

Въведение в ANOVA в R
Следващата статия ANOVA в R предоставя контур за сравняване на средната стойност на различните групи. Анализът на вариацията (ANOVA) е много често срещана техника, използвана за сравняване на средната стойност на различните групи. Моделът ANOVA се използва за тестване на хипотези, при което се създава определено предположение или параметър за популация и статистическият метод се използва за определяне дали хипотезата е вярна или неверна.
Хипотезата се извлича от предположението на изследователя и наличната информация за населението. ANOVA се нарича Анализ на вариацията и се използва за тестване на хипотези, където се изисква измерване на средствата на променлива в множество независими групи.
Например, в лаборатория за изследване или изобретяване на ново лекарство за затлъстяване, изследователите ще сравнят резултата от експерименталното и стандартното лечение. При изследване за затлъстяване могат да се получат ценни резултати, когато средната степен на затлъстяване на популацията може да бъде сравнена в различни възрастови групи. В този случай бихме искали да наблюдаваме средната степен на затлъстяване сред различни възрастови групи, като възраст (5 до 18), (19, 35) и (36 до 50). Методът ANOVA се прилага, тъй като има повече от две групи, които са независими. Методът ANOVA се използва за сравнение на средното затлъстяване на независимите групи. Използва се функцията aov () и синтаксисът е aov (формула, данни = dataframe) В тази статия ще научим за модела ANOVA и допълнително ще обсъдим еднопосочния и двупосочен модел ANOVA заедно с примери.
Защо ANOVA?
- Тази техника се използва за отговор на хипотезата, докато се анализират множество групи данни. Има множество статистически подходи, но ANOVA в R се прилага, когато трябва да се направи сравнение на повече от две независими групи, както в предишния ни пример три различни възрастови групи.
- Техниката ANOVA измерва средната стойност на независимите групи, за да предостави на изследователите резултата от хипотезата. За да се получат точни резултати, трябва да се вземат предвид средствата на извадката, размера на пробата и стандартното отклонение от всяка отделна група.
- Възможно е да се наблюдава средно поотделно за всяка от трите групи за сравнение. Този подход обаче има ограничения и може да се окаже неправилен, тъй като тези три сравнения не вземат предвид общите данни и по този начин могат да доведат до грешка от тип 1. R ни предоставя функцията да провеждаме ANOVA анализа, за да изследваме променливостта между независимите групи данни. Има пет етапа на провеждане на ANOVA анализа. На първия етап данните се подреждат във формат csv и колоната се генерира за всяка променлива. Една от колоните ще бъде зависима променлива, а останалите са независимата променлива. На втория етап данните се четат в R студио и се назовават по подходящ начин. На третия етап се прикрепя набор от данни към отделни променливи и се чете от паметта. И накрая, ANOVA в R се дефинира и анализира. В следващите раздели съм предоставил няколко примера от казуси, в които трябва да се използват техники на ANOVA.
- Шест инсектициди бяха тествани на 12 полета всяко и изследователите преброиха броя на бъговете, останали във всяко поле. Сега фермерите трябва да знаят дали инсектицидите имат някаква разлика и ако да, кой от тях най-добре използват. Отговаряте на този въпрос, като използвате функцията aov (), за да извършите ANOVA.
- Петдесет пациенти са получили едно от петте лечения за намаляване на холестерола (trt). Три от състоянията на лечение включват едно и също лекарство, прилагано като 20 mg веднъж на ден (1 път) 10 mg два пъти на ден (2 пъти) 5 mg четири пъти на ден (4 пъти). Двете останали състояния (drugD и drugE) представляват конкурентни лекарства. Кое лекарствено лечение доведе до най-голямо намаляване на холестерола (отговор)?
АНОВА Еднопосочна
- Еднопосочният метод е една от основните ANOVA техника, при която се прилага анализ на дисперсия и се сравнява средната стойност на множество групи от населението.
- Еднопосочната ANOVA получи името си поради наличието на еднопосочни класифицирани данни. В еднопосочна ANOVA единична променлива и една или повече независими променливи могат да бъдат на разположение.
- Например, ние ще изпълним ANOVA техниката на холестерола. Наборът от данни се състои от две променливи trt (които са третиране на 5 различни нива) и променливи на отговора. Независима променлива - групи от лекарствено лечение, зависима променлива - средства от 2 или повече групи ANOVA. От тези резултати можете да потвърдите, че приемането на дози от 5 mg 4 пъти на ден е по-добро от приемането на доза от двадесет mg веднъж на ден. Лекарството D има по-добри ефекти в сравнение с това лекарство Е
Лекарството D осигурява по-добри резултати, ако се приема в дози от 20 mg в сравнение с лекарството Е
Използва набор от данни за холестерола в многокомплектния пакетinstall.packages('multcomp')
library(multcomp)
str(cholesterol)
attach(cholesterol)
aov_model <- aov(response ~ trt)
ANOVA F тестът за лечение (trt) е значителен (p <.0001), което дава доказателство, че петте лечения
# не всички са еднакво ефективни.
резюме (aov_model)
откачване (холестерол)

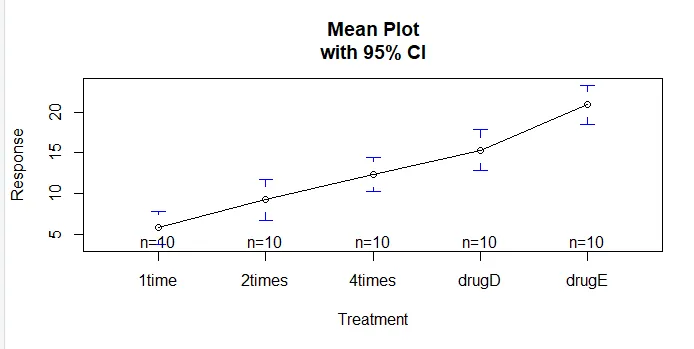
Функцията plotmeans () в пакета gplots може да се използва за получаване на графика на групови средства и техните интервали на доверие Това ясно показва разликите в лечениетоinstall.packages('gplots')
library(gplots)
plotmeans(response ~ trt, xlab="Treatment", ylab="Response",
main="Mean Plot\nwith 95% CI")
Нека да проучим изхода от TukeyHSD () за двойни различия между средните групи
TukeyHSD (aov_model)
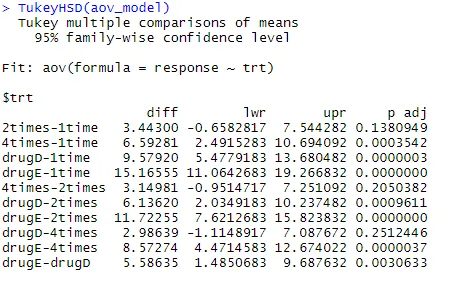
Средното намаление на холестерола за 1 път и 2 пъти не се различава значително едно от друго (p = 0.138), докато разликата между 1 и 4 пъти е значително различна (p <.001).
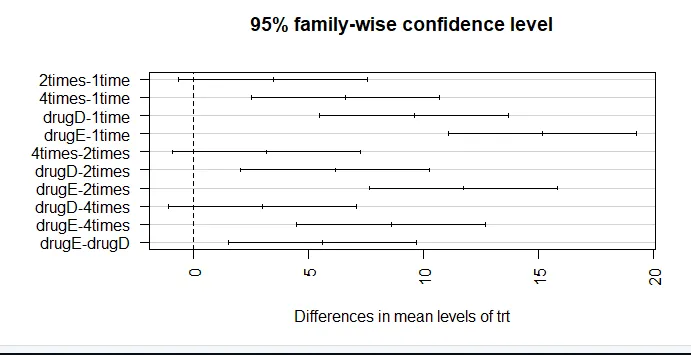
par (mar = c (5, 8, 4, 2)) # увеличение на лявата граница на граница (TukeyHSD (aov_model), las = 2)
Увереността в резултатите зависи от степента, в която вашите данни отговарят на предположенията, залегнали в статистическите тестове. При еднопосочна ANOVA се приема, че зависимата променлива е нормално разпределена и има еднаква дисперсия във всяка група. Можете да използвате QQ график за оценка на библиотеката на предположения за нормалност (кола).
QQ график (lm (отговор ~ trt, данни = холестерол), симулира = ИСТИНСКИ, главен = "QQ график", етикети = ЛЕГЛО)
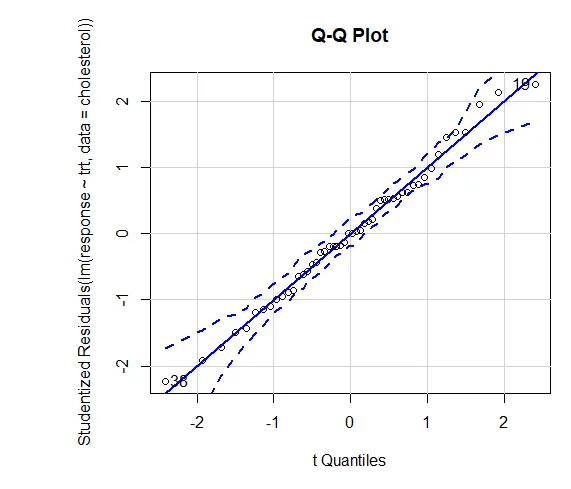
Пунктирана линия = 95% доверителен плик, което предполага, че предположението за нормалност е изпълнено сравнително добре ANOVA предполага, че отклоненията са равни по групи или проби. Тестът на Бартлет може да се използва за проверка на това предположение
bartlett.test (отговор ~ trt, данни = холестерол). Тестът на Бартлет показва, че дисперсиите в петте групи не се различават значително (p = 0, 97).
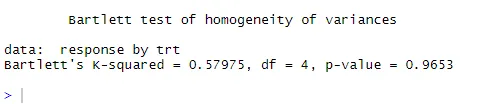
ANOVA също е чувствителен към тест за външни хора за външни хора, използвайки функцията outlierTest () в автомобилния пакет. Може да не е необходимо да стартирате този пакет, за да актуализирате библиотеката на автомобила си.update.packages(checkBuilt = TRUE)
install.packages("car", dependencies = TRUE)
library(car)
outlierTest(aov_model)
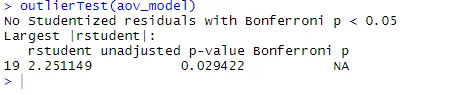
От изхода можете да видите, че няма данни за остатъците в данните за холестерола (NA се появява, когато p> 1). Като вземем QQ графиката, теста на Бартлет и външния тест заедно, изглежда, че данните отговарят доста добре на модела ANOVA.
Двупосочна Анова
Друга променлива се добавя в двупосочния тест за ANOVA. Когато има две независими променливи, ще трябва да използваме двупосочна ANOVA, а не еднопосочна ANOVA техника, която беше използвана в предишния случай, когато имахме една непрекъсната зависима променлива и повече от една независима променлива. За да се провери двупосочната ANOVA, трябва да бъдат изпълнени множество предположения.
- Наличие на независими наблюдения
- Наблюденията трябва да бъдат нормално разпределени
- Разминаването трябва да е равно на наблюдения
- Не бива да присъстват външни лица
- Независими грешки
За да се провери двупосочната ANOVA към променливата се добавя друга променлива, наречена BP. Променливата показва скоростта на кръвното налягане при пациенти. Бихме искали да проверим дали има някаква статистическа разлика между BP и дозата, дадена на пациентите.
df <- read.csv ("file.csv")
ге
anova_two_way <- aov (отговор ~ trt + BP, данни = df)
резюме (anova_two_way)
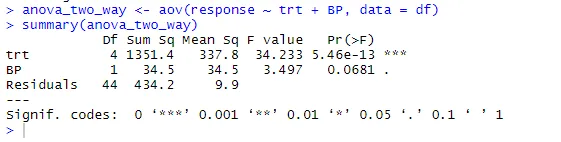
От изхода може да се заключи, че и trt и BP са статистически различни от 0. Следователно, хипотезата на Null може да бъде отхвърлена.
Предимства на ANOVA в R
ANOVA тестът определя разликата в средната стойност между две или повече независими групи. Тази техника е много полезна за анализ на множество артикули, което е от съществено значение за анализа на пазара. Използвайки ANOVA теста, можете да получите необходимата информация за данните. Например по време на проучване на продукти, при което от потребителите се събират множество информация като списъци за пазаруване, харесвания на клиенти и нехаресвания. Тестът ANOVA ни помага да сравним групи от населението. Групата може да бъде мъже срещу жени или различни възрастови групи. Техниката ANOVA помага да се направи разлика между средните стойности на различните групи от населението, които наистина са различни.
Заключение - ANOVA в R
ANOVA е един от най-често използваните методи за тестване на хипотези. В тази статия ние извършихме ANOVA тест върху набора от данни, състоящ се от петдесет пациенти, които са лекувани с холестерол, редуциращи лекарства и по-нататък видяха как може да се извърши двупосочна ANOVA, когато е налична допълнителна независима променлива.
Препоръчителни статии
Това е ръководство за ANOVA в R. Тук обсъждаме Еднопосочен и двупосочен модел Anova заедно с примери и предимства на ANOVA. Можете да разгледате и другите ни предложени статии -
- Регресия срещу ANOVA
- Какво е SPSS?
- Как да интерпретираме резултатите, използвайки ANOVA тест
- Функции в R