да импровизираме диаграмата според нашите изисквания, като добавяне на заглавия на оси, промяна на мащаба, цвета и типа линия.
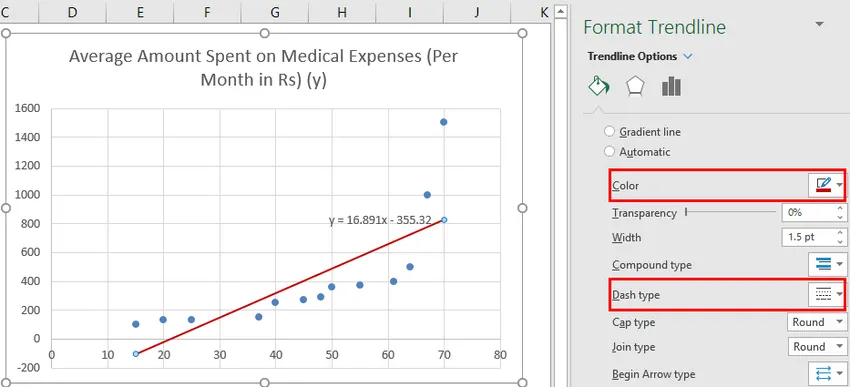
След импровизиране на диаграмата това е резултатът, който получаваме.

Метод №2 - Метод за добавяне на анализ ToolPak
Понякога Analysis ToolPak не е активиран по подразбиране и трябва да го направим ръчно. За да направите това:
- Кликнете върху менюто "Файл".
След това кликнете върху 'Опции'.
- Изберете „Добавки за Excel“ в полето „Управление“ и кликнете върху „Отиди“
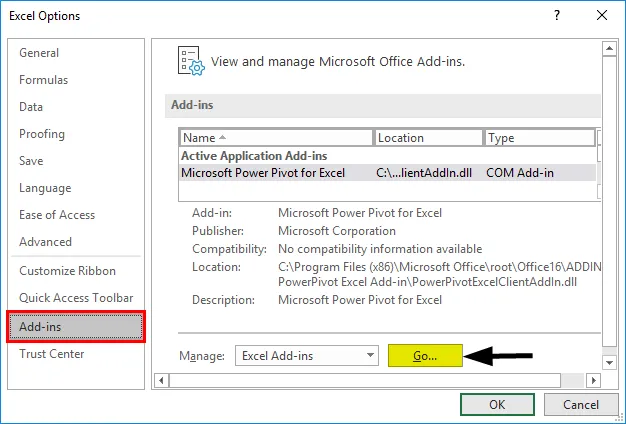
- Изберете „Анализ ToolPak“ -> „OK“
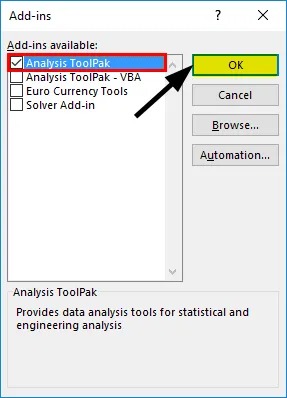
Това ще добави инструменти „Анализ на данни“ в раздела „Данни“. Сега провеждаме регресионния анализ:
- Кликнете върху „Анализ на данни“ в раздела „Данни“
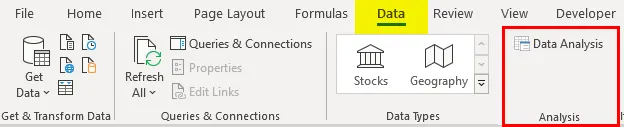
- Изберете „Регресия“ -> „ОК“
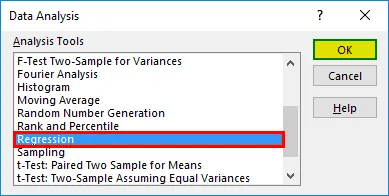
- Ще се появи диалогов прозорец за регресия. Изберете диапазона Input Y и диапазона Input X (медицински разходи и възраст, съответно). В случай на множествена линейна регресия можем да изберем повече колони от независими променливи (например, ако искаме да видим влиянието на ИТМ, както и върху медицинските разходи).
- Поставете отметка в квадратчето „Етикети“, за да включите заглавки.
- Изберете желаната опция „изход“.
- Поставете отметка в квадратчето „остатъци“ и кликнете върху „OK“.
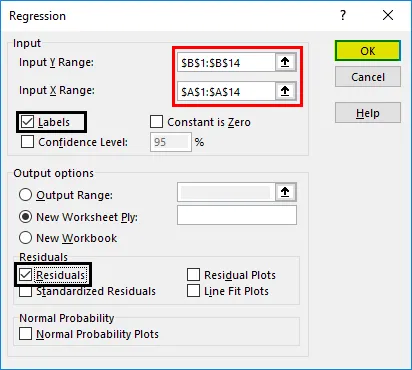
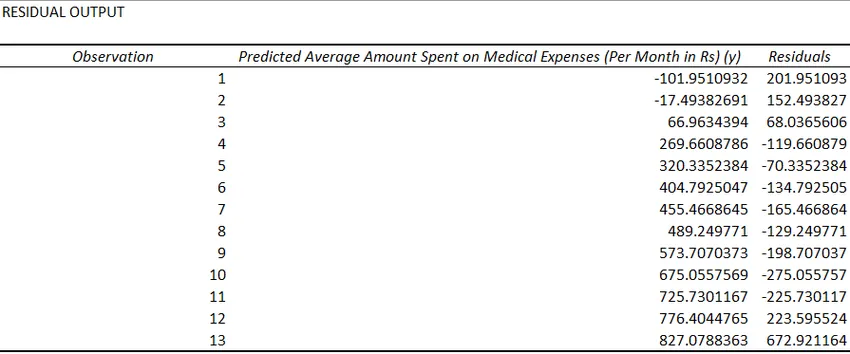
Сега нашите резултати от регресионния анализ ще бъдат създадени в нов работен лист, в който се посочват статистиката на регресията, ANOVA, остатъците и коефициентите.
Тълкуване на изхода:
- Регресионната статистика показва колко добре уравнението на регресия отговаря на данните:
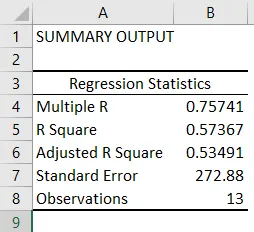
- Множество R е коефициентът на корелация, който измерва силата на линейната връзка между две променливи. Той лежи между -1 и 1, а абсолютната му стойност изобразява силата на връзката с голяма стойност, показваща по-силна връзка, ниска стойност показваща отрицателна и нулева стойност, показваща липса на връзка.
- R Square е Коефициентът на определяне, използван като индикатор за добро прилягане. Той лежи между 0 и 1, със стойност близка до 1, показваща, че моделът е подходящ. В този случай 0, 57 = 57% от y-стойностите се обясняват с x-стойностите.
- Регулиран квадрат R е R квадрат, коригиран за броя на прогнозите в случай на множествена линейна регресия.
- Стандартна грешка изобразява точността на регресионния анализ.
- Наблюденията изобразяват броя на наблюденията на модела.
- Anova казва нивото на променливост в регресионния модел.

Това обикновено не се използва за обикновена линейна регресия. Въпреки това „значения F стойности“ показват колко надеждни са нашите резултати със стойност по-голяма от 0, 05, което предполага да се избере друг предиктор.
- Коефициентите е най-важната част, използвана за изграждане на уравнение на регресия.

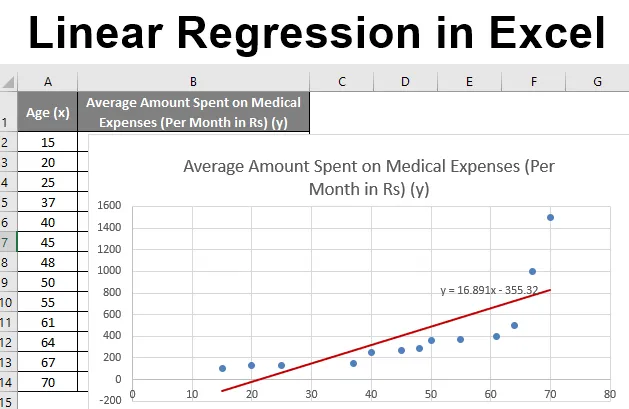
И така, нашето регресионно уравнение ще бъде: y = 16.891 x - 355.32. Това е същото като това, направено по метод 1 (разпръсна диаграма с тенденция).
Сега, ако искаме да прогнозираме средни медицински разходи, когато възрастта е 72:
Значи, y = 16.891 * 72 -355.32 = 860.832
Така че по този начин можем да предвидим стойности на y за всякакви други стойности на x.
- Остатъците показват разликата между действителните и прогнозираните стойности.
Последният метод за регресия не е толкова често използван и изисква статистически функции като наклон (), прехващане (), корел () и т.н., за да се извърши регресионен анализ.
Неща, които трябва да запомните за линейна регресия в Excel
- Обикновено се използва регресионен анализ, за да се установи дали има статистически значима връзка между две групи променливи.
- Използва се за прогнозиране на стойността на зависимата променлива въз основа на стойности на една или повече независими променливи.
- Винаги, когато желаем да приспособим линеен регресионен модел към група данни, тогава обхватът от данни трябва да бъде внимателно наблюдаван, сякаш използваме регресионно уравнение, за да прогнозираме някаква стойност извън този диапазон (екстраполация), тогава това може да доведе до грешни резултати.
Препоръчителни статии
Това е ръководство за линейна регресия в Excel. Тук обсъждаме как да правим линейна регресия в Excel, заедно с практически примери и шаблон за excel за сваляне. Можете да разгледате и другите ни предложени статии -
- Как да подготвим заплатите в Excel?
- Използване на MAX Formula в Excel
- Ръководства за справки за клетки в Excel
- Създаване на регресионен анализ в Excel
- Линейно програмиране в Excel