

Как да инсталирате Apache
Преди да въведете как да инсталирате частта Apache, първо ще имаме общ преглед на Apache и как се използва в науката за данни.
Какво е Apache?

Apache Web Server е HTTP сървър, който представя уебсайтове на посетителите, които идват на вашия сървър. Така че, ако искате да разгърнете уебсайт за бизнес или организация, най-вероятно ще използвате Apache за това.
Има и други HTTP сървъри, като IIS, но Apache е стандартът, който повечето хора използват, независимо дали са на Linux, Windows или Mac. Apache е по подразбиране, на което отиват повечето хора, защото е добре известен, много е надежден и е безплатен.
Все пак едно нещо, което трябва да осъзнаете с Apache е, че тъй като това е HTTP сървър, така че ако инсталирате това на Linux или Windows или Mac, всичко, което би ви позволило да направите, е да представяте статични уебсайтове на посетителите, идващи на вашия сървър. Следователно, ако кодирате HTML уебсайт без други езици за програмиране, различни от JavaScript, можете да го използвате само с Apache сървър. Можете да включите всичките си маркери в Apache сървъра и да го представите на своите посетители.
Как Apache използва в Data Science?
Data Science е най-търсената област на изучаване в съвременния свят. Data Scientist се счита за най-сексапилната работа в 21 век с професионалисти от различни дисциплини, които искат да учат и да станат Data Scientist. Apache играе решаваща роля за всеки ентусиаст на науката за данни, тъй като те се нуждаят от достатъчно познания за екосистемата Apache Hadoop.
Екосистема Apache Hadoop
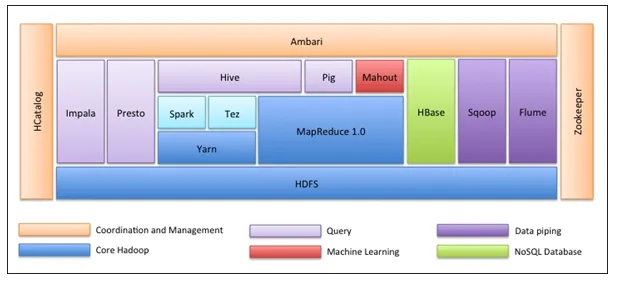
Първото нещо е, че екосистемата Hadoop не е един инструмент. Това не е език за програмиране или единна рамка. Това е група инструменти, които се използват заедно от различни компании в различни области за множество задачи. Ще прегледаме всеки инструмент един по един по-долу: -
- Apache HDFS (Hadoop Distributed File System) е единицата за съхранение на Hadoop, която може да съхранява структурирани, полуструктурирани и неструктурирани данни. HDFS има метаданни, които поддържат журналния файл за съхранените данни. Той има два компонента - NameNode и DataNode.
- Apache Прежда е преговарящият ресурс, който изпълнява всички дейности по обработка, като задачи за планиране, разпределяне на ресурси и т.н. Той има две услуги - Първо е Мениджърът на ресурсите, който планира приложения, работещи на върха на Преждата. На второ място е Node Manager, който следи използването на ресурсите .
- Apache Map Reduce е компонентът за обработка на данни на Hadoop, който обработва големи набори от данни, използвайки разпределени и паралелни изчисления въз основа на функциите Map, Sort and Shuffle и Reduce. Функцията Map филтрира данните, след това се извършва сортиране и разбъркване, а в края Намаляването на функцията се агрегира и обобщава резултата.
- Apache Pig използва предимно в ETL. Той има две части - Свинско латински и Свинско време на изпълнение. Pig Latin е езикът, използван за обработка на данни с помощта на заявка, докато Pig time е средата за изпълнение. Един ред от Pig Latin е почти равен на 100 реда от кода за намаляване на картата. Процесът включва първо да се заредят данните и след това да се групират, сортират, филтрират и съхраняват в HDFS.
- Apache Hive използва SQL-подобна заявка за анализ на данни в разпределена среда. Той има два компонента - командния ред на Hive и JDBC / ODBC сървъра, а използваният език се нарича HiveQL.
- Apache Mahout е библиотеката за машинно обучение, написана на Java и използвана за създаване на приложения за машинно обучение като клъстериране, класификация или регресия. Той има различни алгоритми, вградени за различни случаи на използване.
- Apache HBase е база данни NoSQL, написана на Java, която работи над Hadoop. Той е създаден на базата на BigTable на Google и може да обработва всички видове данни.
- Apache Sqoop е инструментът за поглъщане на данни, който се използва за групово структуриран трансфер на данни между RDBMS и Hadoop.
- Apache Flume е друг инструмент за приемане на данни, който се използва за полуструктуриран и неструктуриран трансфер на данни между Hadoop и други източници на данни.
- ZooKeeper е координаторът, който осигурява координация между различни инструменти в екосистемата Hadoop.
- Apache Ambari е мениджър на клъстери, който осигурява, управлява клъстери от Hadoop, а също така следи тяхното здраве и състояние.
- Apache Tez е нов инструмент в екосистемата Hadoop, който ускорява обработката на заявките на Hadoop.
- Apache Presto е SQL заявка за разпространение с отворен код, която дава възможност за търсене на крос-платформа.
- Apache HCatalog е система за управление на метаданни и таблици за Hadoop, която дава възможност за оперативна съвместимост чрез инструменти за обработка на данни. Освен това помага на потребителите да изберат най-добрите инструменти за своята среда.
- Apache Spark е най-използваната и популярна рамка сред Data Scientist. Това е високоскоростна клъстерна изчислителна система, която оптимизира използването на ресурси в случай на много итеративни задачи. Тя дава гъвкавост както за пакетната обработка, така и за анализ на данни в реално време.
По-долу са стъпките за инсталиране на Apache
Досега научихме за Apache и как е полезно за всеки, който иска да научи Data Science или Big Data Analytics. Сега ще се гмурнем надолу и ще инсталираме apache на Windows на базата на стъпките по-долу.
- Отидете на https://httpd.apache.org/ и кликнете върху връзката за изтегляне под Apache httpd 2.4.38 Издаден раздел.

- Той ще ви отведе до следващата страница и след това щракнете върху Файлове за Microsoft Windows.
- Кликнете върху Apache Lounge.

- Можете да изтеглите 32-битов или 64-битов от zip файла въз основа на вашата операционна система Windows. Тук ще изтеглим 64-битова версия. Кликнете върху съответната .zip връзка, за да изтеглите.

- Сега той изисква C ++ Redistributable Visual Studio 2017. Така че ще го изтеглим от съответната 32-битова или 64-битова връзка

- След като и двата файла бъдат изтеглени, първо ще отидем на изтегленото място и първо ще инсталираме C ++ Redistributable Visual Studio 2017. Кликнете два пъти върху .exe файла.

- Поставете отметка „Съгласен съм“ и щракнете върху Инсталиране.

- Инсталирането на Apache е в ход.
- След като приключи, ще получите съобщение като това. Щракнете върху Затвори, за да завършите инсталацията.
- Сега отидете в папката, в която изтеглите zip файла Apache. Щракнете с десния бутон върху него и изберете извлечение тук.
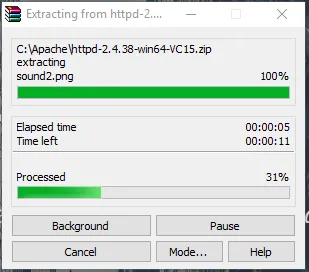
- Сега ще създадем папка Apache24. Копирайте тази папка в C устройство, след което ще добавим път към променливите на системната среда.
Отидете на Свойства на системата -> Раздел Разширени -> Кликнете върху бутона Променливи на околната среда по-долу.
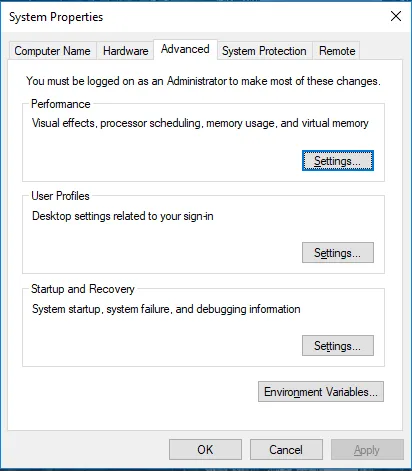
- В Променливи намерете Path и щракнете върху Редактиране.
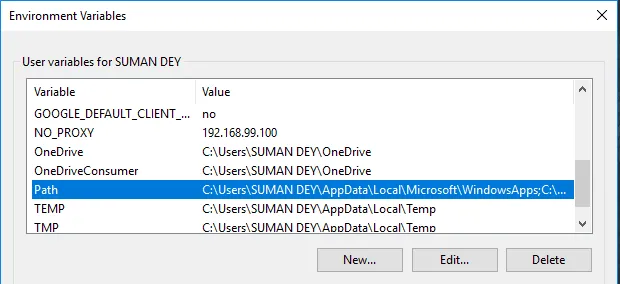
- Щракнете върху Преглед -> Отидете на папка C диск Apache24 -> Изберете папка за кошче -> Щракнете върху ОК.
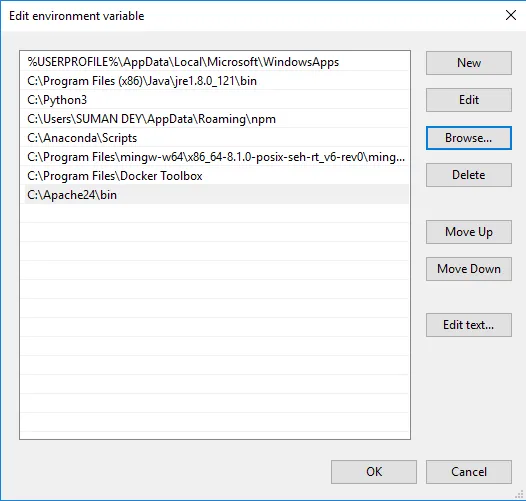
- Ще инсталираме Apache като услуга на Windows. Изпълнете командния ред като администратор. Въведете httpd –k install и натиснете enter.
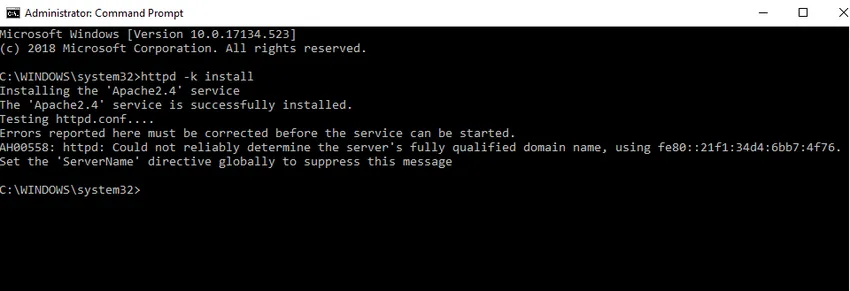
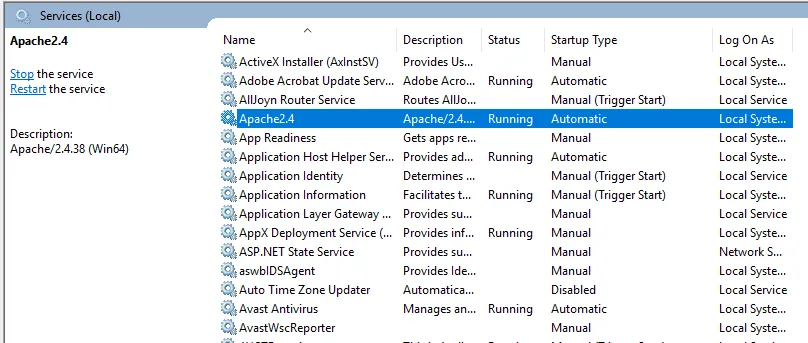
- Ще проверим услугата за инсталиране Apache. Кликнете върху иконата на Windows и въведете услуги. Кликнете върху приложението Услуги и намерете услуга с името Apache24.

- За да стартирате сървъра Apache, щракнете с десния бутон върху него и щракнете върху старт. Състоянието ще се промени на „Работещо“.
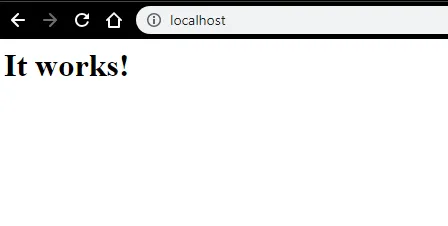
- Можем да тестваме с браузър. Отворете браузър и отворете http: // localhost и натиснете Enter. Съобщение, в което се казва „Работи!“ ще изскочи, за да потвърди успешната инсталация на Apache.
Препоръчителни статии
Това е ръководство за това как да инсталирате Apache. Тук сме обсъдили инструкциите и различните стъпки за инсталиране на Apache. Можете също да разгледате следната статия, за да научите повече -
- Въпроси за интервю на Apache
- Apache Spark срещу Apache Flink
- Apache Hadoop срещу Apache Spark
- Apache Kafka срещу Flume
- Кафка срещу Кинезис | Топ разлики