

Разлика между извличане на данни и уеб майнинг
Извличане на данни : Това е концепция за идентифициране на значителен модел от данните, който дава по-добър резултат. Идентифициране на модели от къде? От данните, които се генерират от системите.
Уеб майнинг : Процесът на извършване на извличане на данни в мрежата се нарича Web mining. Извличане на уеб документите и откриване на моделите от тях.
Пример: Техники, прилагани за прогнозен анализ. (Прогноза за времето въз основа на идентифициране на моделите от данните от историята)
Позволява ни да разберем подробно в тази публикация основната разлика между извличането на данни и извличането на уеб.
аналогия
Златото се произвежда чрез процеса, наречен добив на злато. Добива се и се рафинира от рудата. Крайният резултат от добива на злато е благородният метал. По същия начин,
за да получите ключова информация (стойност, която си заслужава) от суров източник, се прилага техника за извличане на данни. Тук моделът, открит от суровия източник на данни, се счита за ценен за анализатора на данни / учени с данни, за да се пристъпи към вземането на решения, които влияят върху бизнес стойността.
Извличане на данни
Казано по-ясно, извличането на данни е концепция за знания за минно дело от различни набори от данни. Получените знания се използват по-нататък за даване на прогнози или препоръки. Данните, които ще бъдат извличани, са налични в хранилището на данни или други външни системи. Данните могат да бъдат достъпни на различни таблици с различните им поведенчески или атрибути. За да се идентифицира моделът, трябва да се идентифицира връзката между множество набори данни.
Стъпки в извличането на данни
Тъй като извличането на данни е абстрактно, ето и списъкът с включените стъпки,
- Подготовка на данни
- Откриване на модел
- Изграждане на модели за прогнозиране / препоръчване (да спомена няколко случая)
- Обобщаване на стойността на модела
Уеб майнинг
Уеб майнингът е абстракт, тъй като има три различни вида техники на минно дело.
- Извличане на уеб съдържание
- Извличане на уеб структура
- Извличане на уеб приложения
Уеб класове за минно събиране на информация 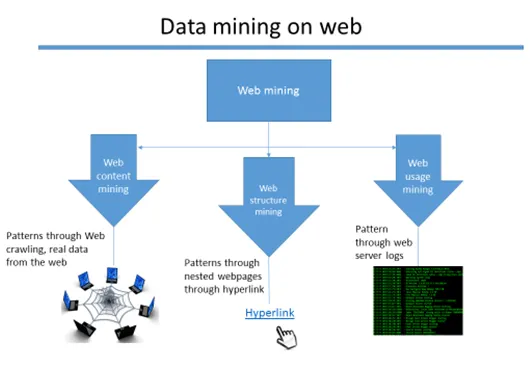
Извличане на уеб съдържание
Данните от уеб страниците се извличат, за да се открият различни модели, които дават значителна представа. Има много техники за извличане на данни като уеб скрепинг (например - scrapy и Octoparse са добре познатите инструменти, които изпълняват процеса на извличане на уеб съдържание.
Един от най-добрите примери - за да се проведе събитие или някоя програма, първо организацията анализира местоположенията (кое местоположение е най-подходящо за провеждане на програмата, така че да има пълно присъствие). За да се извършат тези анализи, човек трябва да събере специфична за местоположението информация за града, държавата и колко далеч се намира събитието от поканения. Всякакви специфични за местоположението данни могат да бъдат извлечени от интернет. Именно там влиза в картината извличането на уеб съдържание.
Извличане на уеб структура
Данните от хипервръзките, които водят до различни страници, се събират и подготвят, за да се открие модел. За да видите публичния профил на човек от блог или друга уеб страница, има шансове той да вгради връзките си в социалните медии. И така, данните се извличат не само от един източник, но и от вложени страници чрез хипервръзките, свързани с всяка страница. Има различни алгоритми за това. (Пример: PageRank алгоритъм)
Извличане на уеб приложения:
Когато е хоствано уеб приложение, има много регистрационни файлове на уеб сървъри, които се генерират относно потребителската уеб активност на приложението. Тези регистрационни файлове се считат за необработени данни в замяна, извличат се значими данни и се идентифицират модели.
Например, за всеки бизнес с електронна търговия, когато те искат да увеличат обхвата на бизнеса или добавят подобрение за по-добро преживяване на клиентите, уеб активността на потребителя чрез регистрационните файлове на приложенията се следи и извличането на данни се прилага към него.
Извличането на уеб и извличането на данни са повече или по-малко подобни техники, но уеб-майнингът е свързан с анализ в мрежата. Извличането на данни не е ограничено до мрежата. Това е традиционен процес, който се провежда за всякаква анализа на данни.
Говорейки за данните от мрежата, има различни данни, които могат да бъдат наблюдавани. Те могат да бъдат структурирани данни (данните от базата данни се изтеглят чрез API, ако се пуснат за обществено ползване). Полуструктурирани данни - всяка уеб свързаност или дори сървърни регистрационни файлове. Или дори неструктурирани данни като изображения и т.н. (ако се правят анализи на изображения)
Сравнение между главата и извличането на данни (Инфографика)
По-долу са най-добрите 7 сравнения между извличане на данни и уеб майнинг

Основни разлики между Data Mining и Web Mining
По-долу е разликата между извличане на данни и извличане на уеб са следните
Извличането на уеб и извличането на данни са почти сходни, когато става въпрос за идентифициране на моделите. Но къде и каква е разликата в уеб майнинга от извличането на данни. Какви данни и данни се извличат от къде? Това са двата крайни аспекта, които носят разликата между извличането на данни и уеб извличането.
Уеб майнингът попада под извличане на данни, но това е ограничено до свързани с уеб данни и идентифициране на моделите. Извличането на данни е огромна концепция, която включва множество стъпки, като се започне от подготовката на данните до валидирането на крайните резултати, които водят до процеса на вземане на решения за дадена организация.
Таблица за сравняване на данни срещу уеб майнинг таблица
| Основа за сравнение | Извличане на данни | Уеб майнинг |
| понятие | Идентификация на образец от данни, налични във всяка система. | Идентификация на модел от уеб данни. |
| Случаи за приложение / употреба | Прогноза за времето с помощта на исторически доклади за времето | Обхождане на данни Техники HITS / PageRank |
| Кой прави това? | Учени по данни Инженери на данни | Data Data / Анализатори на данни Инженери на данни |
| процес | Извличане на данни -> Откриване на образи -> Разработете характеристиката / разрешете я (Алгоритъм) | Същият процес, но в интернет, използвайки уеб документите |
| Инструменти | Алгоритми за машинно обучение | Scrappy, Ранк на страницата, Apache трупи |
| Колко значимо | Много организации разчитат на резултатите от науката за данни за вземане на решения. | Извличането на данни, свързани с уеб, би повлияло на съществуващия процес за извличане на данни. |
| умения | Техники за почистване на данни, алгоритми за машинно обучение, статистика, вероятност | Знания за ниво на приложение, Инженеринг на данни, статистика, вероятност |
Заключение - Извличане на данни срещу уеб
Всички техники за добив с данните са за откриване на знанията и доколко може да се използва за постигане на по-добър резултат. Организациите, които имат желание да увеличат бизнеса си и да реализират висока печалба, се нуждаят от много решения, които да вземат въз основа на данните, които са до голяма степен достъпни в техните системи, генерирани в умален обем. Не всички данни се считат, че дават знания и прозрения. Кои, защо и какви са основните въпроси, на които учените / анализаторите на данни трябва да мислят, когато се подготвят да идентифицират моделите. В съвсем непрофесионален термин, извличането на данни е като процес на избиване на млякото, за да се направи масло.
Препоръчителен член
Това е ръководство за извличане на данни спрямо уеб майнинг, тяхното значение, сравнение между главата, ключови разлики, таблица на сравнението и заключение. Можете също да разгледате следните статии, за да научите повече -
- Data Mining Vs Statistics - кой е по-добър
- 10 мощни стъпки към ефективно планиране на уеб дизайн
- Извличане на данни срещу машинно обучение - 10 най-доброто нещо, което трябва да знаете
- Най-добрите 3 неща, които трябва да научите за Mining vs Text Mining
- Инструменти и техники, използвани в процеса на обработка на данни