
Разлика между HBase и Cassandra
HBase е база данни, която използва разпределената файлова система Hadoop за съхранението си. HBase е важна част от HDFS и работи на върха на Hadoop Cluster. HBase не е традиционна релационна база данни, тя изисква различен подход за моделиране на данни. Cassandra работи по модела за репликация на данните, така че в случай на липса на който и да е възел няма да има загуба на данни. Cassandra е разпределена база данни, означава, че данните могат да бъдат достъпни от клиент от всеки клъстер и от всеки възел
1.1) Касандра:
Той беше стартиран от Facebook, тъй като винаги е в изискването за кандидатстване. Cassandra е създаден през 2005 г. и е достъпен за обществеността през 2008 г. Cassandra е разработен за винаги включени приложения като социални мрежи като Facebook и Twitter.
Касандра работи върху „винаги включена“ архитектура и има модел на Active-Active възел, така че няма SPoF (Единична точка на отказ). CQL (Cassandra Query Language) е езикът на заявките на Cassandra, но има синтаксис същият като SQL. Той поддържа всички основни ОС като Linux, Unix, OSX и Windows.
Винаги включен:
Cassandra е база данни с модел на разпределение и всички възли са еднакви в клъстера. Данните се репликират на конфигурируеми възли, така че в случай на отказ на някои не. от възлите няма да доведе до загуба на данните.
(Винаги на модел)
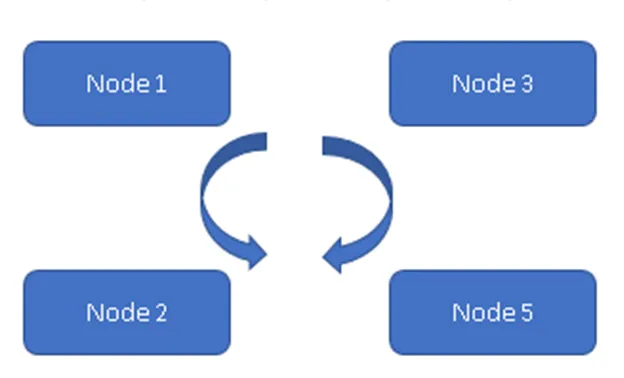
На фигура 1, четирите възли са в синхрон един с друг и репликират данните в клъстера. Всички работят по Active-Active Model, така че в случай на повреда на възел няма да доведе до загуба на данни. Клиентът може да прочете данните от останалите налични възли / възли.
1.2) HBase:
HBase е базирана на NoSQL база данни и е предназначена за обработка на заявки в големи таблици с милиарди редове с милиони колони и преминаваща през клъстер от стоков / нормален хардуер. Той ви предоставя възможности за заявки в реално време със скоростта на „ ключ / стойност магазин “ .
HBase всъщност се основава / работи върху четириизмерен модел на данни.
- Идент. Ред / ключ на реда
- Семейство колони.
- Двойки ключ-стойност.
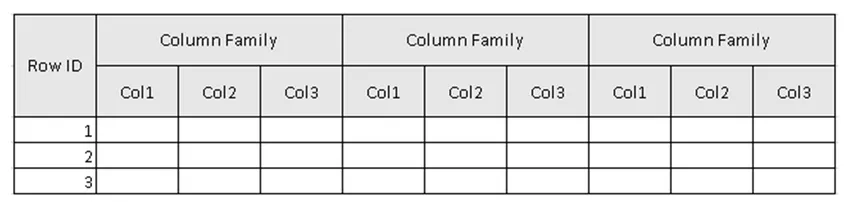
(Фигура 2, Примерна схема на таблицата в HBase.)
На фигура 2, таблицата е колекцията на семейството на колоните и семейството на колоните е колекцията от колони. Колоните са колекцията от двойки ключ-стойност
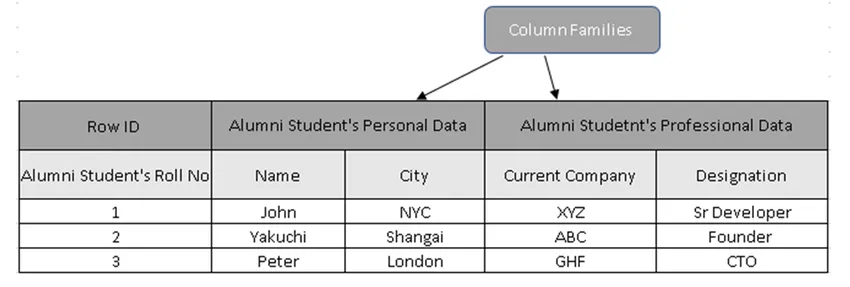
(Фигура 3, Примерна таблица в HBase)
На фигура 3 семействата на колоните представляват събирането на данни на учениците на възпитаници, а идентификационните номера на редовете (ключови редове) съдържат номер на студентския списък.
Всъщност Row Keys притежават уникалната стойност спрямо данните от семейството на колоните. С помощта на редовия ключ можете да извлечете всички подробности, причините, поради които базите на колони, базирани на данни, са много по-бързи от традиционните бази данни.
Apache HBase може да се използва за произволен достъп за четене / запис и осигурява поддръжка при отказ. Той също така поддържа репликация и работа върху модела на база данни за разпространение.
Сравнение между главата на HBase и Cassandra (Инфографика)
По-долу е топ 9 разликата между HBase срещу Cassandra
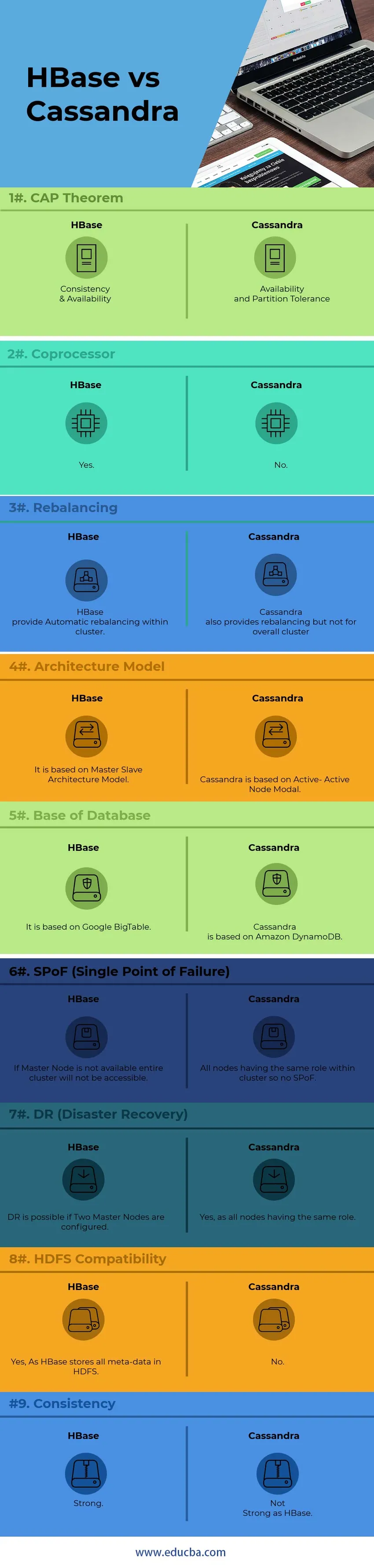 Ключови разлики между HBase срещу Cassandra
Ключови разлики между HBase срещу Cassandra
По-долу са списъците с точки, опишете основните разлики между HBase и Cassandra:
1) За вътрешна комуникация с възел, Cassandra използва GOSSIP протокол, докато HBase е базиран на Zookeeper. Услугите на протокола GOSSIP са интегрирани с Cassandra от друга страна Zookeeper е изцяло отделно приложение за разпространение.
2) В архитектурата на Касандра, всички възли работят като активен възел, докато архитектът HBase следва модела Master-Slave Node. В модела Active-Active Node няма SPoF (Single Point of Failure). В HBase, ако Master възелът се спусне, целият клъстер няма да бъде достъпен.
3) Поддръжка на HBase модел за търсене на двоично дърво, докато Cassandra не поддържа модел B-Tree Без B-Tree, не можете да търсите Семейство на колоните на потребителя за всички с юбилей през април, докато можете да търсите всички, които живеят в Пекин с Годишнина през април.
4) HBase, поддръжка на C, C ++, Java, Python, скриптов език Scala, докато Cassandra също поддържа JavaScript & Ruby.
5) HBase има една функция, наречена като копроцесори, докато Cassandra няма такава функция, както сега. Копроцесорите осигуряват библиотека и среда за изпълнение за изпълнение на потребителски код в сървъра на HBase региона и главните процеси.
6) HBase е проектиран да поддържа хранилище на данни, докато Cassandra ще бъде перфектен за постоянно работещи приложения като уеб и мобилни приложения.
7) HBase езикът на заявките е персонализиран език, който трябва да се научи, докато Cassandra използва собствен разработен CQL (Cassandra Query Language), който е подобен на SQL език
8) Управлението на Касандра е много по-лесно от HBase. В Касандра трябва да се стартира един Java процес на възел, докато за HBase са необходими напълно работещи HDFS, няколко HBase процеси и система Zookeeper.
9) HBase свършва с контролни суми и автоматично балансиране, докато Cassandra не поддържа балансирането на клъстера като цяло.
10) Въз основа на „ Теоремата за CAP“, Касандра работи по AP Model, докато HBase е CP Model.
Теорема на ОСП
Тази теорема се използва за разпределени системи. C означава консистенция, а означава наличност и P е толерантност на дяловете. CAP теорема обяснена по-долу:
C (последователност): последователност означава, че ако някой е написал стойност в база данни, други могат веднага да прочетат същата стойност.
A (Наличност) : Наличността означава, че ако някои възли не са налични във вашия клъстер (Възли изчезнаха / не живеят в клъстера поради някакъв проблем) няма да повлияят на целия клъстер и Разпределената система / Базата данни ще бъде достъпна за достъп до данните. Клъстерът ще бъде достъпен за всички видове задачи.
P (Толерантност на дяловете): Толерантност на дяла означава, ако един Център за данни все още се понижи, което не трябва да засяга представените данни на възлите и всички данни трябва да са достъпни по всяко време. Средства, Толерантността на дяловете позволява по-добро възпроизвеждане на данни в друг Център за данни, както и в клъстерната среда.
Таблица за сравнение на HBase срещу Cassandra
| точки | HBase | Касандра |
| Теорема на ОСП | Съгласуваност и наличност | Наличност и толерантност на дяла |
| Coprocessor | да | Не |
| Ребалансирането | HBase осигурява автоматично възстановяване на баланса в клъстер. | Касандра също осигурява балансиране, но не и за цялостния клъстер |
| Модел на архитектурата | Той се базира на модел на архитектура Master-Slave | Cassandra се основава на Active-Active Nod Modal |
| База данни | Той се базира на Google BigTable | Cassandra е базиран на Amazon DynamoDB |
| SPoF (единична точка на отказ) | Ако Master Node не е налице, целият клъстер няма да бъде достъпен | Всички възли, които имат една и съща роля в клъстера, така че няма SPoF |
| DR (възстановяване при бедствия) | DR е възможен, ако са конфигурирани два главни възла. | Да, тъй като всички възли имат една и съща роля |
| Съвместимост с HDFS | Да, тъй като HBase съхранява всички метаданни в HDFS | Не |
| съгласуваност | силен | Не е силен като HBase |
Заключение - HBase срещу Cassandra
Facebook и друга страна в социалните мрежи биха предпочели HBase (по-рано и двамата използваха Cassandra, вижте публикация във Facebook), поради наличието на другия сектор на банковия домейн търси сигурност за всяка своя финансова транзакция, така че те биха избрали Cassandra над HBase.
Касандра Основните характеристики включват висока наличност, минимално администриране и без SPoF (единична точка на отказ) друга страна HBase е добра за по-бързо четене и записване на данни с линейна мащабируемост.
Компании като Verizon, Bloomberg, Bank of America и много други използват HBase, а Cassandra се използва от големи сайтове за социални мрежи като Twitter, Facebook и т.н. …
Не можем да заключим кой е най-добрият, HBase и Cassandra имат своите предимства и недостатъци. Реалното представяне както на HBase, така и на Cassandra Databases може да се види в производствената среда.
Препоръчани статии:
Това е ръководство за HBase срещу Касандра, тяхното значение, сравнение между главата, ключови разлики, таблица на сравнението и заключение. Можете също да разгледате следните статии, за да научите повече -
- Hadoop vs Apache Spark - интересни неща, които трябва да знаете
- Как да разбиете интервюто за разработчици на Hadoop?
- Топ 5 големи тенденции на данни
- 5 предизвикателства на Big Data Analytics