
Разлика между Hadoop и Redshift
Hadoop е рамка с отворен код, разработена от Apache Software Foundation с нейните основни предимства от мащабируемост, надеждност и разпределени изчисления. Обработка на данни, съхранение, достъп, сигурност са няколко типа функции, достъпни в екосистемата Hadoop. HDFS има висока пропускателна способност, което означава, че е в състояние да борави с големи количества данни с възможност за паралелна обработка. Redshift е облачна хостинг уеб услуга, разработена от Amazon Web Services Unit в Amazon.com Inc., извън съществуващите услуги, предоставяни от Amazon. Използва се за проектиране на мащабен склад за данни в облака. Redshift е услуга за съхранение на данни в мащаб на петабайт, която е напълно управлявана и рентабилна за работа на големи набори от данни.
Нека да проучим подробно за Hadoop и Redshift подробно:
Hadoop HDFS има висока способност за устойчивост на откази и е проектиран да работи на хардуерни системи с ниска цена. Hadoop може да се справи с минимален размер на TeraBytes до GigaBytes на файлове в неговата система. HDFS е архитектура master-slave, състояща се от възли с имена и възли за данни, където име на възел съдържа метаданни, а Data Node съдържа реални данни, които трябва да бъдат обработвани или оперирани.
RedShift използва различни техники за зареждане на данни като BI (Business Intelligence) отчитане, аналитични инструменти и извличане на данни. Redshift предлага конзола за създаване и управление на Amazon Redshift клъстери. Основният компонент на Redshift Data Warehouse е клъстер.
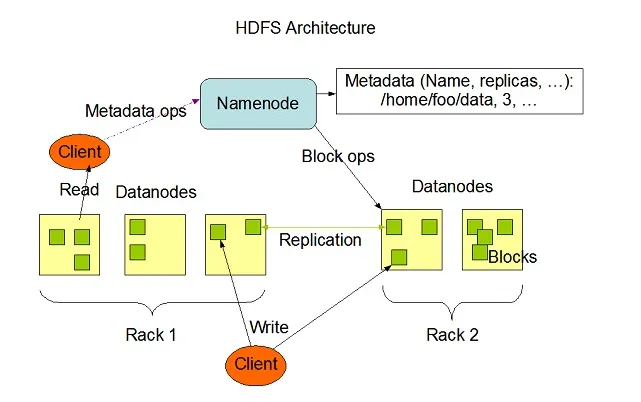
Източник на изображението: Apache.org
RedShift Архитектура:
 Източник на изображението: Amazon.com
Източник на изображението: Amazon.com
Сравнение между главата на Hadoop срещу Redshift (Инфографика):
По-долу е топ 10 сравнението между Hadoop и Redshift е както следва

Ключови разлики между Hadoop срещу Redshift:
По-долу са ключовите разлики между Hadoop срещу Redshift са както следва
1. Архитектурата на Hadoop HDFS (разпределена файлова система на Hadoop) има имена възли и възли за данни, докато Redshift има Leader Node и Compute възли, където Compute възлите ще бъдат разделени като Slices.
2. Hadoop осигурява интерфейс на командния ред за взаимодействие с файловата система, докато RedShift има конзола за управление, за да взаимодейства с услуги за съхранение на Amazon като S3, DynamoDB и т.н.,
3. Операциите с база данни трябва да бъдат конфигурирани от разработчиците. В Redshift автоматизира операциите с базата данни, като анализира плановете за изпълнение.
4.Hadoop има няколко поддръжка на инструменти на трети страни, които да бъдат интегрирани лесно, докато Redshift поддържа само продукти, разработени от Amazon в своя облак.
5. По отношение на архитектурния дизайн на Hadoop, мрежата, съхранението, сигурността и производителността се считат за основни елементи, докато при Redshift тези елементи могат лесно и гъвкаво да се конфигурират с помощта на конзола за управление на облак Amazon.
6.Hadoop е архитектура на файловата система, базирана на Java Application Programming Interfaces (API), докато Redshift се базира на релационния модел за управление на бази данни (RDBMS).
7.Hadoop може да има интеграции с различни доставчици и Redshift няма подкрепа в този случай, когато Amazon е единственият им доставчик. Какво става, ако потребителят е недоволен от услугата? В този случай Hadoop е предимство.
8. Повечето от съществуващите компании все още използват Hadoop, докато новите клиенти избират RedShift.
9. По отношение на производителността Hadoop винаги изостава, а Redshift винаги печели в случай на изпълнение на заявки при големи обеми данни.
10.Hadoop използва модела за програмиране Map Reduce за работа със задачи. Amazon Redshift използва намаляването на еластичната карта на Amazon.
11.Hadoop използва модела за програмиране Map Reduce за работа със задачи. Amazon Redshift използва намаляването на еластичната карта на Amazon.
12.Hadoop е за предпочитане ежедневно да изпълнява пакетни задачи, които стават по-евтини, докато Redshift излиза по-евтино в случай на технология за онлайн аналитична обработка (OLAP), която съществува зад много инструменти на Business Intelligence.
13.Hadoop е 10 пъти по-бавен от Redshift при изпълнение на заявки по подобен начин Hadoop е 10 пъти по-скъп от Redshift, което води до това, че Hadoop е най-малко избран преди Redshift.
14. По отношение на зареждането на данни Hadoop е зад Redshift по отношение на това, ако системата взема часове за зареждане на данни от съхранението в системата за обработка на файлове.
15.Hadoop може да се използва за съхранение на ниски цени, архивиране на данни, езера, съхранение на данни и анализ на данни, докато Redshift попада под възможностите на хранилището на данни, което води до ограничаване на многоцелевата употреба.
16.Hadoop платформа осигурява поддръжка на различни външни доставчици и собствени проекти на Apache като Storm, Spark, Kafka, Solr и т.н., а от другата страна Redshift има ограничена поддръжка за интеграция с единствените си продукти на Amazon
Hadoop vs Redshift сравнителна таблица
| ОСНОВА ЗА
СРАВНЕНИЕ | Hadoop | червено отместване |
| наличност | Рамка с отворен код от Apache Projects | Ценови услуги, предоставяни от Amazon |
| изпълнение | Предоставя се от доставчиците на Hortonworks и Cloudera и т.н., | Разработен и предоставен от Amazon |
| производителност | Работите в Hadoop MapReduce са по-бавни | Redshift се представя по-бързо от Hadoop клъстера |
| скалируемост | Ограничения в мащабируемостта | Лесно се намалява / увеличава според изискванията |
| Ценообразуване | Разходите 200 долара на месец за изпълнение на заявки | Цената зависи от региона на сървъра и по-евтина от Hadoop
Например: $ 20 / месец |
| скорост | По-бързо, но по-бавно в сравнение с Redshift | 10 пъти по-бърз от Hadoop |
| Скорост на запитване | Отнема 1491 секунди, за да стартира 1.2TB данни | 155 секунди, за да стартирате 1.2TB данни |
| Интеграция на данни | Гъвкава с локална файлова система и всяка база данни | Може да зарежда данни само от Amazon S3 или DynamoDB |
| Формат на данните | Поддържат се всички формати на данни | Строг във формати на данни като CSV файлови формати |
| Лесно използване | Сложни и сложни за справяне с административните дейности | Автоматизирана администрация за архивиране и съхранение на данни |
Извод - Hadoop срещу Redshift
Окончателното твърдение за заключение на големия победител в това сравнение е Redshift, който печели по отношение на лекотата на работа, поддръжката и производителността, докато Hadoop липсва по отношение на мащабируемост на производителността и разходите за услуги с единствената полза от лесната интеграция с инструменти на трети страни и продукти. Redshift в последно време се развива с огромен растеж и приемане от много клиенти и клиенти поради високата си достъпност и по-ниските разходи за операции в сравнение с Hadoop го прави все по-популярен. Но досега повечето от съществуващите компании от Fortune 1000 използват платформите Hadoop в своите архитектури за управление на клиентските данни.
В повечето случаи RedShift е бил най-добрият избор за разглеждане за бизнес цели от всеки клиент или клиент, за да се справят с големите и чувствителни данни на всяка финансова институция или публична информация с повече интегритет и сигурност на данните.
Освен това Hadoop има своите предимства, че е проект с отворен код и е бил на разположение в продължение на много години, също така причинява подмяната на съществуващите системи като процес, свързан с разходи. Продуктът трябва да бъде избран най-накрая въз основа на изискването и гъвкавостта, а не на цените или популярността въз основа на движещите се бизнес нужди.
Препоръчителен член:
Това е ръководство за Hadoop срещу Redshift, тяхното значение, сравнение между главата, ключови разлики, таблица на сравнението и заключение. Можете също да разгледате следните статии, за да научите повече -
- Hadoop срещу кошера - открийте най-добрите разлики
- HADOOP срещу RDBMS | Познайте 12-те полезни разлики
- Apache Hadoop срещу Apache Spark | Топ 10 сравнения, които трябва да знаете!
- Big Data vs Data Science - как са различни?
- Ръководство за Hadoop срещу Spark
- Топ 4 доставчици на облачен хостинг с функции