

Разлики между Sqoop и Flume
Sqoop е продукт от софтуер Apache. Sqoop извлича полезна информация от Hadoop и след това преминава към външните хранилища на данни. С помощта на Sqoop можем да импортираме данни от RDBMS или мейнфрейм в HDFS. Flume също е от софтуера на Apache. Той събира и премества рекурсивните данни, които се генерират. Apache Flume не е ограничен само за събиране на данни за регистриране, но източниците на данни са адаптивни и по този начин Flume може да се използва за транспортиране на огромни количества данни. Най-добрият начин за събиране, агрегиране и преместване на големи количества данни между разпределената файлова система Hadoop и RDBMS е чрез използване на инструменти като Sqoop или Flume.
Нека обсъдим тези два често използвани инструмента за гореспоменатата цел.
Какво е Sqoop
За да използва Sqoop, потребителят трябва да посочи инструмента, който потребителят иска да използва, и аргументите, които контролират конкретния инструмент. След това можете да експортирате данните обратно в RDBMS с помощта на Sqoop. Експортната функционалност на Sqoop се използва за извличане на полезна информация от Hadoop и експортирането им във външни структурирани хранилища на данни. Работи с различни бази данни като Teradata, MySQL, Oracle, HSQLDB.
- Sqoop Архитектура: -
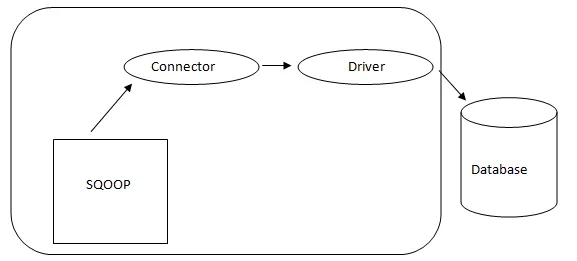
Архитектура на Sqoop
Връзката в Sqoop е плъгин за определен източник на база данни, така че е от съществено значение той да е част от установяването на Sqoop. Въпреки факта, че драйверите са специфични за базата данни части и се разпространяват от различни доставчици на база данни, самият Sqoop се предлага в комплект с различни видове конектори, използвани за преобладаващата система за съхранение на база данни и информация. По този начин Sqoop се доставя и със смесено разнообразие от конектори. Sqoop дава подключаем компонент за идеална мрежа и външна система. API на Sqoop дава полезна структура за сглобяване на нови конектори и следователно всички конектори на база данни могат да бъдат пуснати в инсталацията на Sqoop, за да се осигури свързаност към различни системи за данни.
Какво е Flume
Apache Flume не е ограничен само до събиране на данни за регистриране на данни, но източниците на данни са адаптивни и по този начин Flume може да се използва за транспортиране на огромни количества данни, включително, но не само, имейл съобщения, генерирани от социални медии данни, данни от мрежовия трафик и почти всякакви възможен източник на данни.
Flume архитектура: - Flume архитектура се основава на много основни концепции:
- Flume Event - тя е представена като единица за поток на данни, която има байтов полезен товар и набор от низове с незадължителни заглавни низове. Flume счита събитие само за родово байтове.
- Flume Agent - Това е JVM процес, който хоства компонентите като канали, мивка и източници. Той има потенциал да приема, съхранява и препраща събитията от външен източник на следващото ниво.
- Flume Flow - това е моментът, в който събитието се генерира.
- Flume Client - той се отнася до интерфейса, в който клиентът оперира в началната точка на събитието и го доставя на агента Flume.
- Източник - Източникът е този, който консумира събития със специфичен формат и го доставя чрез специфичен механизъм.
- Канал - Това е пасивен магазин, където се провеждат събития, докато мивката не го отстрани за по-нататъшно транспортиране.
- Sink - Премахва събитието от канал и го поставя във външно хранилище като HDFS. В момента поддържа създаването на текстови и последователни файлове и поддържа компресия и в двата типа файлове.
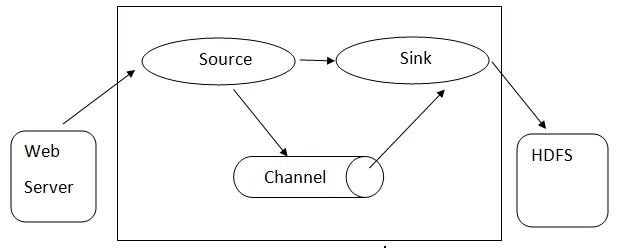
Архитектура на Flume
Сравнение между главата на Sqoop срещу Flume (Инфографика)
По-долу е топ 7 сравнението между Sqoop срещу Flume

Ключови разлики между Sqoop срещу Flume
Вече знаем, че има много разлики между Sqoop срещу Flume, ето най-важните разлики между тях, дадени по-долу -
1. Sqoop е предназначен за обмен на масова информация между Hadoop и релационна база данни.
Като има предвид, че Flume се използва за събиране на данни от различни източници, които генерират данни относно конкретен случай на използване и след това прехвърля това голямо количество данни от разпределени ресурси в едно централизирано хранилище.
2. Sqoop също включва набор от команди, който ви позволява да инспектирате базата данни, с която работите. По този начин можем да разгледаме Sqoop като колекция от свързани инструменти.
Докато събира датата, Flume мащабира данните хоризонтално и множество агенти на Flume могат да бъдат пуснати в действие за събиране на датата и обобщаването им. След това регистрационните файлове се преместват в централизирано хранилище за данни, т.е. разпределена файлова система Hadoop (HDFS).
3. Основният фактор за използването на Flume е, че данните трябва да се генерират непрекъснато и поточно. По подобен начин Sqoop е най-подходящ в ситуации, когато вашите данни живеят в системи от бази данни като MySQL, Oracle, Teradata, PostgreSQL
Sqoop срещу Flume (Сравнителна таблица)
| Основа за сравнение | SQOOP | воденичен улей |
|
Основна природа | Sqoop работи добре с всеки RDBMS, който има JDBC (Java Database Connectivity) като Oracle, MySQL, Teradata и т.н. | Flume работи добре за поточен източник на данни, който непрекъснато генерира като регистрационни файлове, JMS, директория, доклади за сривове и др. |
| Поток от данни | Sqoop, специално използван за паралелен трансфер на данни. Поради тази причина изходът може да бъде в няколко файла | Flume се използва за събиране и агрегиране на данни поради разпространения му характер. |
| Водени събития | Sqoop не се движи от събития. | Flume е изцяло управляван от събития. |
| архитектура | Sqoop следва базирана на конектори архитектура, което означава конектори, знае как да се свърже с различен източник на данни. | Flume следва архитектура, базирана на агент, където кодът, написан в него, е известен като агент, който е отговорен за получаването на данни. |
| Къде да използвам | Използва се предимно за по-бързо копиране на данни и след това за генериране на аналитични резултати. | Обикновено се използва за изтегляне на данни, когато компаниите искат да анализират модели, основни причини или анализ на настроенията с помощта на регистрационни файлове и социални медии. |
| производителност | Намалява прекомерните товари за съхранение и обработка, като ги прехвърля към други системи и има бърза производителност. | Flume е устойчив на повреди, здрав и има механизъм за надеждност при отказ и възстановяване. |
| История на изданията | Първата версия на Apache Sqoop стартира през март 2012 г. Текущата стабилна версия е 1.4.7 | Първата стабилна версия 1.2.0 на Apache Flume стартира през юни 2012 г. Текущата стабилна версия е Apache Flume версия 1.8.0. |
Заключение - Sqoop срещу Flume
Както научихте по-горе Sqoop и Flume, се използват предимно два инструмента за поглъщане на данни е светът Big Data. Ако трябва да въведете текстови данни от регистрационния файл в Hadoop / HDFS, тогава Flume е правилният избор за това. Ако вашите данни не се генерират редовно, Flume ще продължи да работи, но това ще бъде излишно за тази ситуация. По подобен начин Sqoop не е най-подходящото за управление на данни, управлявано от събития.
Препоръчителни статии
Това е ръководство за разликите между Sqoop срещу Flume, тяхното значение, сравнение между главата, ключови разлики, таблица за сравнение и заключение. тази статия се състои от всички полезни разлики между Sqoop и Flume. Можете също да разгледате следните статии, за да научите повече
- Hadoop срещу Teradata - полезни разлики за учене
- 5 Най-важната разлика между Apache Kafka срещу Flume
- Големи данни срещу Apache Hadoop - Топ 4 сравнение, което трябва да научите
- 5 Най-важната разлика между Apache Kafka срещу Flume
- Важен текстов майнинг срещу обработка на естествен език - топ 5 сравнения