

Въведение в искровите команди
Apache Spark е рамка, изградена върху Hadoop за бързи изчисления. Той разширява концепцията на MapReduce в сценария, базиран на клъстери, за да изпълнява ефективно задачата. Spark Command е написан на Scala.
Hadoop може да се използва от Spark по следните начини (вижте по-долу):
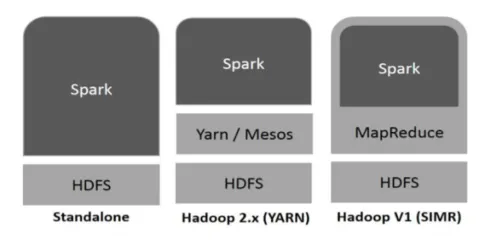
Фиг. 1
https://www.tutorialspoint.com/
- Автономно: Искри директно разположени на върха на Hadoop. Искровите задачи работят паралелно на Hadoop и Spark.
- Hadoop ПРЪЖДА: Искрицата работи на Прежда, без да е необходима предварителна инсталация.
- Искри в MapReduce (SIMR): Искри в MapReduce се използва за стартиране на искра задание, в допълнение към самостоятелно внедряване. Със SIMR човек може да стартира Spark и може да използва неговата обвивка без административен достъп.
Компоненти на Spark:
- Apache Spark Core
- Spark SQL
- Искрено стрийминг
- MLib
- GraphX
Устойчивите разпределени набори от данни (RDD) се считат за основната структура данни на Spark команди. RDD е неизменна и само за четене в природата. Всички видове изчисления в искровите команди се извършват чрез трансформации и действия върху RDD.
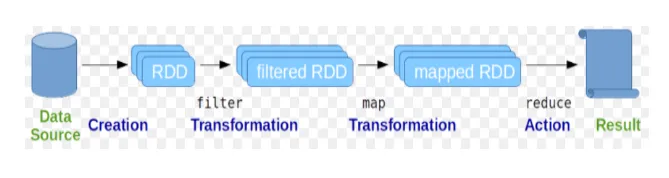
Фиг
Гугъл изображение
Искровата обвивка предоставя среда за взаимодействие на потребителите с нейните функции. Искровите команди имат много различни команди, които могат да се използват за обработка на данни в интерактивната обвивка.
Основни команди за искра
Нека разгледаме някои от основните Spark команди, които са дадени по-долу: -
-
За да стартирате черупката Spark:

Фиг
-
Прочетете файл от локалната система:

Тук "sc" е контекста на искрата. Като се има предвид, че „data.txt“ е в началната директория, той се чете така, в противен случай трябва да посочите пълния път.
-
Създайте RDD чрез паралелизиране

NewData е RDD сега.
-
Преброяване на елементи в RDD

-
Collect
Тази функция връща цялото съдържание на RDD към програмата за драйвери. Това е полезно при отстраняване на грешки в различни стъпки на програмата за писане.
-
Прочетете първите 3 продукта от RDD

-
Запазване на изходните / обработени данни в текстовия файл

Тук папката "изход" е текущият път.
Междинни искрови команди
1. Филтрирайте върху RDD
Нека създадем нов RDD за елементи, които съдържат „да“.

Филтърът за трансформация трябва да бъде извикан в съществуващото RDD за филтриране на думата „да“, което ще създаде ново RDD с новия списък от елементи.
2. Операция на веригата

Тук преобразуването на филтъра и броя на действията действаха заедно. Това се нарича верижна работа.
3. Прочетете първия елемент от RDD

4. Пребройте RDD дяловете
Както знаем, RDD е направен от множество дялове, възниква необходимостта да се брои no. на дялове. Тъй като помага при настройка и отстраняване на проблеми при работа с Spark команди.

По подразбиране минимален номер. pf дял е 2.
5. присъединете се
Тази функция се присъединява към две таблици (елементът на таблицата е по двойка) въз основа на общия ключ. При двойно RDD първият елемент е ключът, а вторият елемент е стойността.
6. Кеширайте файл
Кеширането е техника за оптимизация. Кеширането на RDD означава, че RDD ще остане в паметта и всички бъдещи изчисления ще бъдат извършени на тези RDD в паметта. Спестява времето за четене на диска и подобрява изпълненията. Накратко, намалява времето за достъп до данните.

Данните обаче няма да се кешират, ако стартирате над функция. Това може да се докаже, като посетите уеб страницата:
HTTP: // Localhost: 4040 / съхранение
RDD ще бъде кеширан, след като действието е извършено. Например:

Още една функция, която работи подобно на кеша (), е persist (). Persist дава на потребителите гъвкавост да дадат аргумента, който може да помогне на данните да се кешират в паметта, диска или извън хепа. Персистирането без никакъв аргумент работи същото като кеш ().
Разширени команди за искра
Нека да разгледаме някои от усъвършенстваните Spark команди, които са дадени по-долу: -
-
Излъчване на променлива
Променливата на излъчване помага на програмиста да държи да чете единствената променлива, кеширана на всяка машина в клъстера, вместо да изпраща копие на тази променлива със задачи. Това помага за намаляване на разходите за комуникация.
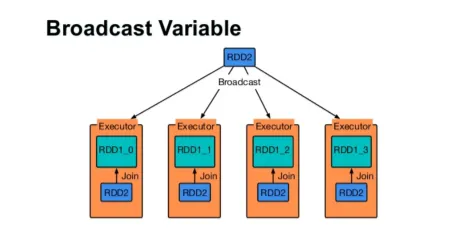
Фигура 4
Гугъл изображение
Накратко, има три основни характеристики на излъчваната променлива:
- неизменен
- Побира се в паметта
- Разпределен по клъстер
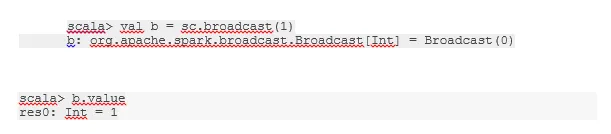
-
Акумулатори
Акумулаторите са променливите, които се добавят към свързаните операции. Има много приложения за акумулатори като броячи, суми и т.н.

Името на акумулатора в кода може да се види и в Spark UI.
-
карта
Функцията Map помага за итерация над всеки ред в RDD. Функцията, използвана в картата, се прилага към всеки елемент в RDD.
Например, в RDD (1, 2, 3, 4, 6), ако приложим „rdd.map (x => x + 2)“, ще получим резултата като (3, 4, 5, 6, 8).
-
Flatmap
Flatmap работи подобно на картата, но картата връща само един елемент, докато flatmap може да върне списъка с елементи. Следователно разделянето на изречения на думи ще се нуждае от плоска карта.
-
сливам
Тази функция помага да се избегне разбъркване на данни. Това се прилага в съществуващия дял, така че да се разместват по-малко данни. По този начин можем да ограничим използването на възли в клъстера.
Съвети и трикове за използване на искра команди
По-долу са различните съвети и трикове на Spark команди: -
- Начинаещите от Spark могат да използват Spark-shell. Тъй като Spark команди са изградени на Scala, така че определено използването на scala искрата е чудесно. Въпреки това, Python искра черупка също е на разположение, така че дори и нещо, което човек може да използва, които са добре запознати с python.
- Spark shell има много възможности за управление на ресурсите на клъстера. По-долу Command може да ви помогне с това:

- В Spark работата с дълги набори от данни е обичайното нещо. Но нещата се объркват, когато се приемат лоши данни. Винаги е добра идея да пуснете лоши редове, като използвате функцията за филтриране на Spark. Добрият набор от вход ще бъде чудесен ход.
- Spark избира добър дял за вашите данни. Но винаги е добра практика да следите дяловете, преди да започнете работата си. Изпробването на различни дялове ще ви помогне при паралелизъм на вашата работа.
Заключение - Искрови команди:
Spark командата е революционен и универсален двигател с големи данни, който може да работи за пакетна обработка, обработка в реално време, кеширане на данни и др. Spark има богат набор от библиотеки за машинно обучение, които могат да позволят на учените по данни и аналитичните организации да изграждат силни, интерактивни и бързи приложения.
Препоръчителни статии
Това е ръководство за Spark команди. Тук сме обсъдили основни, както и усъвършенствани Spark команди и някои непосредствени Spark команди. Можете също да разгледате следната статия, за да научите повече -
- Команди на Adobe Photoshop
- Важни команди VBA
- Команди на Табау
- Чит лист SQL (Команди, безплатни съвети и трикове)
- Видове съединения в Spark SQL (Примери)
- Искрови компоненти | Преглед и топ 6 компоненти