
Преглед на алгоритмите на невронната мрежа
- Нека първо да разберем какво означава Невронна мрежа? Невронните мрежи са вдъхновени от биологичните невронни мрежи в мозъка или можем да кажем нервната система. Това породи много вълнение и проучванията все още продължават по този подмножество на машинно обучение в индустрията.
- Основната изчислителна единица на невронната мрежа е неврон или възел. Той получава стойности от други неврони и изчислява изхода. Всеки възел / неврон е свързан с теглото (w). Това тегло се дава според относителното значение на този конкретен неврон или възел.
- Така че, ако вземем f като функция на възела, тогава функцията на възела f ще осигури изход, както е показано по-долу: -
Изход на неврон (Y) = f (w1.X1 + w2.X2 + b)
- Където w1 и w2 са тегло, X1 и X2 са числени входове, докато b е отклонение.
- Горната функция f е нелинейна функция, наричана още функция за активиране. Основната му цел е да въведе нелинейност, тъй като почти всички данни в реалния свят са нелинейни и искаме невроните да се научат на тези представи.
Различни алгоритми на невронната мрежа
Нека сега разгледаме четири различни алгоритми на невронната мрежа.
1. Градиентно спускане
Това е един от най-популярните алгоритми за оптимизация в областта на машинното обучение. Използва се по време на обучение на модел за машинно обучение. С прости думи, основно се използва за намиране на стойности на коефициентите, които просто намаляват функцията на разходите колкото е възможно повече. Първо от всичко, ние започваме с дефиниране на някои стойности на параметрите и след това с помощта на смятане започваме итеративно да коригираме стойностите, така че загубената функция се намалява.
Сега, нека да стигнем до частта какво е градиент ?. Така че градиентът означава, че изходът на всяка функция ще се промени, ако намалим входа с малко или с други думи, можем да го наречем до наклона. Ако наклонът е стръмен, моделът ще се научи по-бързо по същия начин моделът спира да се учи, когато наклонът е нула. Това е така, защото това е алгоритъм за минимизиране, който минимизира даден алгоритъм.
По-долу формулата за намиране на следващата позиция е показана в случай на наклон на наклон.
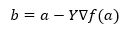
Където b е следващата позиция
a е текуща позиция, гама е функция на изчакване.
Както виждате спускането по градиент е много звукова техника, но има много области, където градиентното спускане не работи правилно. По-долу са предоставени някои от тях:
- Ако алгоритъмът не е изпълнен правилно, тогава може да срещнем нещо като проблема с изчезващия градиент. Те се появяват, когато градиентът е твърде малък или твърде голям.
- Проблемите идват, когато подреждането на данни създава проблем с не-изпъкнала оптимизация. Градиентът приличен работи само с проблеми, които са изпъкнало оптимизиран проблем.
- Един от много важните фактори, които трябва да търсите, докато прилагате този алгоритъм, са ресурсите. Ако имаме по-малко памет, зададена за приложението, трябва да избягваме алгоритъм за спускане по градиент.
2. Метод на Нютон
Това е алгоритъм за оптимизация от втори ред. Нарича се втори ред, защото използва матрицата на Хесия. И така, матрицата на Хесия не е нищо друго освен квадратна матрица от частични производни от втори ред на скаларно оценена функция. В алгоритъма за оптимизиране на метода на Нютон, тя се прилага към първата производна на двойна диференцируема функция f, така че да може да намери корените / стационарни точки. Сега да преминем към стъпките, изисквани от метода на Нютон за оптимизация.
Той първо оценява индекса на загубите. След това проверява дали критериите за спиране са верни или неверни. Ако е невярно, след това изчислява посоката на трениране на Нютон и скоростта на тренировка и след това подобрява параметрите или теглата на неврона и отново същия цикъл продължава. Така че, сега можете да кажете, че е необходимо по-малко стъпки в сравнение с градиентното спускане, за да получите минималния стойност на функцията. Въпреки че отнема по-малко стъпки в сравнение с алгоритъма за градиентно спускане, той все още не се използва широко, тъй като точното изчисление на хесиан и обратната му страна е изчислително много скъпо.
3. Конюгат градиент
Това е метод, който може да се разглежда като нещо между градиентното спускане и метода на Нютон. Основната разлика е, че ускорява бавното сближаване, което обикновено свързваме с градиентно спускане. Друг важен факт е, че може да се използва както за линейни, така и за нелинейни системи и това е итеративен алгоритъм.
Той е разработен от Магнус Хестенес и Едуард Стифел. Както вече беше споменато по-горе, че той произвежда по-бърза конвергенция, отколкото градиентно спускане, Причината, която е в състояние да направи, е, че в алгоритъма Conjugate Gradient търсенето се извършва заедно с посочените посоки, поради което се сближава по-бързо от алгоритмите за спускане по градиент. Важен момент, който трябва да се отбележи, е, че γ се нарича конюгат параметър.
Посоката на тренировката периодично се нулира до отрицателния наклон. Този метод е по-ефективен от градиентно спускане при трениране на невронната мрежа, тъй като не изисква матрицата на Хесия, която увеличава изчислителното натоварване и също така се сближава по-бързо от градиентното спускане. Подходящо е да се използва в големи невронни мрежи.
4. Метод Квази-Нютон
Това е алтернативен подход към метода на Нютон, тъй като сега сме наясно, че методът на Нютон е изчислително скъп. Този метод решава тези недостатъци до такава степен, че вместо да се изчисли матрицата на Хесия и след това да се изчисли директно обратната, този метод изгражда приближение към обратната Хесиян при всяка итерация на този алгоритъм.
Сега това приближение се изчислява, като се използва информацията от първата производна на функцията загуба. Така че, можем да кажем, че вероятно е най-подходящият метод за работа с големи мрежи, тъй като спестява време за изчисление и също така е много по-бърз от спускането на градиента или метода на конюгиращ градиент.
заключение
Преди да приключим с тази статия, Нека сравним изчислителната скорост и паметта за гореспоменатите алгоритми. Според изискванията на паметта градиентното спускане изисква най-малко памет, а освен това е и най-бавното. Напротив, методът на Нютон изисква повече изчислителна мощност. Затова, като вземем предвид всичко това, методът на Квази-Нютон е най-подходящ.
Препоръчителни статии
Това е ръководство за алгоритмите на невронната мрежа. Тук също обсъждаме прегледа на алгоритма на невронната мрежа заедно с четири различни алгоритми съответно. Можете да разгледате и другите ни предложени статии, за да научите повече -
- Машинно обучение срещу невронна мрежа
- Рамки за машинно обучение
- Невронни мрежи срещу дълбоко обучение
- K- означава алгоритъм за клъстериране
- Ръководство за класификация на невронната мрежа