

Разлика между Apache Nifi иApache Spark
До дълго време, когато имаше тежка работа, която трябваше да бъде завършена, хората разчитаха на коне за теглене на тежки товари, поддържане на скорост или нещо друго между тях. Не всички коне обаче бяха годни за всяка задача. Същият е случаят с технологията днес. С навлизането на нови технологии във всеки ден става изключително важно да знаем реалните им приложения. Две такива технологии са Apache Nifi и Apache Spark и ние ще проучим за тях в този пост.
Apache Spark е клъстерна изчислителна рамка с отворен код, която има за цел да предостави интерфейс за програмиране на целия набор от клъстери с неявна толерантност на грешки и паралелизъм на данните. Той използва RDDs (устойчиви разпределени набори от данни) и обработва данните под формата на дискретирани потоци, които допълнително се използват за аналитични цели.
Apache Nifi (което е кратката форма на NiagaraFiles) е друг софтуерен проект, който има за цел да автоматизира потока от данни между софтуерните системи. Дизайнът се основава на модела за програмиране, базиран на потока, който предоставя функции, които включват работа с възможност за клъстери. Това е лесна за използване, надеждна и мощна система за обработка и разпространение на данни. Той поддържа мащабируеми насочени графики за маршрутизиране на данни, системно посредничество и логика на трансформация. Нека обсъдим сравненията и на двете теми.
Сравнение между главата на Apache Nifi срещу Apache Spark (Инфографика)
По-долу е топ 9 сравнението между Apache Nifi срещу Apache Spark
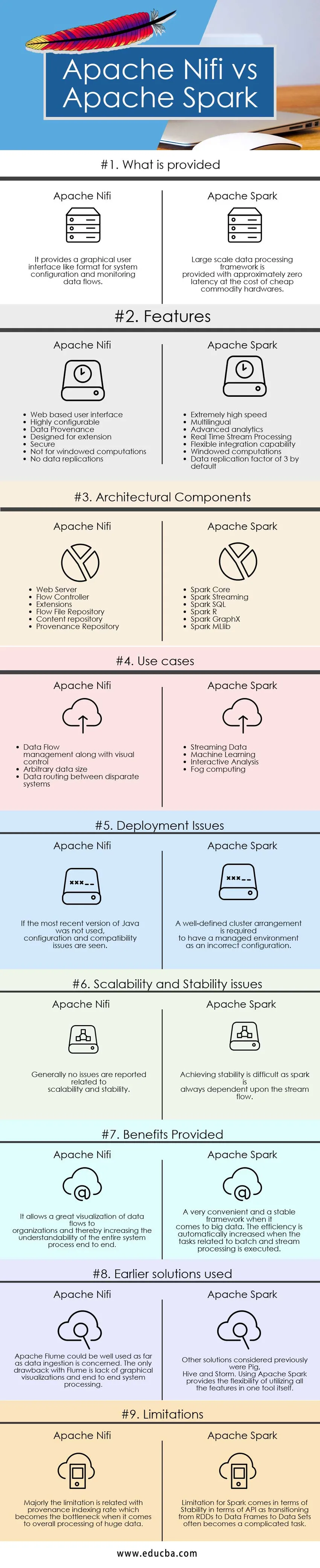
Ключови разлики между Apache Nifi срещу Apache Spark
Разликите между Apache Nifi и Apache Spark са обяснени в точките, представени по-долу:
- Apache Nifi е инструмент за приемане на данни, който се използва за осигуряване на лесна за използване, мощна и надеждна система, така че обработката и разпределението на данни по ресурси става лесна, докато Apache Spark е изключително бърза клъстерна изчислителна технология, която е предназначена за по-бързо изчисляване чрез ефективно използване на интерактивни заявки в управлението на паметта и възможностите за обработка на потоци.
- Apache Nifi работи в самостоятелен режим и в клъстер режим, докато Apache Spark работи добре в локален или самостоятелен режим, Mesos, Прежди и други видове режими на клъстери за големи данни.
- Характеристиките на Apache Nifi включва гарантирана доставка на данни, ефективно буфериране на данни, приоритетна опашка, специфичен QoS, предоставяне на данни, възстановяване на буфер на руло, визуална команда и контрол, шаблони за поток, сигурност, паралелни поточни възможности, докато характеристиките на apache искрата включват светкавично бързо възможност за бърза обработка, многоезичност, изчисления в паметта, ефективно използване на стокови хардуерни системи, разширена анализа, ефективна способност за интеграция.
- Apache Nifi позволява по-добра четимост и цялостно разбиране на системата, като предоставя възможности за визуализация и функции за плъзгане и пускане. Потокът от данни може лесно да се управлява и управлява с помощта на конвенционални техники и процеси, докато в случай на Apache Spark, за да се видят тези видове визуализации, е необходима система за управление на клъстери като Ambari. Apache Spark сам по себе си не предоставя възможности за визуализация и е добър само що се отнася до програмирането. Това е много удобна и стабилна система за обработка на огромни количества данни.
- Ограничението с Apache Nifi е свързано с това, което е неговото предимство. Единствената функция за плъзгане и пускане осигурява ограничение на невъзможността за мащабиране и осигуряване на стабилност, когато става въпрос за интегрирането му с други компоненти и инструменти, докато в случай на Apache Spark основното ограничение идва заедно с използването на обширен стоков хардуер и управлението им се превръща в досадна задача на моменти. Другото отчетено ограничение идва заедно с неговите възможности за стрийминг, свързани с Discretized Stream и Windowed или пакетен поток, където трансформацията на RDD в Data Frame и набори от данни дава причина за нестабилност на моменти.
Apache Nifi vs Apache Spark Таблица за сравнение
| Основа за сравнение | Апач Нифи | Apache Spark |
| Какво се предоставя | Той предоставя графичен потребителски интерфейс като формат за конфигуриране на системата и наблюдение на потоците от данни. | Мащабната рамка за обработка на данни е снабдена с приблизително нулева латентност с цената на евтин стоков хардуер. |
| Характеристика |
|
|
| Архитектурни компоненти |
|
|
| Случаи на употреба |
|
|
| Проблеми с внедряването | Ако не е била използвана най-новата версия на Java, се виждат проблеми с конфигурацията и съвместимостта | За да има управлявана среда като неправилна конфигурация, се изисква добре дефинирано подреждане на клъстер |
| Проблеми с мащабируемостта и стабилността | Като цяло не се съобщава за проблеми, свързани с мащабируемост и стабилност | Постигането на стабилност е трудно, тъй като искрата винаги зависи от потока на потока. |
| Предоставени предимства | Той позволява голяма визуализация на потоците от данни към организациите и по този начин увеличава разбираемостта на целия системен процес от край до край | Много удобна и стабилна рамка, когато става въпрос за големи данни. Ефективността се повишава автоматично, когато се изпълняват задачите, свързани с обработката на партиди и потоци. |
| Използвани по-ранни решения | Apache Flume може да се използва добре по отношение на приемането на данни. Единственият недостатък на Flume е липсата на графични визуализации и системна обработка | Други разгледани решения бяха Pig, Hive и Storm. Използването на Apache Spark осигурява гъвкавост при използване на всички функции в един инструмент. |
| Ограничения | Основното ограничение е свързано със степента на индексиране на произхода, която става тясното място при цялостната обработка на огромни данни | Ограничението за Spark идва от гледна точка на стабилността по отношение на API, тъй като преходът от RDD към Frames на данни към набори от данни често се превръща в сложна задача. |
Заключение - Apache Nifi срещу Apache Spark
В заключение на поста може да се каже, че Apache Spark е тежък боен кон, докато Apache Nifi е пъргав кон. И двете имат своите предимства и ограничения, които да бъдат използвани в съответните области. Трябва да изберете правилния инструмент за вашия бизнес. Следете нашия блог за още статии, свързани с по-новите технологии на големи данни.
Препоръчителен член
Това е ръководство за Apache Nifi срещу Apache Spark, тяхното значение, сравнение между главата, ключови разлики, таблица на сравнението и заключение. Можете също да разгледате следните статии, за да научите повече -
- Apache Hadoop срещу Apache Spark | Топ 10 сравнения, които трябва да знаете!
- Apache Storm срещу Apache Spark - Научете 15 полезни разлики
- 7 важни неща за Apache Spark (Ръководство)
- Най-добрите 15 неща, които трябва да знаете за MapReduce срещу Spark