
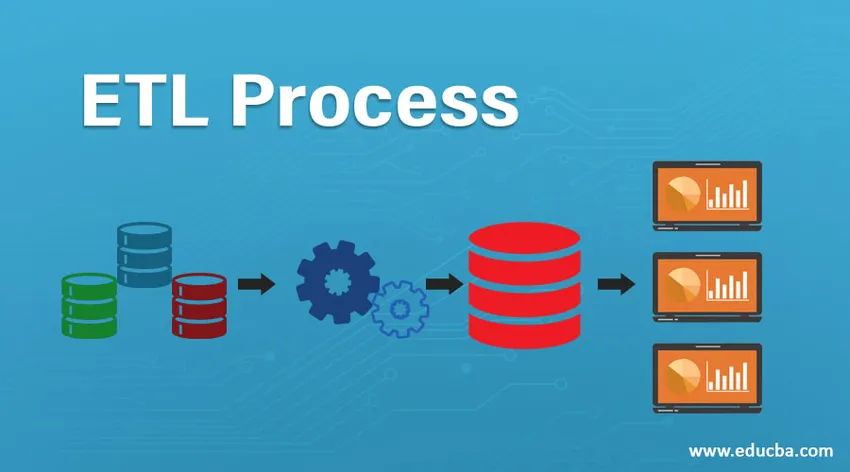
Въвеждане на ETL процеса
ETL е един от важните процеси, изисквани от Business Intelligence. Business Intelligence разчита на данните, съхранявани в хранилищата на данни, от които се генерират много анализи и отчети, което помага за изграждането на по-ефективни стратегии и води до тактически и оперативни прозрения и вземане на решения.
ETL се отнася до процеса на извличане, трансформиране и зареждане. Това е един вид стъпка за интегриране на данни, при който данните, идващи от различни източници, се извличат и изпращат до хранилища на данни. Данните се извличат от различни ресурси, първо се трансформират, за да ги преобразуват в определен формат според бизнес изискванията. Различни инструменти, които помагат за изпълнение на тези задачи са -
- IBM DataStage
- Abinitio
- Informatica
- жива картина
- Talend
ETL процес
Как работи?
Процесът ETL е процес в 3 стъпки, който започва с извличане на данните от различни източници на данни и след това суровите данни претърпяват различни трансформации, за да бъдат подходящи за съхранение в хранилището на данни и да го заредят в хранилища с данни в необходимия формат и да го подготвят за анализ.
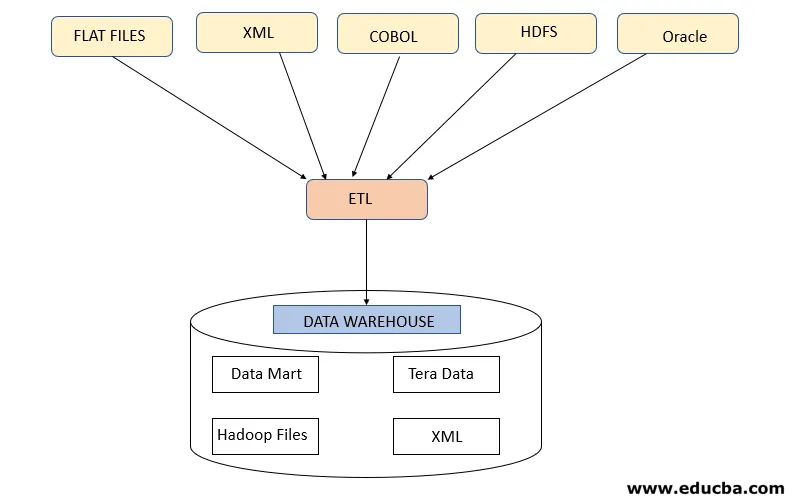
Стъпка 1: Екстракт
Тази стъпка се отнася до извличане на необходимите данни от различни източници, които присъстват в различни формати като XML, Hadoop файлове, плоски файлове, JSON и др. Извлечените данни се съхраняват в зоната на поставяне, където се извършват допълнителни трансформации. По този начин данните се проверяват старателно, преди да бъдат преместени в складове с данни, в противен случай ще се превърне в предизвикателство за възстановяване на промените в складовете с данни.
Необходима е подходяща карта с данни между източник и цел преди да се получи извличане на данни, тъй като процесът на ETL трябва да взаимодейства с различни системи като Oracle, хардуер, мейнфрейм, системи в реално време като ATM, Hadoop и др., Докато извлича данни от тези системи,
Забележка - Но трябва да се внимава, че тези системи трябва да останат незасегнати по време на извличане.
Стратегии за извличане на данни
- Пълно извличане: Това се следва, когато цели данни от източници се зареждат в хранилищата с данни, които показват, че или складът от данни се попълва за първи път или не е направена стратегия за извличане на данни.
- Частично извличане (с известие за актуализация): Тази стратегия е известна и делта, при която се извличат само променените данни и се актуализират складовете с данни
- Частично извличане (без уведомяване за актуализация): Тази стратегия се отнася до извличане на специфични изискуеми данни от източници според натоварването в складовете с данни, вместо извличане на цели данни.
Стъпка 2: Трансформирайте
Тази стъпка е най-важната стъпка на ETL. В тази стъпка се извършват много трансформации, за да се подготвят данните за натоварване в складовете с данни, като се прилагат трансформации по-долу: -
А. Основни трансформации: Тези трансформации се прилагат във всеки сценарий, тъй като са основна нужда, докато зареждат данните, извлечени от различни източници, в хранилищата с данни
- Почистване или обогатяване на данни: Отнася се за почистване на нежеланите данни от зоната за поставяне, за да не се заредят грешни данни от складовете с данни.
- Филтриране: Тук филтрираме необходимите данни от голямо количество от наличните данни според бизнес изискванията. Например, за генериране на отчети за продажбите човек се нуждае само от записи за продажбите за конкретната година.
- Консолидация: Извлечените данни се консолидират в необходимия формат, преди да се заредят в складовете с данни.4.
- Стандартизация: Полетата от данни се трансформират, за да ги приведат в същия необходим формат, например, полето за данни трябва да бъде посочено като MM / DD / ГГГГ.
Б. Разширени трансформации: Тези видове трансформации са специфични за бизнес изискванията.
- Присъединяване: В тази операция данните от 2 или повече източника се комбинират, като генерират данни само с желани колони с редове, които са свързани помежду си.
- Проверка на прага на валидност на данните: Стойностите, присъстващи в различни полета, се проверяват дали са верни или не, като например ненулен номер на банкова сметка в случай на банкови данни.
- Използвайте търсене за сливане на данни: За извличане на конкретната информация се използват различни плоски файлове или други файлове, като се извършва операция за търсене на това.
- Използване на всяка сложна проверка на данни: Много сложни валидации се прилагат за извличане на валидни данни само от изходните системи.
- Изчислени и получени стойности: За изчисляване на данните в някаква необходима информация се прилагат различни изчисления
- Дублиране: Дублиращите се данни, идващи от изходните системи, се анализират и премахват, преди да се заредят в складовете с данни.
- Преструктуриране на ключове: В случай на заснемане на бавно променящи се данни, трябва да се генерират различни сурогатни ключове, които да структурират данните в необходимия формат.
Забележка - MPP-Massive паралелна обработка се използва понякога за извършване на някои основни операции, като филтриране или почистване на данни в зоната на етап, за да се обработва по-бързо голям обем данни.
Стъпка 3: Заредете
Тази стъпка се отнася до зареждане на трансформираните данни в хранилището с данни, откъдето те могат да бъдат използвани за генериране на много аналитични решения, както и за отчитане.
1. Първоначално натоварване: Този тип натоварване се появява при зареждане на данни в хранилища за данни за първи път.
2. Нарастване на натоварването: Това е типът натоварване, който се прави, за да се актуализира периодично складът на данни с промени, възникващи в данните на изходната система.
3. Пълно опресняване: Този тип натоварване се отнася до ситуацията, когато пълните данни на таблицата се изтрият и зареждат със свежи данни.
След това складът на данни позволява функции OLAP или OLTP.
Недостатъци на ETL Process
- Увеличаване на данните - Има ограничение на данните да бъдат извлечени от различни източници с помощта на инструмента ETL и да бъдат преместени в складовете за данни. По този начин с увеличаването на данните работата с инструмента ETL и складовете за данни стават тромави.
- Персонализиране - Това се отнася до бързите и ефективни решения или отговори на данните, генерирани от източници на системи. Но използването на инструмента ETL тук забавя този процес.
- Скъпо - Използването на склад за данни за съхраняване на все по-голямо количество данни, които се генерират периодично, е висока цена, която организацията трябва да плати.
Заключение - ETL процес
Инструментът ETL се състои от процеси за извличане, трансформиране и зареждане, където помага да се генерира информация от данните, събрани от различни източници. Данните от изходната система могат да се предлагат във всякакви формати и могат да бъдат зареждани във всеки желан формат в складовете за данни, като по този начин инструментът ETL трябва да поддържа свързаност към всички видове тези формати.
Препоръчителни статии
Това е ръководство за ETL процес. Тук обсъждаме въвеждането, Как работи ?, ETL Tools и неговите недостатъци. Можете също да прегледате и другите ни предложени статии, за да научите повече -
- Инструменти ETL Инструменти
- ETL инструменти за тестване
- Какво е ETL?
- Какво е ETL тестване?