

Разлика между Apache Hive и Apache HBase -
Историята на Apache Hive започва през 2007 г., когато не Java програмист трябва да се бори, докато използва Hadoop MapReduce. Изследователи и разработчици прогнозираха, че утре е ера на Big Data. Вече се трупаха различни формати на данни като структурирани, полуструктурирани и неструктурирани. Дори Facebook се бореше с по-голямото количество обработка на данни. Изследователи от Facebook представиха Apache Hive за обработка на данни на Hadoop Cluster. Facebook беше първата компания, която излезе с Apache Hive.
Историята на Apache HBase започва през 2006 г., когато базираният в Сан Франциско старт Powerset се опитва да изгради машина за търсене на естествен език за мрежата. HBase е внедряване на Bigtable на Google. Разбрахме ли някога, защо имаше нужда да измислим още една архитектура за съхранение? Системата за управление на релационните бази данни съществува от началото на 70-те години. Има много случаи на използване, за които релационните бази данни имат смисъл, но за някои специфични проблеми релационният модел не се вписва много добре.
Нека обясня за Apache Hive и Apache HBase по-подробно.
Разлики между Apache Hive и Apache HBase
Apache Hive е проект с отворен код Apache, създаден на върха на Hadoop за запитвания, обобщаване и анализиране на големи масиви от данни, използвайки SQL-подобен интерфейс. Apache Hive осигурява SQL-подобен език, наречен HiveQL, който прозрачно преобразува заявки в MapReduce за изпълнение на големи набори от данни, съхранявани в разпределената файлова система Hadoop (HDFS). Apache Hive е компонент на клъстер Hadoop, който обикновено се разполага от анализатори на данни. Кошерът Apache се използва за пакетна обработка на големи ETL задачи. Apache Hive също поддържа пакетни SQL заявки на много големи набори от данни. Apache Hive увеличава гъвкавостта на дизайна на схемата, а също и сериализация на данни и десериализация на данните. Apache Hive не поддържа онлайн обработка на транзакции (OLTP), тъй като кошерът не поддържа заявки в реално време и актуализации на ниво ред.
Apache HBase е база данни с отворен код NoSQL, която осигурява достъп в реално време за четене и запис на големи набори от данни. NoSQL е нерелационна база данни. Apache HBase е разпределена към колона база данни, която работи над Hadoop разпределена файлова система (HDFS). Така че HBase носи ползи от NoSQL на Hadoop. Apache HBase осигурява възможности за произволен достъп на данни, присъстващи в HDFS. Той използва толерантността за отказ, осигурена от HDFS. Потребителят може да съхранява данните в HDFS директно или чрез HBase.
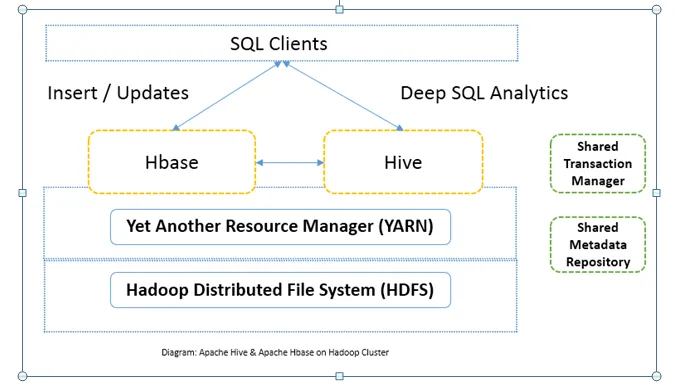
Сравнение между главата на Apache Hive срещу Apache HBase (Инфографика)
По-долу е горната 12 разлика между Apache Hive и Apache HBase

Основни разлики - Apache Hive срещу Apache HBase
По-долу са списъците с точки, опишете основните разлики между Apache Hive и Apache HBase:
- Apache HBase е база данни, докато Apache Hive е двигател на база данни.
- Apache Hive се използва главно за пакетна обработка (OLAP), докато Apache HBase се използва главно за транзакционна обработка (OLTP).
- Apache Hive изпълнява повечето от SQL заявките, докато Apache HBase не позволява директно SQL заявки.
- Apache Hive не поддържа операции на ниво запис като актуализация, вмъкване и изтриване, докато Apache HBase поддържа операции на ниво запис като актуализация, вмъкване и изтриване.
- Apache Hive работи над MapReduce, докато Apache HBase работи над Hadoop разпределена файлова система (HDFS).
Apache Hive пита файловете, като определя виртуална таблица и изпълнява HQL заявки отгоре. Това е процес, при който файловете са практически свързани с таблица като структура и потребителят може да изпълнява Hive Query Language (HQL) и тези заявки се преобразуват в MapReduce Job от Hive. Потребителят не трябва да пише задача MapReduce, HQL заявките се преобразуват вътре в jar файлове и тези jar файлове ще бъдат реализирани на набори от данни.
Докато сте в Apache HBase, таблиците са разделени на региони и се обслужват от регионалните сървъри. Други региони се разделят вертикално от семейства на колони в магазини, а магазините се записват като файлове в HDFS.
Кога да използвате Apache Hive:
- Изисквания за съхранение на данни
- Аналитични заявки
- Анализ на данни, които са запознати със SQL
Кога да използвате Apache HBase:
- Бърза и интерактивна обработка на данни
- Заявки в реално време
- Бързо търсене
- Обработка от страна на сървъра
- Случайно достъп за четене / запис до големи данни
- Мащабируемост на приложението
Apache Hive може да се използва за изчисляване на тенденции и регистри на уебсайта за електронна търговия за определена продължителност, регион или часова зона. Може да се използва за обработка на партидни заявки върху исторически данни, докато Apache HBase може да се използва от Facebook или LinkedIn за анализи и съобщения в реално време. Може да се използва и за броене на харесвания.
Apache Hive vs Apache HBase Таблица за сравнение
Обсъждам основните артефакти и разграничавам Apache Hive от Apache HBase.
| Apache кошер | Apache HBase | |
| Обработка на данни | Apache кошер се използва за
пакетна обработка т.е. онлайн аналитична обработка (OLAP) | Apache HBase се използва за транзакционна обработка, т.е. онлайн транзакционна обработка (OLTP) |
| Скорост на обработка | Apache Hive има по-висока закъснение поради изпълнението на заданието MapReduce на заден план | Apache HBase работи върху заявки в реално време и много по-бързо от Apache Hive |
| Съвместимост с Hadoop | Apache Hive работи върху MapReduce | Apache HBase работи над HDFS |
| дефиниция | Apache Hive е с отворен код и подобен на SQL, използван за аналитични заявки | Apache HBase е база данни с отворен код NoSQL, използвана за заявки в реално време |
| Споделени метаданни | Данните, създадени в Apache Hive, са автоматично видими за Apache HBase | Данните, създадени в Apache HBase, автоматично се виждат в Apache Hive |
| схема | Apeche кошер поддържа схема за поставяне на данни в таблици | Apache HBase е база данни без схеми. |
| Актуализиране на функция | Функцията за актуализация е сложна в Apache Hive | Потребителят може много лесно да актуализира данните в Apache HBase |
| Операции | Операциите в Apache Hive не протичат в реално време | Операциите в Apache HBase протичат в реално време |
| Типове данни | Apache Hive е предназначен за структурирани и полуструктурирани данни | Apache HBase е за неструктурирани данни. |
| Ниво на последователност | Apache кошер поддържа евентуална последователност | Apache HBase поддържа незабавна консистенция |
| Методи за разделяне | Apache Hive поддържа функции на Sharding | Apache HBase също поддържа функции на Sharding |
| Хранилище за данни | Датата се съхранява в Hive Metastore, дялове и кофи в Apache Hive | Данните се съхраняват в колони и редове на таблици в Apache HBase |
Заключение - Apache Hive срещу Apache HBase
Обикновено Apache Hive срещу Apache HBase се използва заедно в един и същ клъстер. И двете могат да се използват заедно за повишаване на мощността на обработката. Тъй като кошерът подобрява аналитичните страни на HDFS, докато HBase подобрява транзакциите в реално време. Потребителят може да използва Hive като ETL инструмент за партидни вмъквания с данните в HBase и след това да изпълнява заявки, които могат допълнително да се присъединят към данни, присъстващи в таблиците на HBase, с данните, които вече присъстват на HDFS. Данните могат да бъдат прочетени и записани от Apache Hive до HBase и отново. Интерфейсът между Apache Hive и Apache HBase все още е фаза на зреене. Предстоят още много неща. Все пак мога да кажа, че и двете Apache Hive срещу Apache HBase правят клъстерът Hadoop по-здрав и мощен.
Свързани статии:
Това е ръководство за Apache Hive срещу Apache HBase, тяхното значение, сравнение между главата, ключови разлики, таблица за сравнение и заключение. Можете също да разгледате следните статии, за да научите повече -
- Топ 5 големи тенденции на данни
- 5 предизвикателства на Big Data Analytics
- Как да разбиете интервюто за разработчици на Hadoop?
- 5 предизвикателства на Big Data Analytics