

Какво е Кафка?
За да разберете Kafka, по-добре е да разберете какво е технологията „обработка на потоци“. „Обработката на потока е технология, чрез която потребителят може да запитва непрекъснат поток от данни в микро времеви рамка, за да разбере по-добре основните отговорности.
Сценарий в реално време - представете си, ако сензорът ви за температура изпраща данни, които можете да задавате и да получавате сигнал след получаване на точка на замръзване. Това запитване на данни може да се извърши за микросекунди.
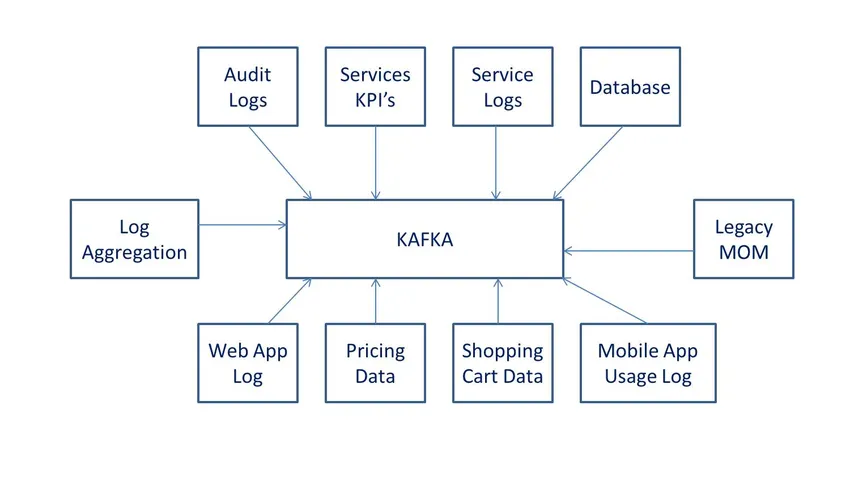
Дефиниции
според Wiki, това е софтуер за обработка на данни с отворен код. Той е разработен от LinkedIn и по-късно дарен на софтуер Apache.
Разбиране на Кафка
Нейният растеж избухва експоненциално. Нека видим някои факти и статистика, за да подчертаем по-добре нашата мисъл. Той се радва на основното предпочитание от повече от една трета от Fortune 500 по целия свят. Тази дистрибуция се споделя от компаниите за туристически бизнес, телекомуникационни гиганти, банки и няколко други. LinkedIn, Microsoft и Netflix обработват съобщения с четири запетая на ден с Kafka (почти равна на 1 000 000 000 000).
Използва се за потоци от данни в реално време, за събиране на големи данни или за анализ в реално време (или и двете). Kafka се използва с микросервизи в паметта за осигуряване на дълготрайност и може да се използва за подаване на събития към CEP (сложни поточни системи за събития) и системи за автоматизация в стил IoT / IFTTT.
Как работи Кафка толкова лесно?
Водени от простотата би бил правилният начин да определите представянето. Лесно е да разберете как Kafka работи с такава лекота от създаването и използването му. Тази повишена производителност в поведението е посветена на неговата стабилност, осигуряването на надеждна трайност, с гъвкавата си вградена способност да публикува или да се абонира или поддържа опашки. Това е много важно, ако трябва да се справите с N - брой клиентски групи, ако трябва да покажете стабилна репликация на пазара, насочена към осигуряване на вашите клиенти последователен подход (т.е. тематичен дял на Kafka). Едно решаващо поведение на Kafka, което я отличава от конкурентите, е нейната съвместимост със системи с потоци от данни - нейният процес и дава възможност на тези системи да агрегират, трансформират и зареждат други магазини за удобство на работа. „Всички гореспоменати факти не биха били възможни, ако Кафка беше бавна“. Изключителното му представяне прави това възможно.
С допълнително допълнение, за да улесним работата с Kafka, трябва да преминем към „OS Level“. Нека да открием как работят нещата за Kafka на ниво OS -
- Разчита на ядра на OS за по-бързото преместване на данните и работи на принципа на нулевото копиране.
- Тя позволява записи на данни да се събират на парчета, които могат да се видят от файловата система (известна още като дневник на темата Kafka) към потребителите.
- Устройството за пакетиране на данни дава ефективно компресиране на данни с намаляване на I / O латентността.
- Той има възможност да мащабира хоризонтално чрез заточване. Той може да раздели лог заглавие в стотици дял на хиляди. Това му позволява лесно да се справя с огромното натоварване.
Какво можеш да направиш с Кафка?
Ако вашата компания играе редовно с огромни набори от данни, имате нужда от Kafka. Има дълъг списък от компании, които го използват.
- LinkedIn използва за проследяване на данни и оперативни показатели.
- Twitter за предоставяне на инфраструктури за обработка на потоци.
Има дълъг списък от компании от Uber до Spotify и Goldman Sachs до Cisco.
Предимства
- Висока пропускателна способност: Лесно може да борави с голям обем данни, когато генерирането на висока скорост е изключително предимство в полза на Kafka. На това приложение липсва огромен хардуер. С капацитета да поддържа пропускане на съобщения с честота от хиляди съобщения в секунда.
- Ниска латентност: Ниска латентност при работа с това поколение съобщения с голям обем.
- Толерантност на отказите: Тази функция е много полезна, има присъща способност да бъде ограничена от възел, вграден в клъстер.
- Издръжлив: той е много издръжлив в работата си и затова много MNC предпочитат да използват Kafka. Говорейки за дълготрайност в операциите, съобщенията не могат да се изгубят в дългосрочен план.
Необходими умения
Няма специално изискване да бъдеш професионалист от Кафка. Но ние подчертахме някои потоци и професионалисти -
- Разработчици, които желаят да направят кариера в Big Data stream и искат да ускорят кариерата си.
- Професионалните тестове имат добър обхват в Kafka по отношение на системите за опашка и съобщения
- Архитекти - тъй като всичко се нуждае от някаква рамка и тази рамка може да се актуализира от време на време. Архитектите с големи данни биха намерили Кафка за добра кариерна инвестиция.
- Ръководителят на проекта е необходим, ако горепосоченият професионалист има за по-добро управление на ресурсите. И така, по-високи длъжности са на разположение и за управленските специалисти в областта на Кафка.
Защо да използвате Kafka?
За целите на проследяването на данни и манипулирането им според нуждите на бизнеса, Kafka е предпочитана по целия свят. Дава възможност за поточно предаване на данни в реално време с анализи в реално време. Той е бърз, мащабируем и издръжлив и е проектиран като толерантност. Има много случаи на използване в мрежата, където можете да видите защо JMS, RabbitMQ и AMQP дори не се считат за работа, тъй като необходимостта е да се работи с голям обем и отзивчивост.
Той има висока пропускателна способност, надеждна настройка с репликационни характеристики, което го прави предпочитан избор за работа върху IoT сензори.
Съвместимостта е друга причина да го използвате и го направи приемлив в целия свят. Може лесно да се конфигурира да работи с приложението по-долу. Тази комбинация е много жизненоважна за много компании за разрастване на бизнеса и оцеляване (тъй като спестява време и пари).
- воденичен улей
- Искрено стрийминг
- HBase
- Искри за поглъщане, обработка и анализ на данни в реално време.
- Използва се за хранене на Hadoop BigData
Обхват
Той се справя страхотно по целия свят. Е, ние не казваме това по-скоро статистика. Нека погледнем -
Статистика за заплатите за професионалисти от Kafka - PayScale
- Софтуерен инженер - 109 825 долара
- Инженер на данни - 109 580 долара
- Разработчици - 81 182 долара
- Старши инженер за данни - 127, 836 долара
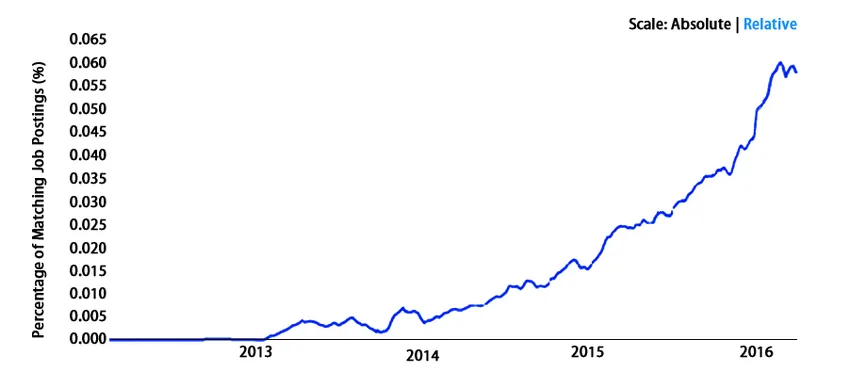
заключение
Понастоящем Kafka се превърна в стандарт фактически, когато става дума за анализи на данни в реално време с най-висока точност за микросекунди. Представихме нашите виждания по отношение на данни и подробности в подкрепа на технологиите на Kafka. Има няколко големи компании, които събират данни ежедневно, като за това им трябват професионалисти, които да използват тези огромни набори от данни. С Кафка може да се гарантира, че ще води кариерата си в анализа на BigData
Препоръчителни статии
Това е ръководство за Какво е Кафка. Тук обсъдихме работата, обхвата, кариерния растеж и предимствата на Kafka. Можете да разгледате и другите ни предложени статии, за да научите повече -
- Какво е Apache?
- Какво е Големи данни и Hadoop?
- Какво е Azure?
- Какво е Big Data Technology?
- Кафка срещу Искри | Топ 5 разлики
- Преглед и най-добрите приложения на Kafka
- Кафка срещу Кинезис | 5 разлики с инфографика