
Въведение в архитектурата на кошера
Hive Architecture е изградена върху екосистемата Hadoop. Кошера често има взаимодействия с Hadoop. Apache Hive се справя както със системата от бази данни на домейна SQL, така и с Map-redu. Приложенията за кошери могат да бъдат писани на различни езици като Java, python. Архитектурата на кошера показва как да се пише език на заявките на кошера и как се осъществяват взаимодействията между програмиста с помощта на интерфейса на командния ред. Езикът на заявките на кошера върши работата по преобразуването на всички задачи на клъстер Hadoop чрез намаляване на карти. Както всички знаехме Hadoop да обработва големи данни в разпределена среда и формира рамка с отворен код. С кошера той е гъвкав за управление и изпълнение на заявката и е добър поддръжник за изпълнение на функции като капсулация, специални заявки. Тази статия предоставя кратко въведение към архитектурата на кошера, която се намира на слоя Hadoop, за да извърши обобщаване в големи данни.
Архитектура на кошера със своите компоненти
Hive играе основна роля в анализа на данни и интеграцията на бизнес разузнаването и поддържа формати на файлове като текстов файл, rc файл. Hive използва разпределена система за обработка и изпълнение на заявки и съхранението в крайна сметка се извършва на диска и накрая се обработва с помощта на рамка за намаляване на картата. Той решава проблема с оптимизацията, намерен при намаляване на карти и кошера, изпълнява пакетни задачи, които са ясно обяснени в работния процес. Тук мета магазина съхранява информация за схемата. Рамка, наречена Apache Tez, е предназначена за изпълнение на заявки в реално време.
Основните компоненти на кошера са дадени по-долу:
- Клиентите на кошера
- Услуги за кошери
- Съхранение на кошера (мета съхранение)
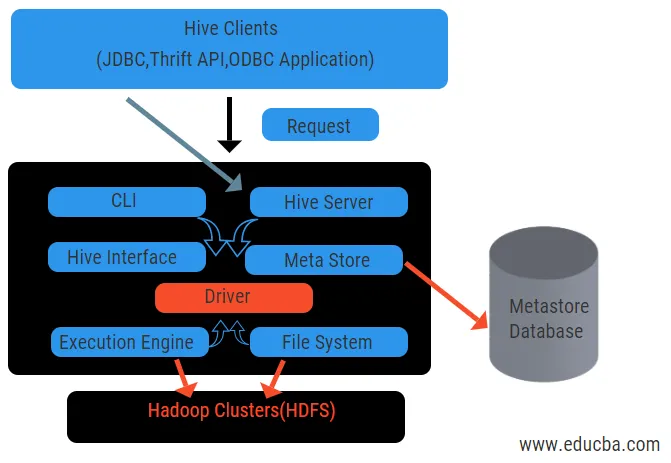
Горната диаграма показва архитектурата на Кошера и неговите компоненти.
Клиенти на кошера:
Те включват приложението Thrift за изпълнение на лесни команди на кошера, които са достъпни за python, ruby, C ++ и драйвери. Тези клиентски приложения ползват за изпълнение на заявки в кошера. Hive има три типа категоризация на клиентите: икономични клиенти, JDBC и ODBC клиенти.
Услуги за кошери:
За обработка на всички заявки кошерът има различни услуги. Всички функции лесно се определят от потребителя в кошера. Нека разгледаме всички тези услуги накратко:
- Интерфейс на командния ред (потребителски интерфейс): Той позволява взаимодействие между потребителя и кошера, черупка по подразбиране. Той предоставя графичен интерфейс за изпълнение на командния ред на кошера и оглед на кошера. Можем да използваме и уеб интерфейси (HWI), за да изпращаме заявките и взаимодействията с уеб браузър.
- Драйвер на кошера: Той получава запитвания от различни източници и клиенти като икономичен сървър и съхранява и извлича на ODBC и JDBC драйвер, които са автоматично свързани към кошера. Този компонент прави семантичен анализ на виждането на таблиците от метастора, който анализира заявка. Драйверът използва помощта на компилатор и изпълнява функции като анализатор, планиране, изпълнение на задания MapReduce и оптимизатор.
- Компилатор: Парсирането и семантичният процес на заявката се извършва от съставителя. Той преобразува заявката в абстрактно синтаксично дърво и отново обратно в DAG за съвместимост. Оптимизаторът от своя страна разделя наличните задачи. Задачата на изпълнителя е да изпълнява задачите и да следи схемата на тръбопровода на задачите.
- Execution Engine: Всички заявки се обработват от двигател за изпълнение. Етапните планове на DAG се изпълняват от двигателя и помагат в управлението на зависимостите между наличните етапи и изпълнението им на правилен компонент.
- Metastore: Той действа като централно хранилище за съхранение на цялата структурирана информация от метаданни, също така е важна аспектна част за кошера, тъй като има информация като таблици и детайли на дялове и съхранение на HDFS файлове. С други думи, ще кажем, че metastore действа като пространство на имена за таблици. Metastore се счита за отделна база данни, която се споделя и от други компоненти. Metastore има две части, наречени сервиз и запаметяване.
Моделът на данните за кошера е структуриран в дялове, кофи, таблици. Всички те могат да бъдат филтрирани, да имат разделителни ключове и да оценят заявката. Заявката на кошера работи на рамката на Hadoop, а не на традиционната база данни. Hive сървърът е интерфейс между отдалечени клиентски заявки към кошера. Двигателят за изпълнение е напълно вграден в кошерен сървър. Можете да намерите приложение на кошера при машинно обучение, бизнес разузнаване в процеса на откриване.
Работен поток на кошера:
Кошера работи в два типа режими: интерактивен и неинтерактивен. Бившият режим позволява на всички команди на кошера да преминават директно към кошера на кошера, докато по-късният тип изпълнява код в конзолен режим. Данните са разделени на дялове, които допълнително се разделят на кофи. Плановете за изпълнение се основават на агрегиране и наклоняване на данни. Допълнително предимство на използването на кошер е лесното обработване на голям мащаб на информация и разполага с повече потребителски интерфейси.
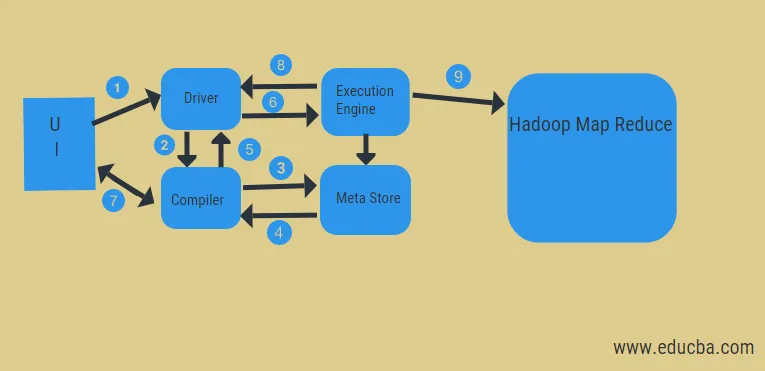
От горната диаграма можем да видим поток от данни в кошера със системата Hadoop.
Стъпките включват:
- изпълнете заявката от потребителския интерфейс
- вземете план от етапите на DAG на задачите на водача
- получете заявка за метаданни от мета магазина
- изпрати метаданни от компилатора
- изпращане на плана обратно на водача
- Изпълнете план в двигателя за изпълнение
- извличане на резултати за съответната потребителска заявка
- изпращане на резултати двупосочно
- изпълнение на обработка на двигателя в HDFS с намаляване на картата и извличане на резултати от възлите на данни, създадени от инструмента за проследяване на задачи. той действа като съединител между Hive и Hadoop.
Задачата на двигателя за изпълнение е да комуникира с възли, за да получи информацията, съхранявана в таблицата. Тук SQL операции като create, drop, alter се извършват за достъп до таблицата.
Заключение:
Преминахме през архитектурата на Hive и техния работен поток, кошерът основно изпълнява петабайтово количество данни и следователно това е пакет за съхранение на данни в платформата Hadoop. Тъй като кошерът е добър избор за боравене с голям обем данни, той помага при подготовката на данни с ръководството за SQL интерфейс за решаване на проблемите с MapReduce. Apache кошер е ETL инструмент за обработка на структурирани данни. Познаването на работата на архитектурата на кошера помага на корпоративните хора да разберат принципа на работа на кошера и има добър старт с програмирането на кошера.
Препоръчани статии:
Това е ръководство за архитектурата на кошера. Тук обсъждаме архитектурата на кошера, различните компоненти и работния процес на кошера. можете също да разгледате следните статии, за да научите повече-
- Hadoop Архитектура
- Използва се за Ruby
- Какво е C ++
- Какво е MySQL база данни
- Поръчка на кошера от