
Въведение в Поасоновата регресия в R
Поасоновата регресия е вид регресия, която е подобна на множествена линейна регресия, с изключение на това, че отговорът или зависимата променлива (Y) е променлива число. Зависимата променлива следва разпределението на Poisson. Предсказателят или независимите променливи могат да имат непрекъснат или категоричен характер. По някакъв начин той е подобен на Logistic Regression, който също има дискретна променлива реакция. Предварителното разбиране на разпределението на Поасон и неговата математическа форма е много важно за използването му за прогнозиране. В R, регресията на Поасон може да бъде реализирана по много ефективен начин. R предлага изчерпателен набор от функционалности за неговото изпълнение.
Реализиране на Поасонова регресия
Сега ще продължим да разберем как се прилага моделът. Следващият раздел дава стъпка по стъпка процедура за същото. За тази демонстрация, ние обмисляме „гала” набор от данни от далечния пакет. Тя се отнася до видовото разнообразие на Галапагоските острови. В набора от данни има общо 7 променливи. Ще използваме регресия на Поасон, за да определим връзка между броя на растителните видове (видове) с други променливи в набора от данни.
1. Първо заредете „далечния“ пакет. В случай, че пакетът не присъства, изтеглете го с помощта на функцията install.packages ().
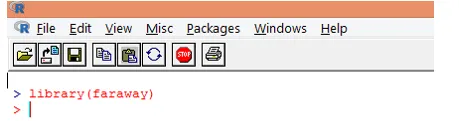
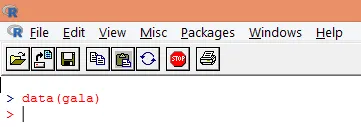
2. След като пакетът е зареден, заредете "гала" набора от данни в R, използвайки функция data (), както е показано по-долу.
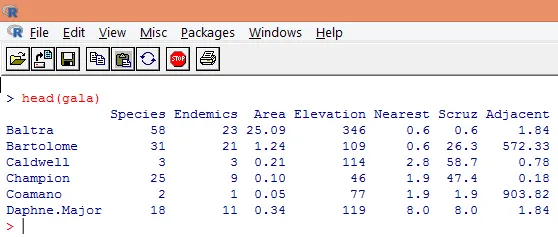
3. Заредените данни трябва да се визуализират, за да се проучи променливата и да се провери дали има несъответствия. Можем да визуализираме или всички данни, или само първите няколко реда от тях, като използваме функцията head (), както е показано на снимката по-долу.
4. За да добием повече представа за набора от данни, можем да използваме помощна функционалност в R, както е посочено по-долу. Той генерира R документацията, както е показано на екрана след следващия екран.


5. Ако изследваме набора от данни, както е споменато в предходните стъпки, тогава можем да открием, че Species е променлива за отговор. Сега ще проучим основно обобщение на променливите на прогнозата.
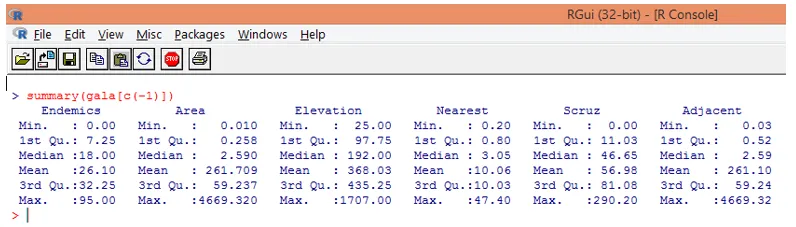
Забележете, както се вижда по-горе, изключихме променливата Видове. Обобщената функция ни дава основна информация. Просто наблюдавайте средните стойности за всяка от тези променливи и можем да открием, че огромна разлика по отношение на диапазона от стойности съществува между първата и втората половина, напр. За средната стойност на променлива средна стойност е 2, 59, но максималната стойност е 4669.320.
6. Сега, когато приключим с основния анализ, ще генерираме хистограма за видове, за да проверим дали променливата следва разпределението на Poisson. Това е илюстрирано по-долу.

Горният код генерира хистограма за променлива Вид, заедно с крива на плътност, наложена върху нея.
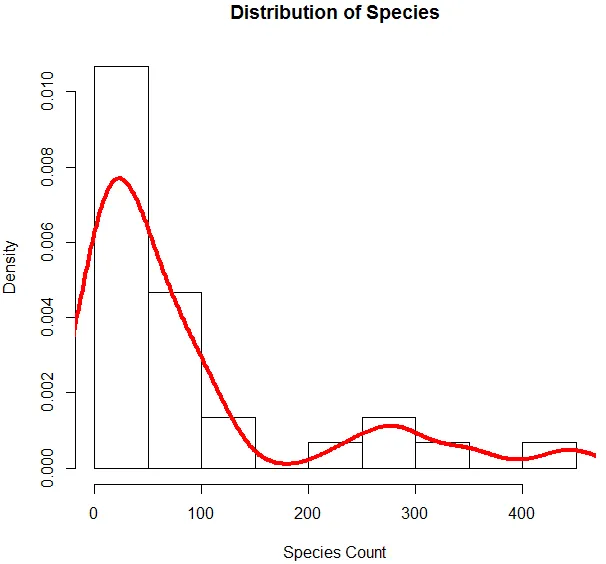
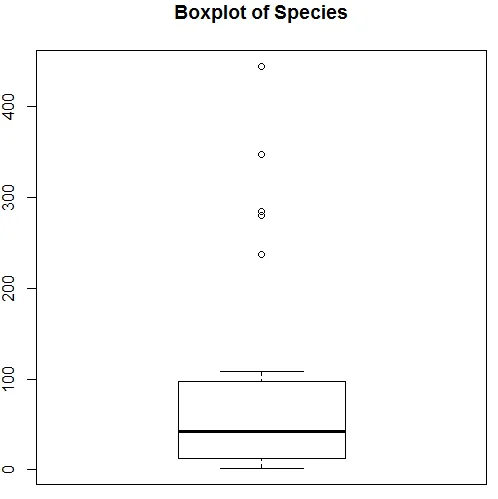
Горната визуализация показва, че видовете следват разпределение на Poisson, тъй като данните са правилно изкривени. Можем да генерираме и боксплот, за да получим повече представа за модела на разпространение, както е показано по-долу.
7. След като приключихме с предварителния анализ, сега ще приложим Поасонова регресия, както е показано по-долу
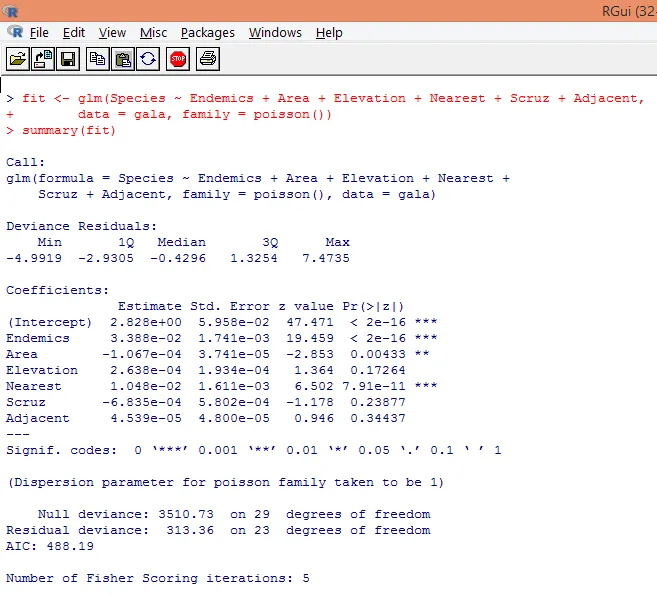
Въз основа на горния анализ установяваме, че променливите Endemics, Area и Най-близки са значителни и само тяхното включване е достатъчно за изграждането на правилния регресионен модел на Poisson.
8. Ще изградим модифициран регресионен модел на Поасон, като отчитаме само три променливи. Ендемики, област и най-близки. Нека видим какви резултати получаваме.
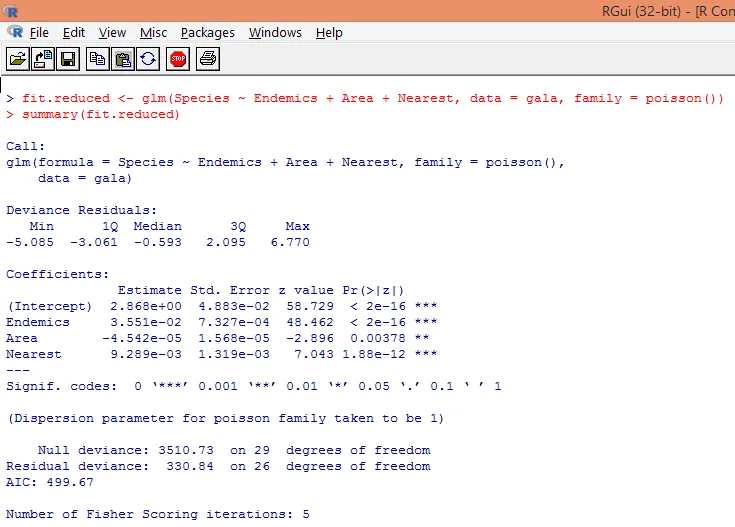
Резултатът произвежда отклонения, регресионни параметри и стандартни грешки. Можем да видим, че всеки от параметрите е значителен на ниво p <0, 05.
9. Следващата стъпка е интерпретация на параметрите на модела. Моделните коефициенти могат да бъдат получени или чрез изследване на коефициентите в горния изход, или чрез използване на coef () функция.
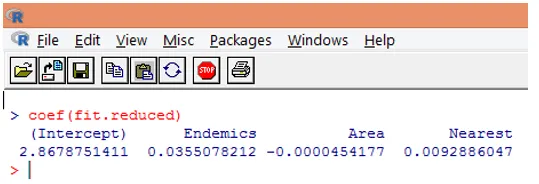
При регресия на Поасон зависимата променлива се моделира като лог на условно средната loge (l). Регресният параметър от 0, 0355 за Endemics показва, че едно единично увеличение на променливата е свързано с увеличение с 0, 04 на средния брой на журнала на видове, като държи другите променливи постоянни. Прехващането е средно регистриран брой видове, когато всеки от предикторите е равен на нула.
10. Въпреки това е много по-лесно да се интерпретират коефициентите на регресия в оригиналната скала на зависимата променлива (брой на видовете, а не лог на броя на видовете). Експоненцията на коефициентите ще позволи лесна интерпретация. Това се прави по следния начин.
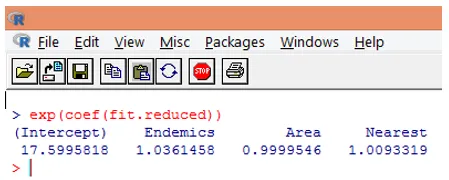
От горните констатации можем да кажем, че едно единично увеличение на площ умножава очаквания брой видове с 0, 9999, а единично увеличение на броя на ендемичните видове, представени от Endemics, умножава броя на видовете с 1, 0361. Най-важният аспект на регресията на Поасон е, че експоненцираните параметри имат мултипликативен, а не адитивен ефект върху променливата на отговора.
11. Използвайки горните стъпки, получихме регресионен модел на Поасон за прогнозиране на броя на растителните видове на Галапагоските острови. Много е важно обаче да се провери за свръхдисперсия. При регресията на Поасон вариацията и средните средства са равни.
Свръхдисперсията възниква, когато наблюдаваната дисперсия на променливата на отговора е по-голяма, отколкото би било предвидено от разпределението на Poisson. Анализът на свръхдисперсия става важен, тъй като е често срещан с данните от броя и може да повлияе негативно на крайните резултати. В R свръхдисперсията може да се анализира с помощта на пакета „qcc“. Анализът е илюстриран по-долу.
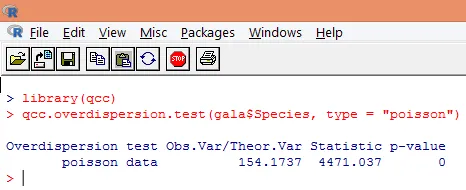
Горният значим тест показва, че р-стойността е по-ниска от 0, 05, което категорично предполага наличието на свръхдисперсия. Ще се опитаме да монтираме модел, използвайки функция glm (), като заменим family = „Poisson“ с family = „quasipoisson“. Това е илюстрирано по-долу.
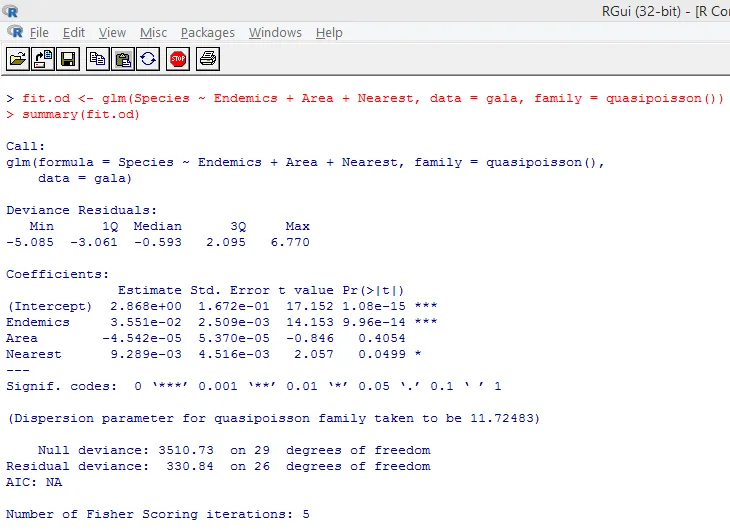
Отблизо изучавайки горния изход, можем да видим, че оценките на параметрите в квази-Поасоновия подход са идентични на тези, произведени от подхода на Поасон, въпреки че стандартните грешки са различни и за двата подхода. Освен това, в този случай, за Area, р-стойността е по-голяма от 0, 05, което се дължи на по-голяма стандартна грешка.
Значение на Поасоновата регресия
- Поасоновата регресия в R е полезна за правилни прогнози на променливата дискрет / брой.
- Помага ни да идентифицираме онези обяснителни променливи, които имат статистически значим ефект върху променливата на отговора.
- Poisson Regression in R е най-подходящ за събития от „рядко“ естество, тъй като те са склонни да следват разпределение на Poisson спрямо обикновени събития, които обикновено следват нормално разпределение.
- Подходящ е за приложение в случаите, когато променливата на отговора е малко цяло число.
- Той има широко приложение, тъй като прогнозирането на дискретни променливи е от решаващо значение в много ситуации. В медицината може да се използва за прогнозиране на въздействието на лекарството върху здравето. Той се използва широко в анализа на оцеляването като смъртта на биологични организми, отказ на механични системи и др.
заключение
Регресията на Poisson се основава на концепцията за разпределение на Poisson. Това е друга категория, принадлежаща към набора от регресионни техники, който комбинира свойствата както на линейни, така и на логистични регресии. Въпреки това, за разлика от логистичната регресия, която генерира само двоичен изход, той се използва за прогнозиране на дискретна променлива.
Препоръчителни статии
Това е ръководство за Поасоновата регресия в Р. Тук обсъждаме въвеждането Прилагане на Поасонова регресия и значението на Поасоновата регресия. Можете също да прегледате и другите ни предложени статии, за да научите повече -
- GLM в R
- Генератор на случайни числа в R
- Регресия формула
- Логистична регресия в R
- Линейна регресия срещу логистична регресия | Топ разлики