

Въведение за присъединяване към Spark SQL
Както знаем, съединенията в SQL се използват за комбиниране на данни или редове от две или повече таблици въз основа на общо поле между тях. В тази тема ще научим за Join in Spark SQL Join in Spark SQL.
В Spark SQL, Dataframe или Dataset са таблична структура в паметта с редове и колони, които са разпределени в множество възли. Подобно на обикновените SQL таблици, ние също можем да извършваме операции за присъединяване на Dataframe или Dataset, налични в Spark SQL, въз основа на общо поле между тях.
В SQL има различни видове операции за присъединяване. В зависимост от случая на бизнес използване, ние избираме операцията за присъединяване. В следващия раздел ще демонстрираме всеки тип съединяване с пример.
Видове присъединяване в Spark SQL
Следват различните видове присъединения, налични в Spark SQL:
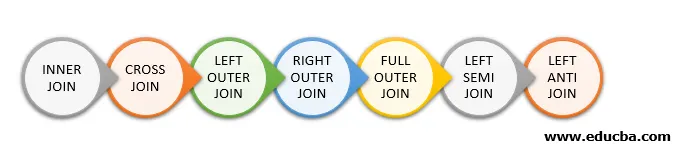
- ВЪТРЕШНО ПРИЛОЖЕТЕ
- КРЪСТО ПРИЛОЖЕТЕ
- НАЛЯВО ВЪЗСТАНОВЕТЕ
- ПРАВО ВЪНШЕН ПРИЛОЖЕТЕ
- ПЪЛНО ВЪНШНО ПРИЛОЖЕНИЕ
- ЛЯВО СЕМИ ПРИЛОЖЕТЕ
- НАЛЯВО АНТИ ПРИЛОЖЕТЕ
Пример за създаване на данни
Ще използваме следните данни, за да демонстрираме различните видове присъединения:
Набор данни от книги:
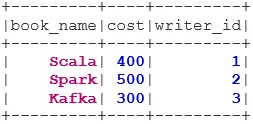
case class Book(book_name: String, cost: Int, writer_id:Int)
val bookDS = Seq(
Book("Scala", 400, 1),
Book("Spark", 500, 2),
Book("Kafka", 300, 3),
Book("Java", 350, 5)
).toDS()
bookDS.show()

Набор данни на Writer:
case class Writer(writer_name: String, writer_id:Int)
val writerDS = Seq(
Writer("Martin", 1),
Writer("Zaharia " 2),
Writer("Neha", 3),
Writer("James", 4)
).toDS()
writerDS.show()

Видове съединения
По-долу са споменати 7 различни типа Съединения:
1. ВЪТРЕШНО ПРИЛОЖЕНИЕ
INNER JOIN връща набора от данни, който има редовете, които имат съвпадащи стойности и в двата набора от данни, т.е. стойността на общото поле ще бъде една и съща.
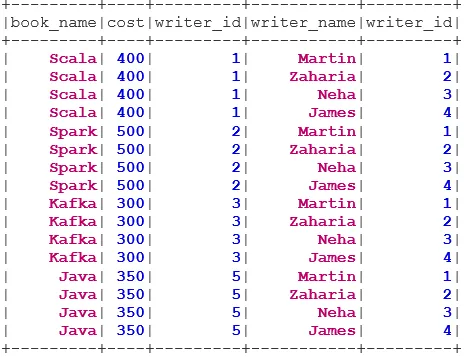
val BookWriterInner = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "inner")
BookWriterInner.show()

2. КРЪСТО ПРИЛОЖЕТЕ
CROSS JOIN връща набора от данни, който е броят редове в първия набор данни, умножен по броя на редовете във втория набор данни. Такъв резултат се нарича декартов продукт.
Предпоставка: За да използвате кръстосано съединение, spark.sql.crossJoin.enabled трябва да бъде зададено на true. В противен случай изключението ще бъде хвърлено.
spark.conf.set("spark.sql.crossJoin.enabled", true)
val BookWriterCross = bookDS.join(writerDS)
BookWriterCross.show()
3. НАЛЯВАНЕ НА ЛЯВО ИЗВЪН
LEFT OUTER JOIN връща набора от данни, който има всички редове от левия набор от данни, и съвпадащите редове от десния набор от данни.
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter")
BookWriterLeft.show()

4. ПРАВО ВЪНШНО ПРИЛОЖЕНИЕ
RIGHT OUTER JOIN връща набора от данни, който има всички редове от десния набор данни, и съвпадащите редове от левия набор от данни.
val BookWriterRight = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "rightouter")
BookWriterRight.show()

5. ПЪЛНО ВЪНШНО ПРИЛОЖЕНИЕ
FULL OUTER JOIN връща набора от данни, който има всички редове, когато има съвпадение в левия или десния набор от данни.
val BookWriterFull = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "fullouter")
BookWriterFull.show()

6. ЛЯВО СЕМИ ПРИЛУЧАЙТЕ
LEFT SEMI JOIN връща набора от данни, който има всички редове от левия набор данни, като кореспонденцията им е в десния набор от данни. За разлика от LEFT OUTER JOIN, върнатият набор от данни в LEFT SEMI JOIN съдържа само колоните от левия набор от данни.
val BookWriterLeftSemi = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftsemi")
BookWriterLeftSemi.show()
7. ЛЯВО АНТИ ПРИЛОЖЕТЕ
ANTI SEMI JOIN връща набора от данни, който има всички редове от левия набор от данни, които не съвпадат в десния набор от данни. Той също така съдържа само колоните от левия набор от данни.
val BookWriterLeftAnti = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftanti")
BookWriterLeftAnti.show()

Заключение - Присъединете се към Spark SQL
Данните за присъединяване са една от най-често срещаните и важни операции за изпълнение на нашия случай на бизнес използване. Spark SQL поддържа всички основни типове присъединения. Докато се присъединяваме, трябва да обмислим и производителността, тъй като те могат да изискват големи мрежови трансфери или дори да създават набори от данни извън възможностите ни да се справим. За подобряване на производителността Spark използва SQL оптимизатор, за да пренарежда или натиска филтри. Искрите също ограничават опасното съединение i. e CROSS ПРИЛУЧАЙТЕ. За да използвате кръстосано съединение, spark.sql.crossJoin.enabled трябва да бъде зададено изрично истина.
Препоръчителни статии
Това е ръководство за присъединяване в Spark SQL. Тук обсъждаме различните видове присъединения, налични в Spark SQL с примера. Можете също да разгледате следната статия.
- Видове съединения в SQL
- Таблица в SQL
- SQL Insert Query
- Транзакции в SQL
- PHP филтри | Как да потвърдите въвеждането на потребител с различни филтри?