

Въведение в RDBMS Интервю въпроси и отговор
Така че, ако се подготвяте за интервю за работа в RDBMS. Сигурен съм, че искате да знаете най-често срещаните въпроси за интервю за RDBMS за 2019 г. и отговори, които ще ви помогнат да разрушите RDBMS интервюто с лекота. По-долу е списъкът на най-добрите въпроси за интервю за RDBMS и отговори, които са ви на помощ.
Следователно сме склонни да добавяме най-добрите въпроси за интервю за RDBMS за 2019 г., които се задават най-вече в интервю
1.Какви са различните характеристики на RDBMS?
Отговор:
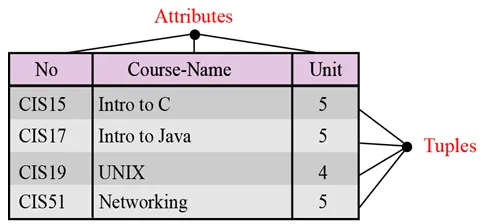
Name. Всяка връзка в релационна база данни трябва да има име, което е уникално сред всички други отношения.
Атрибути. Всяка колона във връзка се нарича атрибут.
Кортежи. Всеки ред във връзка се нарича кортеж. Кортеж определя колекция от стойности на атрибутите.
2.Пояснете ER модел?
Отговор:
Моделът ER е модел на взаимоотношения между субект. ER моделът се основава на реален свят, който е съставен от субекти и обекти на взаимоотношения. Елементите се илюстрират в база данни чрез набор от атрибути.
3. Определете обектно-ориентиран модел?
Отговор:
Обектно-ориентираният модел се основава на колекции от обекти. Обектът побира стойности, които се съхраняват в примерни променливи вътре в обекта. Обектите с идентичен тип стойности и абсолютно същите методи се групират в класове.
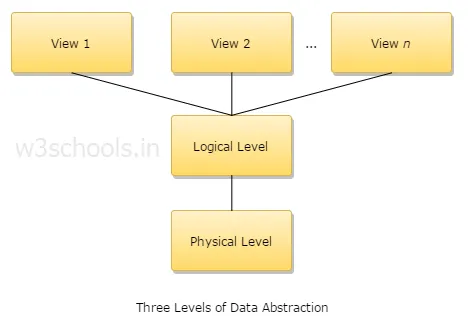
4. Обяснете три нива на извличане на данни?
Отговор:
1. Физическо ниво: Това е най-ниското ниво на абстракция и описва как се съхраняват данните.
2. Логическо ниво: Следващото ниво на абстракция е логично, то описва какъв тип данни се съхраняват в база данни и каква е връзката между тези данни.
3. Ниво на изглед: най-високото ниво на абстракция и описва единствената цяла база данни.
 https://www.w3schools.in/dbms/data-schemas/
https://www.w3schools.in/dbms/data-schemas/
5. Какви са 12-те правила на Codd за релационна база данни?
Отговор:
12-те правила на Код са набор от тринадесет правила (номерирани нула до дванадесет), предложени от Едгар Ф. Код.
Правила на Codd: -
Правило 0: Системата трябва да се квалифицира като релационна, като база данни, а също и като система за управление.
Правило 1: Правилото за информация: Всяка информация в базата данни трябва да бъде представена еднозначно, главно стойности на имената в позиции на колони в различен ред на таблица.
Правило 2: Правилото за гарантиран достъп: Всички данни трябва да бъдат непрекъснати. Той казва, че всяка скаларна стойност в базата данни трябва да бъде правилно / логично адресируема.
Правило 3: Систематично третиране на нулеви стойности: СУБД трябва да позволи на всеки кортеж да остане нулев.
Правило 4: Активен онлайн каталог (структура на базата данни), базиран на релационния модел: Системата трябва да поддържа онлайн, релационна и т.н. структура, която е ингресивна за разрешените потребители с помощта на техните редовни заявки.
Правило 5: Под-език за изчерпателни данни: Системата трябва да подпомага минимум един език на релацията, който:
1.Има линеен синтаксис
2.Който може да се използва както интерактивно, така и в рамките на приложни програми,
3. Поддържа операции за дефиниране на данни (DDL), операции за манипулиране на данни (DML), ограничения на сигурността и целостта и операции за управление на транзакции (стартиране, ангажиране и връщане назад).
Правило 6: Правилото за актуализиране на изгледа: Всички изгледи, които теоретично се подобряват, трябва да бъдат надграждани от системата.
Правило 7: Вмъкване, актуализиране и изтриване на високо ниво: Системата трябва да поддържа оператори за вмъкване, актуализиране и изтриване.
Правило 8: Физическа независимост на данните: Промяната на физическото ниво (как се съхраняват данните, като се използват масиви или свързани списъци и т.н.) не трябва да изисква модификация на приложение.
Правило 9: Независимост на логическите данни: Промяна на логическото ниво (таблици, колони, редове и т.н.) не трябва да изисква модификация на приложение.
Правило 10: Независимост на целостта: Ограниченията на целостта трябва да се идентифицират индивидуално от приложните програми и да се съхраняват в каталога.
Правило 11: Независимост на разпространението : Разпределението на части от база данни на различни места не трябва да бъде видимо за потребителите на базата данни.
Правило 12: Правилото за неподдържане: Ако системата предоставя интерфейс на ниско ниво (т.е. записи), този интерфейс не може да се използва за подриване на системата.
6.Какво е нормализирането? и какво обяснява различните форми на нормализиране.
Отговор:
Нормализирането на базата данни е процес на организиране на данни, за да се сведе до минимум излишъкът на данни. Което от своя страна гарантира съгласуваност на данните. Има много проблеми, свързани с излишъка на данни като загуба на дисково пространство, несъответствие на данни, заявки за DML (Data Manipulation Language) стават бавни. Има различни форми за нормализиране: - 1NF, 2NF, 3NF, BCNF, 4NF, 5NF, ONF, DKNF.
1. 1NF: - Данните във всяка колона трябва да са атомно число, множество стойности, разделени със запетая. Таблицата не съдържа повтарящи се групи от колони. Идентифицирайте всеки запис уникално с помощта на първичния ключ.
2. 2NF: - Таблицата трябва да съответства на всички условия на 1NF и да премества излишните данни в отделна таблица. Освен това създава връзка между тези таблици, използвайки чужди ключове.
3. 3NF: - за 3NF таблица трябва да отговаря на всички условия на 1NF и 2NF. 3NF не съдържа атрибути, които са частично зависими от първичния ключ.
7.Определете първичен ключ, чужд ключ, кандидат-ключ, супер ключ?
Отговор:
Първичен ключ: първичен ключ е ключът, който не позволява дублиращи се стойности и нулеви стойности. Първичен ключ може да бъде определен на ниво колона или ниво на таблица. Разрешен е само един първичен ключ на таблица.
Външен ключ: чужд ключ позволява стойностите, присъстващи само в реферираната колона. Той позволява дублиращи се или нулеви стойности. Може да се определи като ниво на колона или ниво на таблица. Той може да се позовава на колона от уникален / първичен ключ.
Ключ на кандидата: Ключът на кандидата е минимален супер ключ, няма подходяща подгрупа от атрибути на ключови кандидати може да бъде супер ключ.
Супер ключ: Супер ключ е набор от атрибути на схема на отношение, от които всички атрибути на схемата са частично зависими. Няма два реда да имат една и съща стойност на атрибути на супер ключове.
8.Какво е различен тип индекси?
Отговор:
Индексите са: -
Клъстериран индекс: - Това е индексът, при който данните се съхраняват физически в диска. Следователно, само един клъстериран индекс може да бъде създаден в таблица на база данни.
Некластериран индекс: - Той не определя физическите данни, но дефинира логическо подреждане. Обикновено за тази цел се създават B-Tree или B + дърво.
9. Какви са предимствата на RDBMS?
Отговор:
• Контрол на съкращението.
• Целостта може да бъде наложена.
• Несъответствието може да се избегне.
• Данните могат да се споделят.
• Стандартът може да бъде приложен.
10.Имете някои подсистеми на RDBMS?
Отговор:
Вход-изход, Защита, Езикова обработка, Управление на съхранението, регистриране и възстановяване, Контрол на разпространението, Контрол на транзакциите, Управление на паметта.
11.Какво е мениджър на буфери?
Отговор:
Buffer Manager успява да събере данни от дисково съхранение в основната памет и да реши какви данни да бъдат в кеш паметта за по-бърза обработка.
Препоръчителен член
Това е ръководство за Списък на въпроси за интервю за RDBMS и отговори, така че кандидатът да може лесно да разруши тези въпроси за интервю за RDBMS. Можете също да разгледате следните статии, за да научите повече -
- Най-важни въпроси за интервю за анализ на данни
- 13 невероятни въпроси за тестване на база данни и отговори
- Топ 10 въпроси за интервю за дизайн и отговор
- 5 полезни въпроса и отговор за интервю за SSIS