
Въведение в обучението за усилване
Укрепването на обучението е вид машинно обучение и следователно е част от изкуствения интелект, когато се прилага към системи, системите изпълняват стъпки и се учат въз основа на резултата от стъпките, за да получат сложна цел, която е зададена за постигане на системата.
Разберете обучението за подсилване
Нека се опитаме да работим с усилването на обучението с помощта на 2 прости случая на използване:
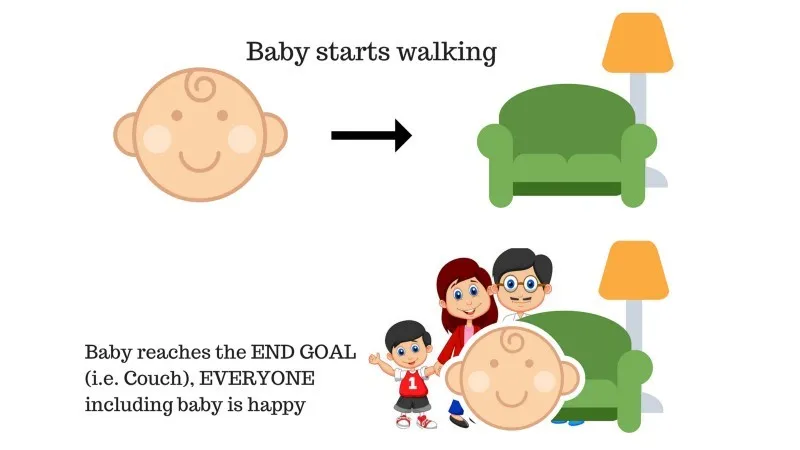
Дело №1
В семейството има бебе и току-що започна да ходи и всички са доста щастливи от това. Един ден родителите се опитват да си поставят цел, нека да достигнем бебето до дивана и да видим дали бебето е в състояние да го направи.
Резултат от случай 1: Бебето успешно стига до дивана и по този начин всички в семейството са много щастливи да видят това. Избраният път сега идва с положителна награда.
Точки: Награда + (+ n) → Положителна награда.
Източник: https://images.app.goo.gl/pGCXJ1N1bzLAer126
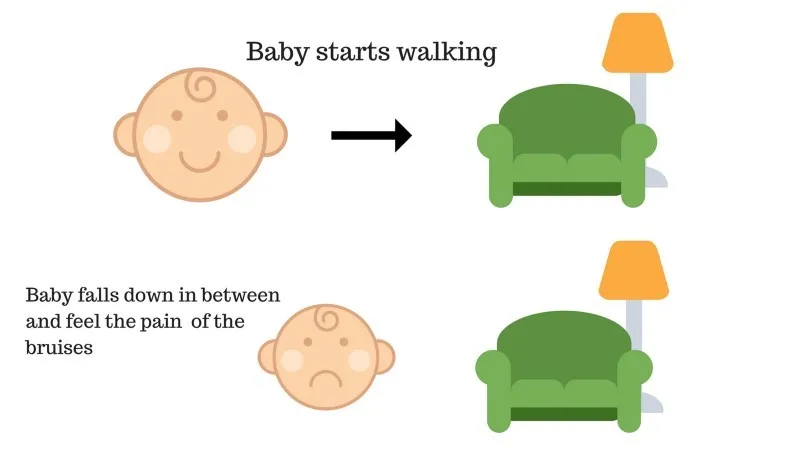
Дело №2
Бебето не успя да стигне до дивана и бебето е паднало. Боли! Каква евентуална причина? Възможно е да има някакви препятствия по пътя към дивана и бебето да е паднало на препятствия.
Резултат от случай 2: Бебето пада до някакви препятствия и плаче! О, това беше лошо, научи тя, а не следващия път да попадне в капана на препятствието. Избраният път сега идва с отрицателна награда.
Точки: Награди + (-n) → Отрицателна награда.
Източник: https://images.app.goo.gl/FRfd8cUqrQRLe6sZ7
Това вече видяхме случаи 1 и 2, обучението за подсилване всъщност прави същото, освен че не е човешко, а вместо това се извършва изчислително.
Използване на подсилване поетапно
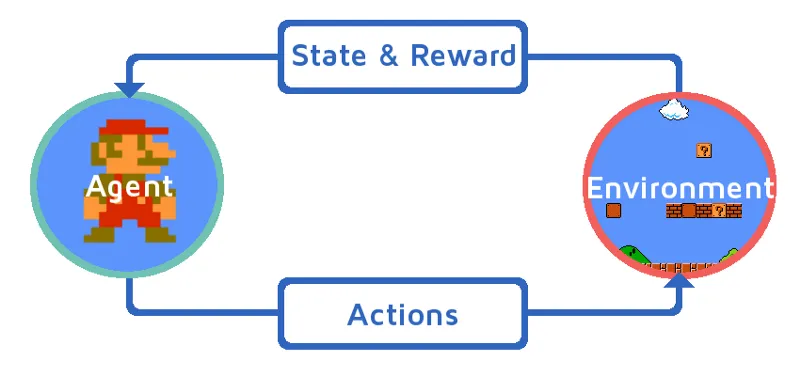
Нека да разберем обучението за подсилване, като постепенно приведем средство за подсилване. В този пример, нашият агент за обучение на подсилване е Марио, който ще се научи да играе сам:
Източник: https://images.app.goo.gl/Kj44uvBzWzMw1QzE9
- Текущото състояние на средата за игра на Mario е S_0. Защото играта все още не е започнала и Mario е на мястото си.
- След това играта се стартира и Mario се движи, Mario т.е. RL агент предприема и действа, да речем A_0.
- Сега състоянието на игровата среда стана S_1.
- Също така агентът на RL, т.е. Марио, сега е определен с положителна награда, R_1, вероятно защото Марио е все още жив и не е имало опасност.
Сега горният цикъл ще продължи да работи, докато Марио най-накрая е мъртъв или Марио достигне своята цел. Този модел непрекъснато ще извежда действието, наградата и състоянието.
Награди за максимизиране
Целта на засилването на обучението е да се увеличат максимално наградите, като се вземат предвид някои други фактори, като отстъпката за награди; накратко ще обясним какво се разбира под отстъпката с помощта на илюстрация.
Натрупаната формула за дисконтирани награди е:
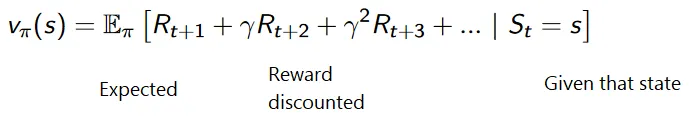
Награди с отстъпка
Нека разберем това чрез пример:
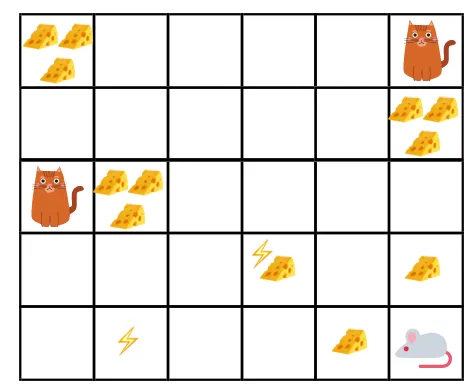
- В дадената фигура, целта е мишката в играта да изяде толкова сирене, преди да бъде изядена от котка или без да бъде електрошокована.
- Сега можем да предположим, че колкото по-близо сме до котката или електрическия капан, толкова по-голяма вероятност допускаме мишката да бъде изядена или шокирана.
- Това означава, че дори и да имаме пълното сирене близо до електрическия удар или близо до котката, толкова по-рисковано е да отидете там, по-добре е да ядете сиренето, което е наблизо, за да избегнете риск.
- И така, въпреки че имаме един „блок1“ сирене, който е пълен и е далеч от котката и електрическия удар и другия „блок2“, който също е пълен, но е близо до котка или електрически удар, по-късният блок сирене, т.е. „block2“, ще бъде намален с повече печалби от предишния.
Източник: https://images.app.goo.gl/8QrH78FjmRVs5Wxk8
Източник: https://cdn-images-1.medium.com/max/800/1*l8wl4hZvZAiLU56hT9vLlg.png.webp
Видове обучение за усилване
По-долу са описани двата вида обучение за подсилване с техните предимства и недостатъци:
1. Положителни
Когато силата и честотата на поведението се увеличават поради появата на някакво определено поведение, то е известно като Позитивно укрепване на обучението.
Предимства: Производителността е максимална и промяната остава за по-дълго време.
Недостатъци: Резултатите могат да бъдат намалени, ако имаме твърде много армировка.
2. Отрицателни
Това е засилването на поведението, най-вече заради отрицателния термин изчезва.
Предимства: Поведението е повишено.
Недостатъци: Само минималното поведение на модела може да се постигне с помощта на отрицателно обучение за подсилване.
Къде трябва да се използва армировъчното обучение?
Неща, които могат да се направят с армировъчно обучение / примери. Следват областите, в които днес се използва усилване на обучението:
- Здравеопазване
- образование
- Игри
- Компютърно зрение
- Управление на бизнес
- Роботика
- Финанси
- NLP (обработка на естествен език)
- транспорт
- Енергия
Кариери в обучението за подсилване
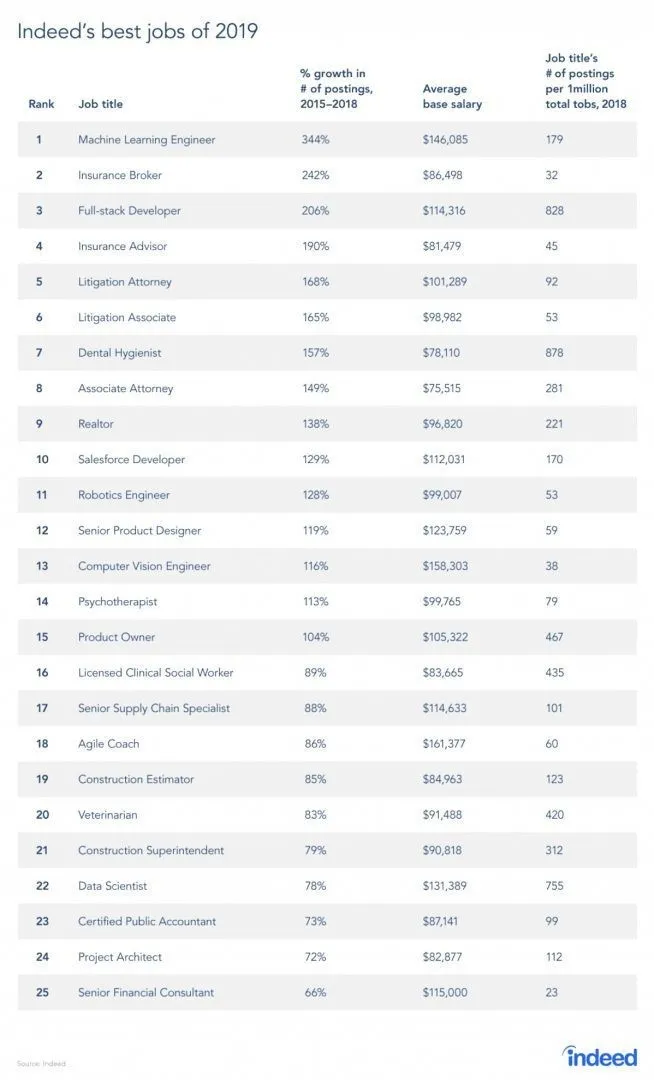
Наистина има доклад от сайта за работа, тъй като RL е клон на машинното обучение, според доклада, машинното обучение е най-добрата работа на 2019. По-долу е снимката на доклада. Според съвременните тенденции, машинно обучение инженери идва с огромна средна заплата от 146 085 долара и със темп на растеж от 344 процента.
Източник: https://i0.wp.com/www.artificialintelligence-news.com/wp-content/uploads/2019/03/indeed-top-jobs-2019-best.jpg.webp?w=654&ssl=1
Умения за укрепване на обучението
По-долу са описани уменията, необходими за обучението за подсилване:
1. Основни умения
- вероятност
- Статистика
- Моделиране на данни
2. Умения за програмиране
- Основи на програмирането и компютърните науки
- Дизайн на софтуер
- Възможност за прилагане на библиотеки и алгоритми за машинно обучение
3. Езици за машинно обучение на програмиране
- Питон
- R
- Въпреки че има и други езици, където могат да се проектират модели за машинно обучение като Java, C / C ++, но Python и R са най-предпочитаните езици.
заключение
В тази статия започнахме с кратко въведение за укрепване на обучението, след което се задълбочихме в работата на RL и различни фактори, които участват в работата на RL модели. Тогава бяхме поставили няколко примера от реалния свят, за да разберем още по-добре темата. В края на тази статия трябва да се разбере добре работата на обучението за подсилване.
Препоръчителни статии
Това е ръководство за Какво е усилване на обучението ?. Тук обсъждаме функцията и различните фактори, участващи в разработването на модели за усилване на обучението, с примери. Можете също да прегледате и другите ни свързани статии, за да научите повече -
- Видове алгоритми за машинно обучение
- Въведение в изкуствения интелект
- Инструменти за изкуствен интелект
- IoT платформа
- Топ 6 езика за програмиране на машинно обучение